文章出处:http://www.cnblogs.com/haozhengfei/p/e353daff460b01a5be13688fe1f8c952.html
Spark_总结五
1.Storm 和 SparkStreaming区别
| Storm | 纯实时的流式处理,来一条数据就立即进行处理 |
| SparkStreaming | 微批处理,每次处理的都是一批非常小的数据 |
| Storm支持动态调整并行度(动态的资源分配),SparkStreaming(粗粒度, 比较消耗资源) | |
Storm 优点 || 缺点
Storm 流式计算(扶梯)
优点:数据延迟度很低,Storm的事务机制要比SparkStreaming的事务机制要完善(什么是事务机制?对于一条数据,不多处理也不少处理,对于一条数据恰好处理一次,比如金融,股票等要求实时性比较高,那么就需要选Storm)
缺点:一直持有着资源,每一条数据都要在集群中某一台节点处理,要计算的数据会进行网络传输,吞吐量小,另外Storm不适合做复杂的业务逻辑(适合汇总)
SparkStreaming 优点 || 缺点
SparkStreaming 微批处理(类似于电梯),它并不是纯的批处理
优点:吞吐量大,可以做复杂的业务逻辑(保证每个job的处理小于batch interval)
缺点:数据延迟度较高
公司中为什么选用SparkStreaming要多一些?
1.秒级别延迟,通常应用程序是可以接受的,
2.可以应用机器学习,SparkSQL...可扩展性比较好,数据吞吐量较高
2.SparkStreaming
2.1什么是SparkStreaming?
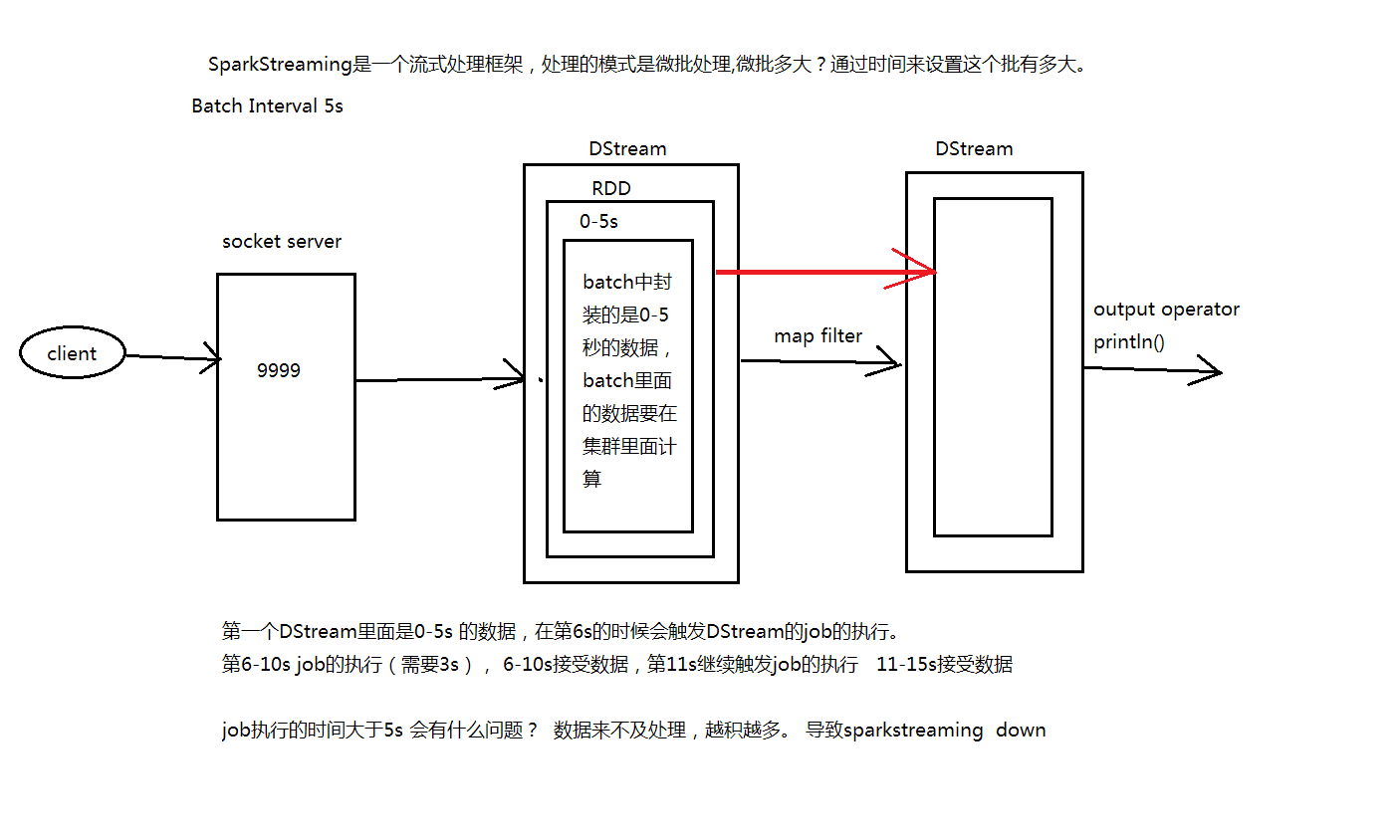
SparkStreaming是一个流式处理框架,处理的模式是微批处理(微批有多大?通过时间来设置这个批有多大[For example:Batch Interval 5s])
SparkStreaming基于DStream(Discretized Streams:离散的数据流)来进行编程,处理的是一个流,这个流什么时候切成一个rdd-->根据batchinterval来决定何时切割成一个RDD。
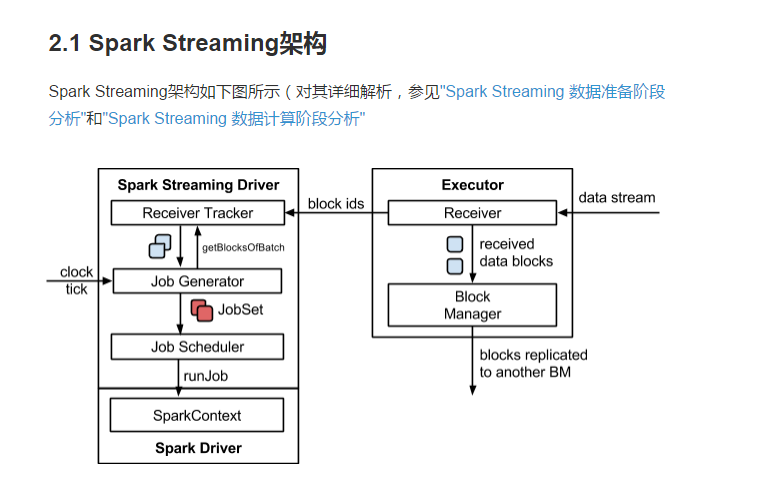
SparkStreaming 架构图
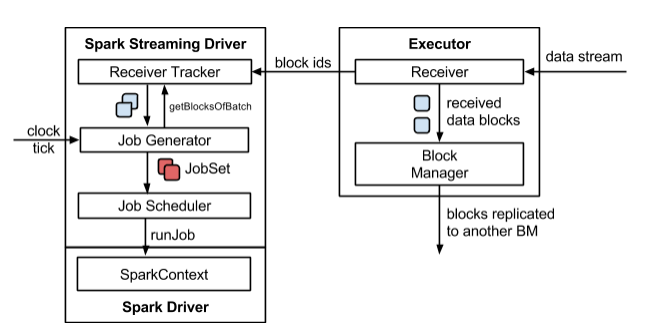
job的个数是由output operator决定的,StreamContext底层封装了SparkContext
2.2图解SparkStreaming || SparkStreaming执行流程
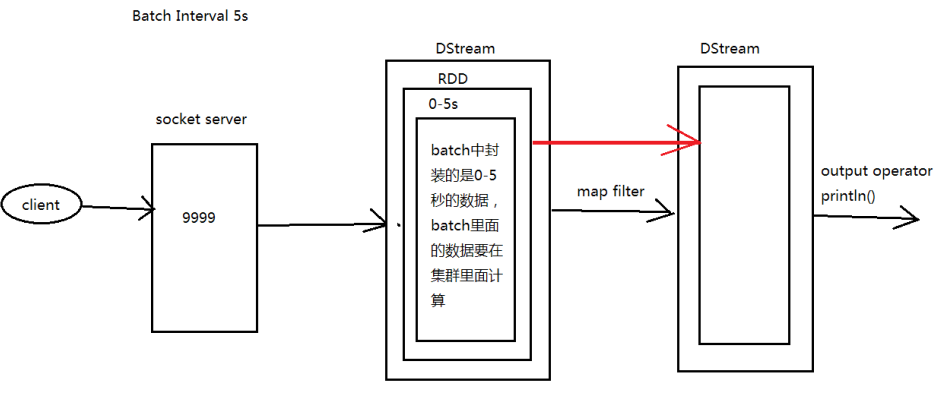
从图上可以看到,Batch Interval的间隔是5s,也就是说每经过5s,SparkStreaming会将这5s内的信息封装成一个DStream,然后提交到Spark集群进行计算
执行流程
第一个 DStream 里面是 0-5s 的数据,在第6s的时候会触发 DStream 的job执行,这时会另启动一个线程执行这个job(假设这个job只需要3s),同时在6-10s期间继续接受数据,在第11s的时候会触发 DStream 的job的执行,这时会另启动一个线程执行这个job(假设这个job只需要3s),同时在11-15s期间继续接受数据...
注意!
如果这个job执行的时间大于5s会有什么问题?
数据在5s内处理不完,又启动一个job,导致数据越积越多,从而导致 SparkStreaming down
2.3SparkStreaming代码TransformOperator
案例:过滤黑名单
这里模拟了一份黑名单,SparkStreaming监控服务器中指定端口,时间设定为每5秒处理一次数据。每当job触发时,用户输入的数据与黑名单中的数据进行左外连接,然后过滤
node1 创建一个Socket Server
nc -lk 8888 (页面停下了,开始输入数据进入8888端口,此时SparkStreaming监听这个端口)
hello world
hello jack
hello tom(过滤tom)
result:
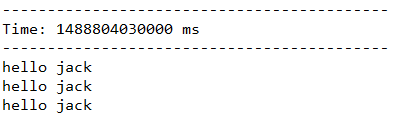
注意事项!
1.为什么会没有数据?
因为只开启了一条线程(这里只有接收数据的线程),所以local的模拟SparkStreaming必须至少设置两个线程,new SparkConf().setMaster("local[2]").setAppName("TransformBlacklist");
2.Durations时间的设置--接收数据的延迟时间,多久触发一次job
final JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
3.创建JavaStreamingContext有两种方式(sparkconf、sparkcontext)
4.业务逻辑完成后,需要有一个output operator,将SparkStreaming处理后的数据输出(HDFS,DBMS)
5.关于 JavaStreamingContext 的 start() || stop()
JavaStreamingContext.start() //straming框架启动之后是不能再添加业务逻辑
JavaStreamingContext.stop() //无参的stop方法会将sparkContext一同关闭,解决办法:stop(false)
JavaStreamingContext.stop() //停止之后是不能在调用start()
6.DStreams(Discretized Streams--离散的流),应用在每个DStream的算子操作,应用在RDD,应用在Partition,应用在Partition中的一条条数据,所以最终应用到每一条记录上
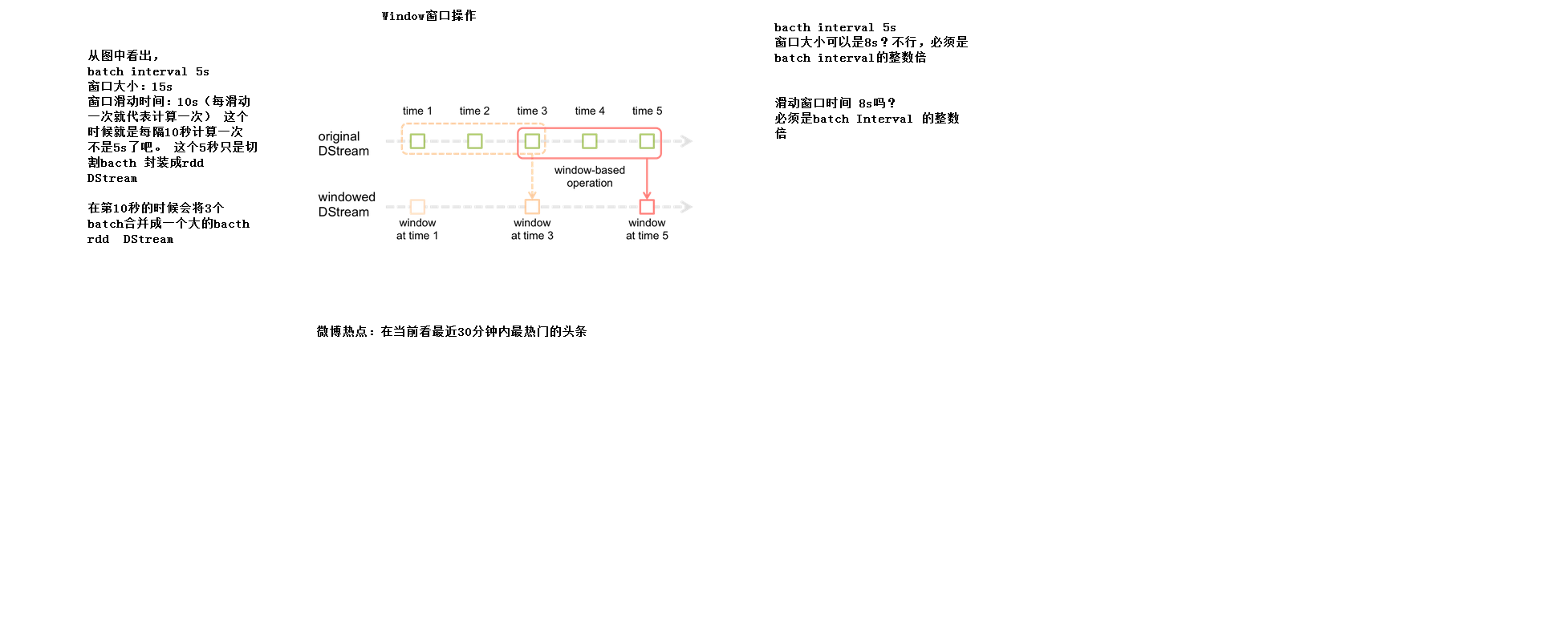
2.4Window窗口操作
window operation
普通的 每隔多长时间切割RDD
基于窗口的操作:每隔多长时间切割RDD,每隔多长时间计算一次,每次计算的量是多少
为什么需要有窗口操作?
比如别人要求能够实时看到此刻之前一段时间的数据情况,如果使用批处理的话,那么我们只能固定一个整段时间然后对这个整段时间进行spark core的计算,但是别人的要求是每一个时刻都需要有结果,那么就需要窗口操作?但是窗口操作肯定会有很多的重复计算,这里有一个优化的地方(这个优化也不是必须的,视具体情况而定,比如说我们要查看最近30分钟最热门的头条,我们在设计的时候不可能每隔30分钟计算一次,这里定义了滑动窗口时间是1分钟,然而计算量是30分钟内的数据,那么肯定会有29分钟重复的数据计算);但是优化的话就会有一个前提,必须要checkpoint
每次计算都是最近15s的数据,基于这个特性(微博热点:最近30分钟内最热门的头条)
问题一:batch interval 5s,窗口大小可以是8s么?
不行,有的batch就不能被窗口所包含,必须是batch interval的整数倍
问题二:滑动窗口时间 8s 可以么?
必须是batch interval的整数倍
优化:如何避免time3被重复计算(图中time3在两个window中都被计算了),可以没有,但是有的话,就需要这种优化
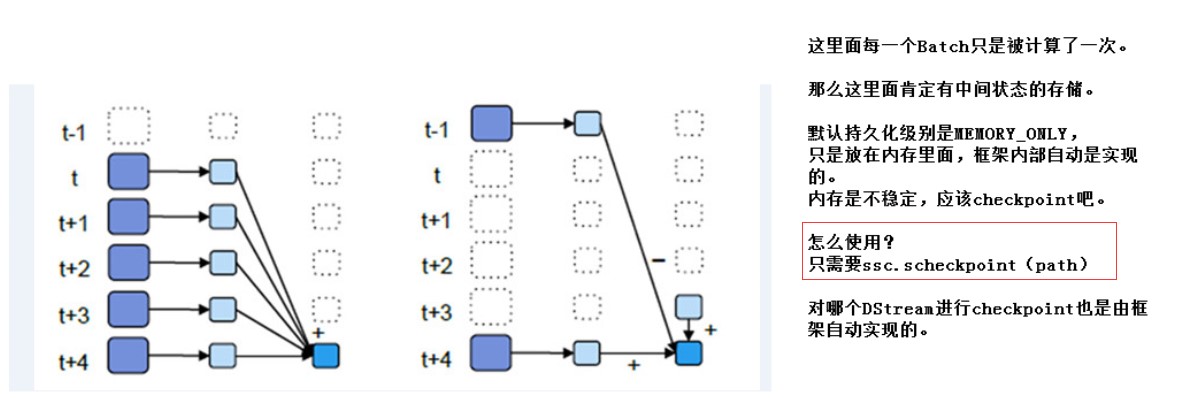
Batch Interval 1s || 窗口大小 5s || 滑动窗口 1s
思考:计算一个趋势的时候,需要基于滑动窗口的操作,是否必须要优化,避免重复计算?(未必)
For example:
1.查看微博中每小时的热门微博,每隔1分钟计算一次,相当于重复计算了59分钟的内容
2.商家想看前5分钟的销售额,每隔30秒看一次,也需要基于窗口的操作
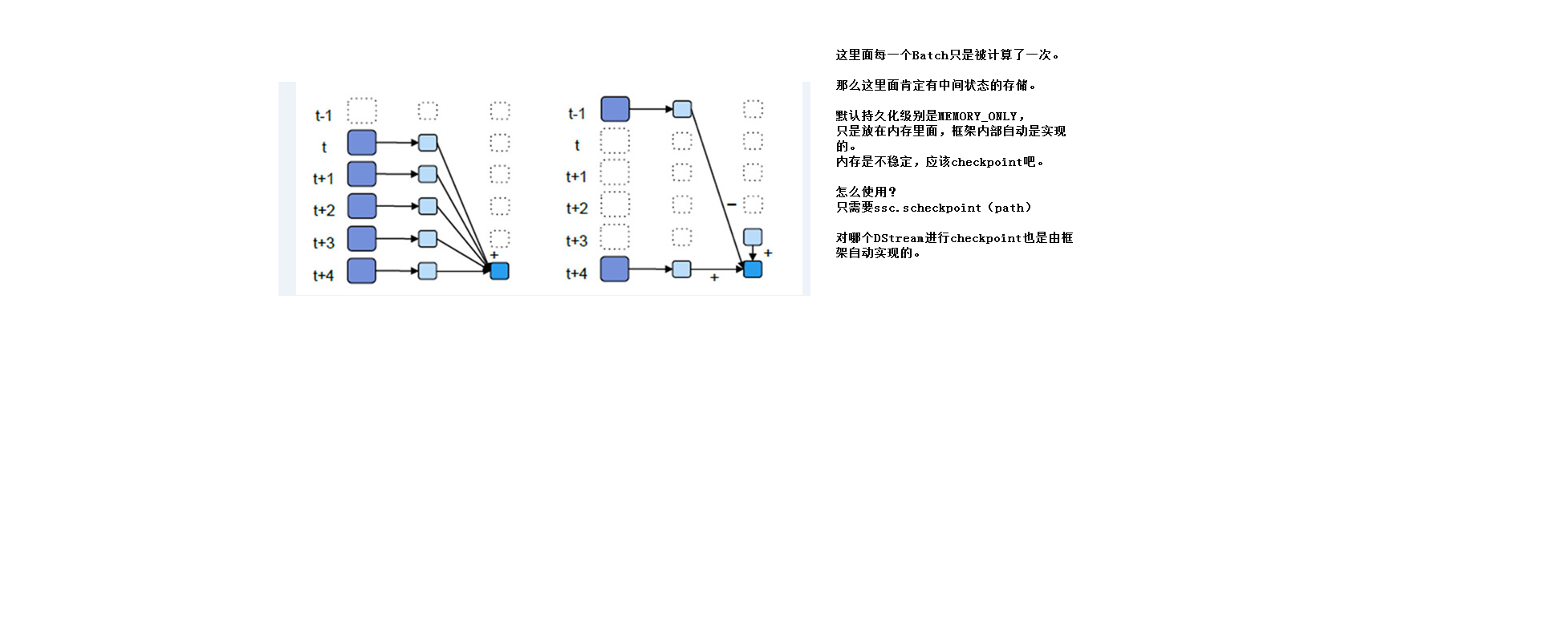
2.5UpdateStateByKey
updateStateByKey的使用需要checkpoint,隔几次记录一次到磁盘中
UpdateStateByKey的主要功能
1、Spark Streaming中为每一个Key维护一份state状态,这个state类型可以是任意类型的的, 可以是一个自定义的对象,那么更新函数也可以是任意类型的。
2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新(对于每个新出现的key,会同样的执行state的更新函数操作)
3、如果要不断的更新每个key的state,就涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能 ( one.checkpoint(Durations.seconds(10)) //容错更好就需要牺牲性能,容错不需要太高,时间可以设置的长一些,(比如这里将checkpoint设置为10s,也就是每隔10s会将标记有checkpoint的RDD计算的结果持久化到磁盘,如果我们设置的Batch Interval = 5s, 在第15s时触发job进行计算, 但是在第17s时down, 这时候只能恢复到10s的数据,那么10s至17s的数据就丢失了,具体设置多少,视具体情况而定))
UpdateStateByKey用处:统计广告点击流量,统计这一天的车流量...
案例:全面的广告点击分析UpdateStateByKeyOperator
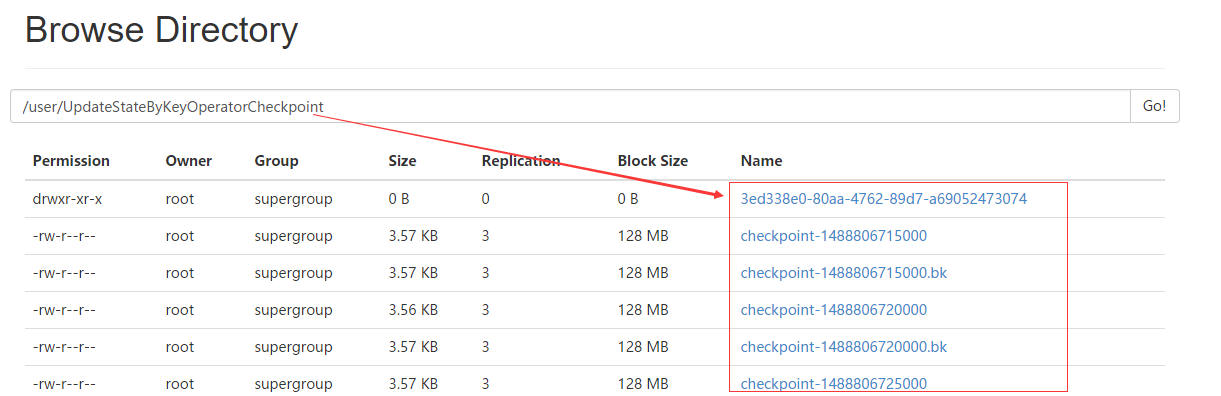
这里做了checkpoint操作,jsc.checkpoint("hdfs://ndoe1:8020/user/sscheckpoint");
node1创建一个Socket Server,指定8888端口,SparkStreaming与服务器这个端口建立通信,那么用户的数据从这里流向SparkStreaming进行计算。
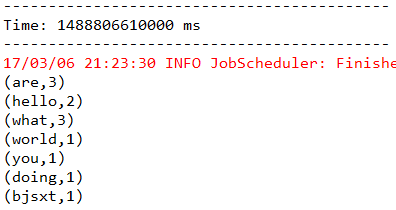
在这个案例中,用以空格分割的单词来模拟用户点击的广告,每个单词代表一个广告,统计每一个广告(单词)出现的次数(就是WordCount)
最后的conunts.print() //output operator类型的算子

result: 利用SparkStreaming做到了微批处理,近似实时计算

查看hdfs,发现设置checkpoint会将SparkStreaming的处理结果进行了持久化
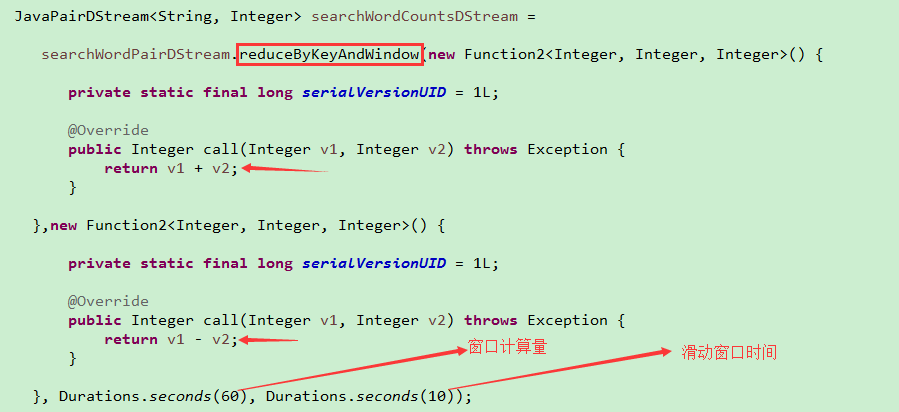
2.6reduceByKeyAndWindow
基于滑动窗口的热点搜索词实时统计--WindowOperator
1.未优化的
2.优化的必须要设置checkpoint的目录
以下是优化的过的reduceByKeyAndWindow
补充:
1.Spark master 8080端口 监控资源
Drive 4040端口 监控任务,可以看到有一个Streaming job(它里面有一个线程,是一直运行的,负责接收我们的数据)
2.transform 和 foreachRDD 的区别?
transform Transformation类型算子,transform非常厉害,可以拿到每一个DStream的rdd;这样就可以利用每一个rdd的所有算子来转换;甚至在里面应用spark core,或者将rdd转换成DataFrame来使用SparkSQL操作
foreachRDD Action类型算子,对于每个RDD进行操作,什么时候会用?最后存结果的时候会用
3.transform取出DStream中的RDD
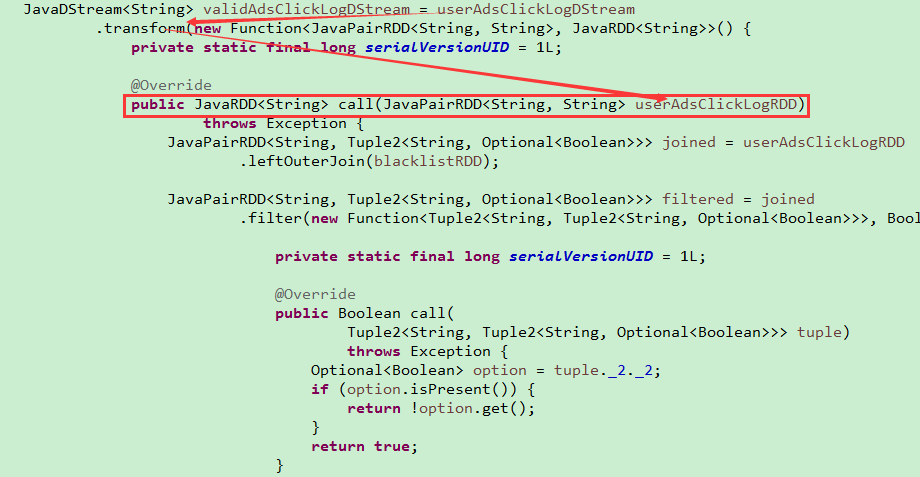
使用transform将DStream中的RDD抽取出来,调用了RDD的Action类的算子(是可以执行的)是在Driver端执行的,如果不在Driver端执行,调用Action类的算子就不会触发一个job了
对RDD的操作才会发送到Executor端执行,transform是对DStream进行操作(transform中抽取RDD,对这个RDD执行collect类型的数据,在job Generator时执行的,生成了多个job,以jobSet的形式发送给jobSecheduler),这样的话就可以预警:对数据的预警,与标准进行比较,如果超过了这个标准就进行报警(一旦发现某个黑名单就立即进行报警,),整体的代码是在Driver端执行的,但是部分代码对RDD的操作是在Executor段执行的
SparkContext sc = userClickRDD.context();
Object obj = "可以来源于数据库,动态的更改广播变量"
sc.broadCast(obj)
2.6SparkStreaming--Driver HA
2.6.1Driver也有可能挂掉,如何实现它的高可用?
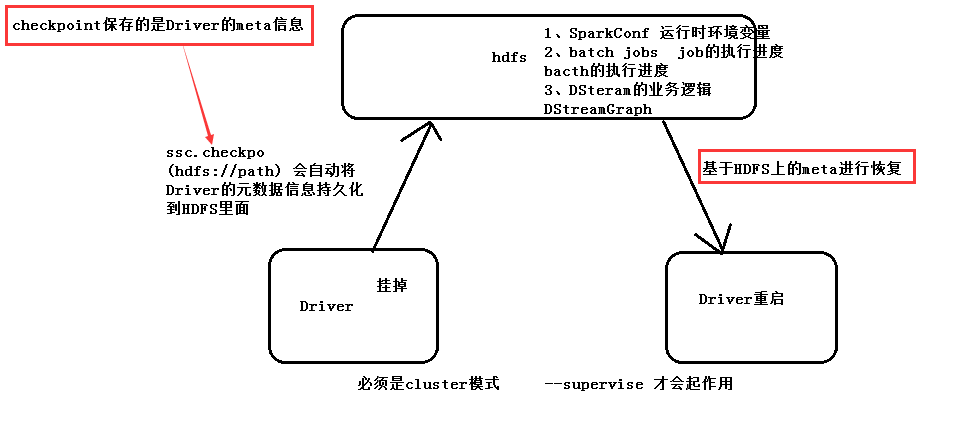
当一个Driver挂掉后,(回忆:当初的Master是由zookeeper进行托管),另外启动一个Driver,它就需要从上一个Driver中获得相关的信息(包括batch的进度,data的位置,job执行进度,DStream的Graph(基于DStream的业务逻辑))
如何实现Driver的高可用-->基于HDFS上面的元数据(Driver的信息)进行恢复,注意!不会重新new SparkContext,因为这样相当于又创建了一个全新的Driver
2.6.2Driver HA的代码套路
1.指定了去哪一个目录下面寻找Driver的元数据信息
2.提交Application到集群中执行的时候,必须使用cluster模式,同时必须指定一个参数 --supervise(当某一个Driver挂掉,新的Driver需要另一个Driver中的信息来继续job的执行)
2.6.3监控HDFS上指定目录下文件数量的变化
示例代码SparkStreamingOnHDFS
1.为了状态的保存和容错,开启了checkpoint机制,Driver HA
2.ssc.textFileStream("hdfs://node1:8020/userhdfs/") //监控hdfs上/user/hdfs的变化
命令:hadoop fs -put wc /user/hdfs
2.6.4SparkStreaming 监控 HDFS 上文件数量的变化,并将变化写入到MySql中
示例代码SparkStreamingOnHDFSToMySQL
1.为了状态的保存和容错,开启了checkpoint机制,Driver HA
2.ssc.textFileStream("hdfs://node1:8020/userhdfs/") //监控hdfs上/user/hdfs的变化
3.Kafka
3.1Kafka定义
Apache Kafka是一个高吞吐的集发布与订阅与一体的分布式消息系统
流式处理的数据源是kafka,批处理的数据源是hive,也就是hdfs;
3.2消息队列常见的场景
1.系统之间的解耦合
-queue模型
-publish-subscribe模型
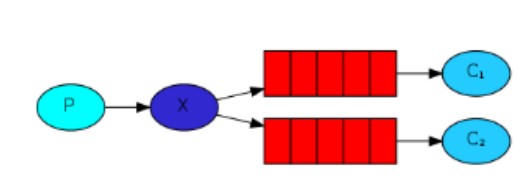
2.峰值压力缓冲,如果高峰期日志大量到SparkSreaming,那么会造成计算时间超过BatchInterval),可以在日志服务器和SparkStreaming中间加入Kafka,起到缓冲的作用
3.异步通信

3.3Kafka的架构
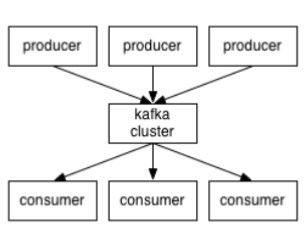

消费者的消费偏移量存储在zookeeper中,生产者生产数据,消费者消费数据,kafka并不会生产数据,但kafka默认一周删除一次数据。
broker就是代理,在kafka cluster这一层这里,其实里面是有很多个broker
topic就相当于Queue,Queue里面有生产者消费者模型
3.4Kafka的消息存储和生产消费模型

topic:一个kafka集群中可以划分n多的topic,一个topic可以分成多个partition(这个是为了做并行的), 每个partition内部消息强有序,其中的每个消息都有一个序号叫offset,一个partition对应一个broker,一个broker可以管多个partition,这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念
生产者自己决定往哪个partition写消息(轮循的负载均衡或者是基于hash的partition策略)
消费者可以订阅某一个topic,这个topic一旦有数据,会将数据推送给消费者
3.5kafka 组内queue消费模型 || 组间publish-subscribe消费模型
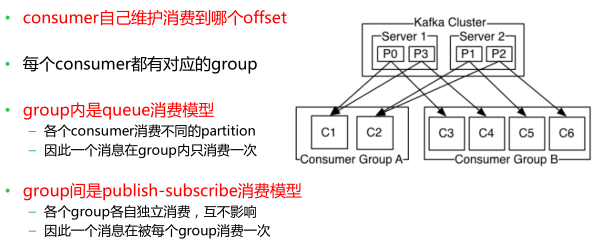
3.6kafka有哪些特点

3.7为什么Kafka的吞吐量高?
3.7.1 什么是Zero Copy?
零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式
3.7.2 kafka采用零拷贝Zero Copy的方式
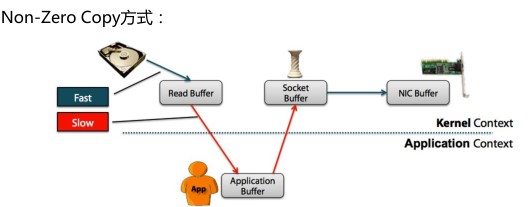
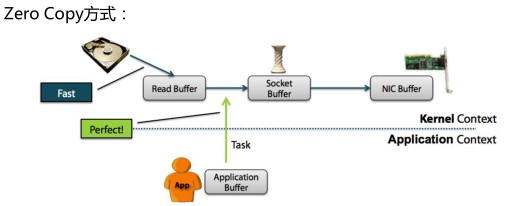
从上图中可以清楚的看到,Zero Copy的模式中,避免了数据在内存空间和用户空间之间的拷贝,从而提高了系统的整体性能。Linux中的sendfile()以及Java NIO中
的FileChannel.transferTo()方法都实现了零拷贝的功能,而在Netty中也通过在
FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝
3.8搭建Kafka集群--leader的均衡机制


Kafka中leader的均衡机制
Kafka中一个topic有多个partition,如上图,kfk有0,1,2共三个partition,每个partition都有对应的leader来进行管理,对于leader1来说它来管理partition0,当leader1挂掉之后,因为partition0配置了副本数(在broker0,broker2还存在partition0的副本),那么此时会在broker0,broker2上选出一台当做leader继续管理partition0(比如说选取了broker2当做partition0的leader),这时候如果我们配置了leader均衡机制,重新恢复了broker1,那么partition0的leader就会从broker2转移到broker1,减轻了broker2的读取压力,实现了负载均衡。当然如果不开启leader均衡机制的话,重新恢复broker1,那么partition0的leader仍就是broker2。
Kafka中leader的均衡机制在哪里配置?

在server.properties添加如下一句话
auto.leader.rebalance.enable=true
3.9Kafka_code注意事项
注意一:
向kafka中写数据的时候我们必须要指定所配置kafka的所有brokers节点,而不能只配置一个节点,因为我们写的话,是不知道这个topic最终存放在什么地方,所以必须指定全,
读取Kafka中的数据的时候是需要指定zk的节点,只需要指定一个节点就可以了;目前我们使用的在代码中直接写上这些节点,以后全部要写到配置文件中
注意二:
kafka中存储的是键值对,即使我们没有明确些出来key,获取的时候也是需要利用tuple的方式获取值的;而对于放到一个kafka中的数据,这个数据到底存放到那个partition中呢?这个就需要使用hashPartition方式或者普通的轮询方式存放;对于没有明确指定key的发往kafka的数据,使用的就是轮询方式;
4.SparkStreaming + Kafka 两种模式--Receive模式 || Direct模式
Receive模式--SparkStreaming + Kafka 整体架构
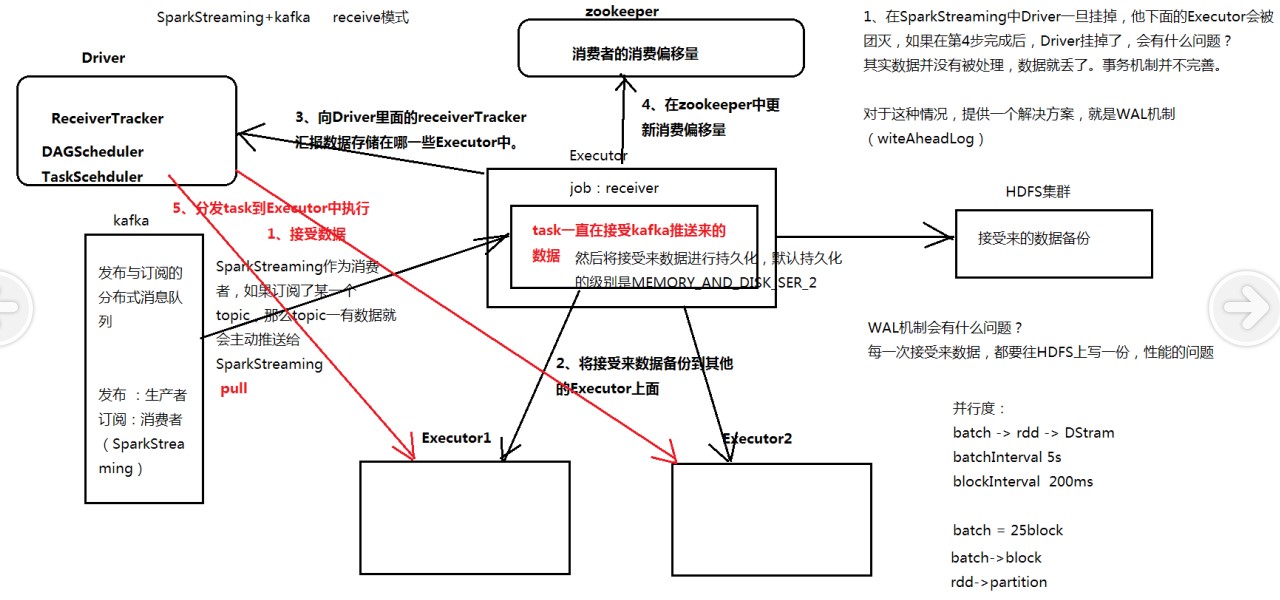
注意!每一步都是阻塞的,上一步完成之后才能进行下一步
流程:
1.接收数据(SparkStreaming作为消费者,如果订阅了一个topic,那么topic一有数据就会主动推送给SparkSreaming)
2.Executor将接收来的数据备份到其他Executor中(Executor中执行的job作为一个receiver,里面的task一直在接收kafka推送来的数据,然后将接收来的数据进行持久化,默认的持久化级别是MEMORY_DISK_SER_2)
3.Executor备份完成之后,向Driver中的ReceiverTracker汇报数据存储在哪一些的Executor中(Driver{ReceiverTracker,DAGScheduler,TaskScheduler})
4.在zookeeper中更新消费偏移量
5.Driver负责分发task到数据所在的Executor中执行(达到移动计算,而不是移动数据)
注意!
1.在SparkStreaming中Driver一旦挂掉,它下面的Executor也会挂掉
如果在第四步完成后,Driver挂掉了,会有什么问题?
其实数据并没有被处理,数据就丢了,因此kafka的事务机制并不完善
因此对于如上这种情况,提供了一个解决方案,就是WAL机制(WriteAheadLog--预写机制)
但是WAL机制有什么问题?(每一次接收来的数据,都要往HDFS上写一份,性能会有所下降)
代码示例
SparkStreamingOnKafkaReceiver
SparkStreamingDataManuallyProducerForKafka
需要启动HDFS
Direct模式
SparkStreaming和Kafka直接连接,SparkStreaming去Kafka去pull数据,这个消费偏移量由SparkStreaming自己来维护(实际上通过checkpoint来管理的,checkpoint和job是异步的,总的来时SparkStreaming的事务机制并不是很完善),避免了数据的丢失(相对而言,不是绝对的)
并行度:
1.linesDStream里面封装的是RDD,RDD里面有partition,RDD里面的partition与这个topic的partition是一一对应的
2.从kafka中读来的数据,封装到一个DStream中,可以对这个DStream重分区,lines.repartition(10),增加partition的数量,提高并行度。
并行度:
batch->rdd->DStream
batchInterval 5s
blockInterval = 200ms
batch = 25block
将一个blockInterval设置的小一些,有更多的block,对应更多的split,也就有更多的partition,从而提高并行度
官方建议:blockInterval不要低于50ms,否则batchInterval/blockInterval 得到的block过多,partition就过多,启动多个线程并行计算,影响执行job的性能
Receive模式 || Direct模式 最大的不同:消费偏移量谁来管理
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}