作业一
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
代码部分
items.py
`
import scrapy
class DdbooksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
`
pipelines.py
`
import pymysql
class DdbooksPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute(
"insert into books(bTitle, bAuthor, bPublisher, bDate, bPrice, bDetail)values( % s, % s, % s, "
"% s, % s, % s)",
(item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
`
settings.py
`
BOT_NAME = 'DDBooks'
SPIDER_MODULES = ['DDBooks.spiders']
NEWSPIDER_MODULE = 'DDBooks.spiders'
ITEM_PIPELINES = {
'DDBooks.pipelines.DdbooksPipeline': 300,
}
`
Books.py
`
import scrapy
from bs4 import UnicodeDammit
from DDBooks.items import DdbooksItem
class BooksSpider(scrapy.Spider):
name = 'Books'
# allowed_domains = ['search.dangdang.com']
key = 'java'
source_url = 'http://search.dangdang.com/'
def start_requests(self):
url = BooksSpider.source_url + '?key=' + BooksSpider.key
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath(
"./p[@class='search_book_author']/span[position()=last()-1] / text()").extract_first()
publisher = li.xpath(
"./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = DdbooksItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# 最后一页时link为None
link = selector.xpath(
"//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
`
运行截图:

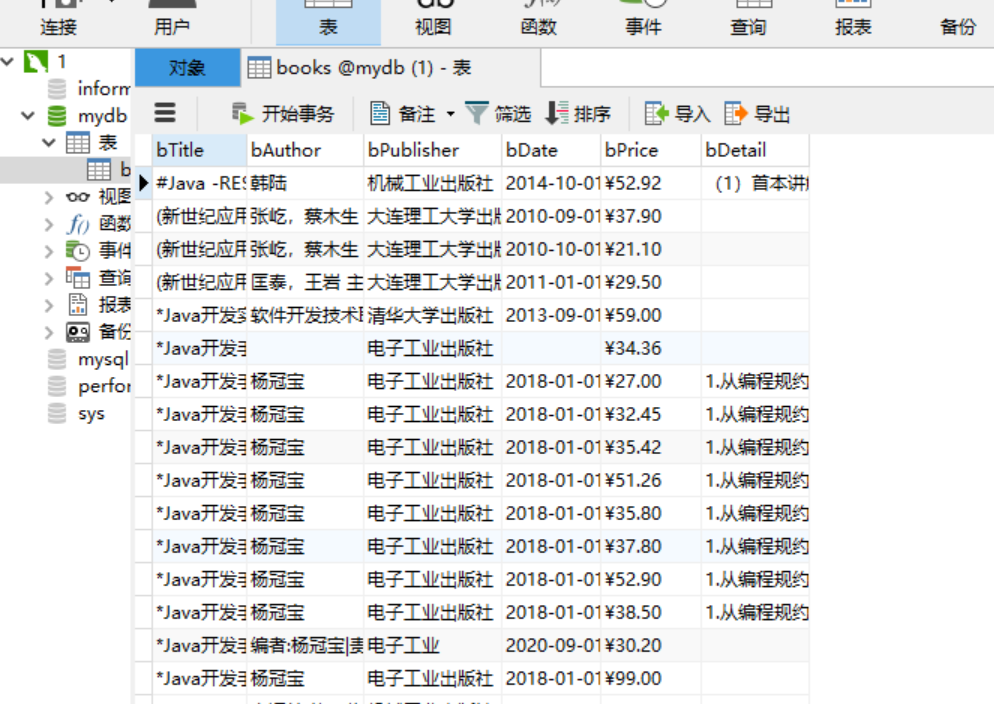
心得体会
这次作业书上有实例,通过例子也加深了对MySQL数据库的理解。刚开始source_url不小心用了列表类型,加了[]之后就没有跑出来结果,经改正后才正常。
作业二
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
代码部分
items.py
`
import scrapy
class MystocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
bNum = scrapy.Field()
bNo = scrapy.Field()
bName = scrapy.Field()
bPrice = scrapy.Field()
bUp = scrapy.Field()
bUDN = scrapy.Field()
bSum = scrapy.Field()
bMoney = scrapy.Field()
bAmp = scrapy.Field()
`
pipelines.py
`
import pymysql
from itemadapter import ItemAdapter
class MystocksPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
# 关闭连接
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into stocks(bNum, bNo, bName, bPrice, bUp, bUDN,bSum,bMoney,bAmp)values( % s, % s, % s, "
"% s, % s, % s, % s, % s, % s)",
(item["bNum"], item["bNo"], item["bName"], item["bPrice"], item["bUp"], item["bUDN"], item["bSum"],
item["bMoney"], item["bAmp"])) # 数据插入MySQL中的表
self.count += 1
except Exception as err:
print(err)
return item
`
sd.py
`
import re
import scrapy
from bs4 import UnicodeDammit
from mystocks.items import MystocksItem
class SdSpider(scrapy.Spider):
name = 'sd'
#allowed_domains = ['www.eastmoney.com']
#start_urls = ['http://www.eastmoney.com/']
start_urls = ['http://49.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112403706613772931069_1603890900421&pn=2&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1603890900433']
def parse(self, response):
req = response.text
pat = '"diff":[{(.*?)}]'
data = re.compile(pat, re.S).findall(req)
datas = data[0].split('},{') # 对字符进行分片
print("序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 ")
j = 0
for i in range(len(datas)):
item = MystocksItem()
s = r'"(w)+":'
line = re.sub(s, " ", datas[i]).split(",")
item["bNum"] = str(j + 1)
item["bNo"] = line[11]
item["bName"] = line[13]
item["bPrice"] = line[1]
item["bUp"] = line[2]
item["bUDN"] = line[3]
item["bSum"] = line[4]
item["bMoney"] = line[5]
item["bAmp"] = line[6]
j += 1
print(item["bNum"] + " ", item['bNo'] + " ", item['bName'] + " ", item['bPrice'] + " ", item['bUp'] + "% ",
item['bUDN'] + " ", item['bSum'] + " ", str(item['bMoney']) + " ", item['bAmp'])
yield item
`
运行截图:
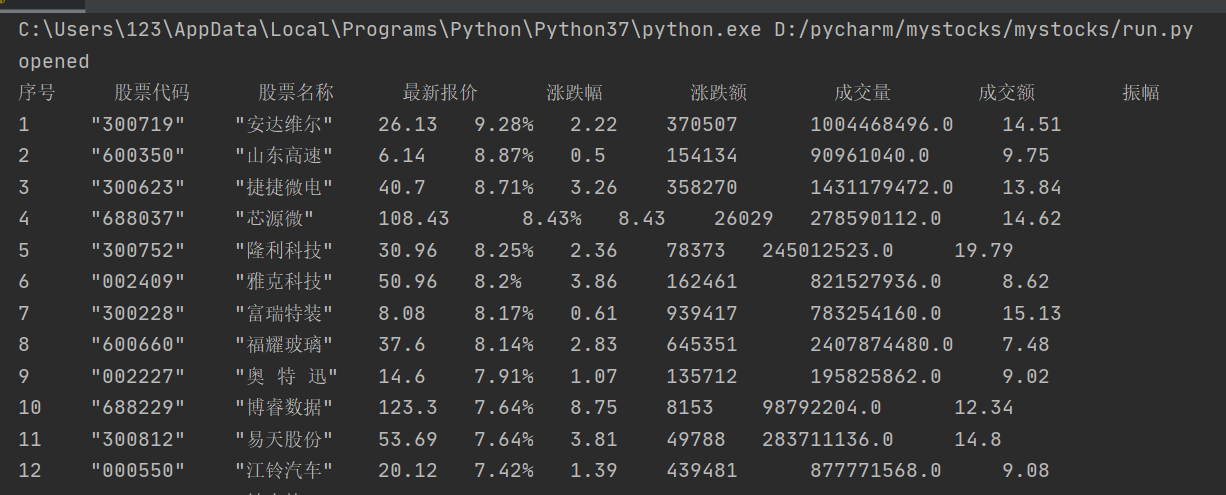
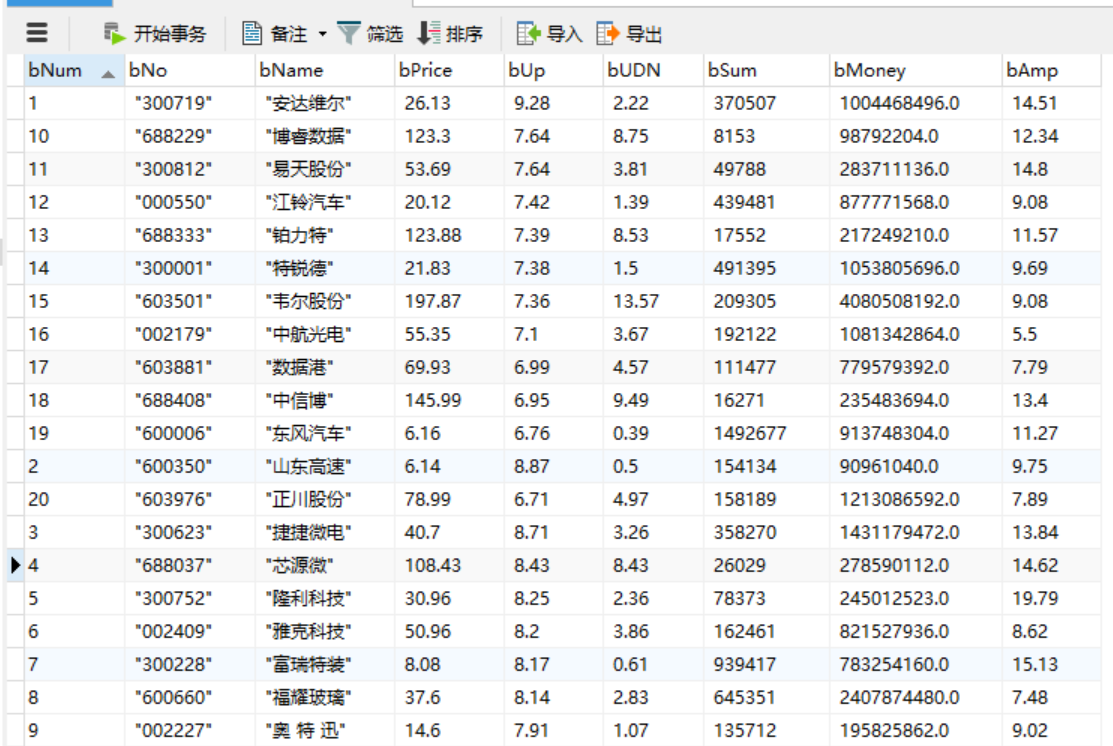
心得体会
这次我是在第三次作业基础上做的,遇到的问题就是在pycharm端序号能正常输出,但是导入数据库之后就没有按照序号排,不知道为什么。。。。
作业三
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
代码部分
items.py
`
import scrapy
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
`
pipelines.py
`
import pymysql
from itemadapter import ItemAdapter
class BankPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from money")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
#print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["id"])
print(item["Currency"])
print(item["TSP"])
print(item["CSP"])
print(item["TBP"])
print(item["CBP"])
print(item["Time"])
print()
if self.opened:
self.cursor.execute(
"insert into money(id, Currency, TSP, CSP, TBP, CBP, Time)values( % s, % s, % s, "
"% s, % s, % s, % s)",
(item["id"], item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
except Exception as err:
print(err)
return item
`
currency.py
`
import scrapy
from bs4 import UnicodeDammit
from Bank.items import BankItem
class CurrencySpider(scrapy.Spider):
name = 'currency'
# allowed_domains = ['fx.cmbchina.com/hq/']
start_urls = ['http://fx.cmbchina.com/hq//']
def parse(self, response):
i = 1
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
trs = selector.xpath("//div[@id='realRateInfo']/table/tr")
for tr in trs[1:]: # 第一个tr是表头,略过
id = i
Currency = tr.xpath("./td[@class='fontbold'][position()=1]/text()").extract_first()
TSP = tr.xpath("./td[@class='numberright'][position()=1]/text()").extract_first()
CSP = tr.xpath("./td[@class='numberright'][position()=2]/text()").extract_first()
TBP = tr.xpath("./td[@class='numberright'][position()=3]/text()").extract_first()
CBP = tr.xpath("./td[@class='numberright'][position()=4]/text()").extract_first()
Time = tr.xpath("./td[@align='center'][position()=3]/text()").extract_first()
item = BankItem()
item["id"] = id
item["Currency"] = Currency.strip() if Currency else ""
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["Time"] = Time.strip() if Time else ""
i += 1
yield item
except Exception as err:
print(err)
`
运行截图:
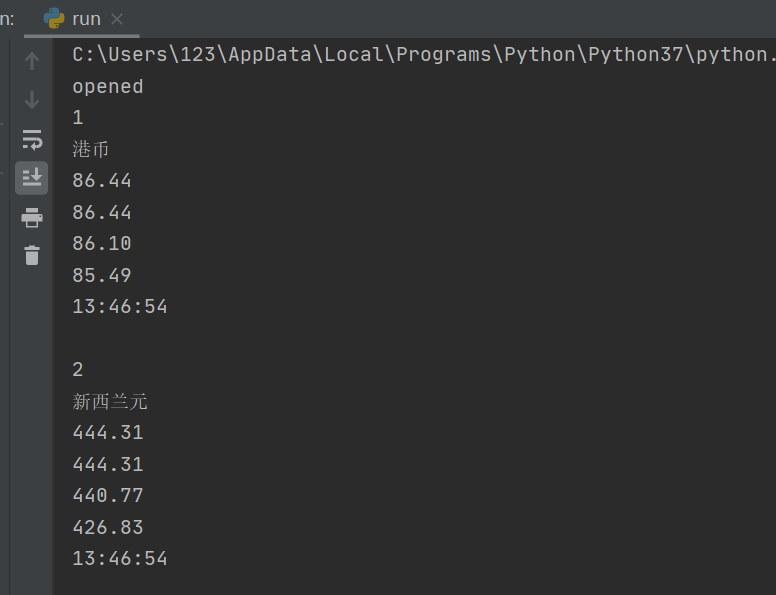
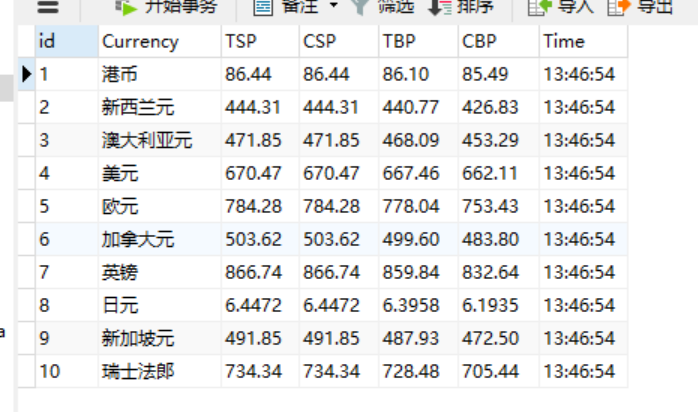
心得体会:
有了前两次的经验这次就简单很多,而且网页也是规规矩矩的静态网页,实现起来就比较简单。