作业①
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
代码如下:
单线程
`
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"html.parser")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
if(url[len(url)-4]=='.'):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("D:pycharm数据采集\pictures\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101230101.shtml"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
count=0
imageSpider(start_url)
`

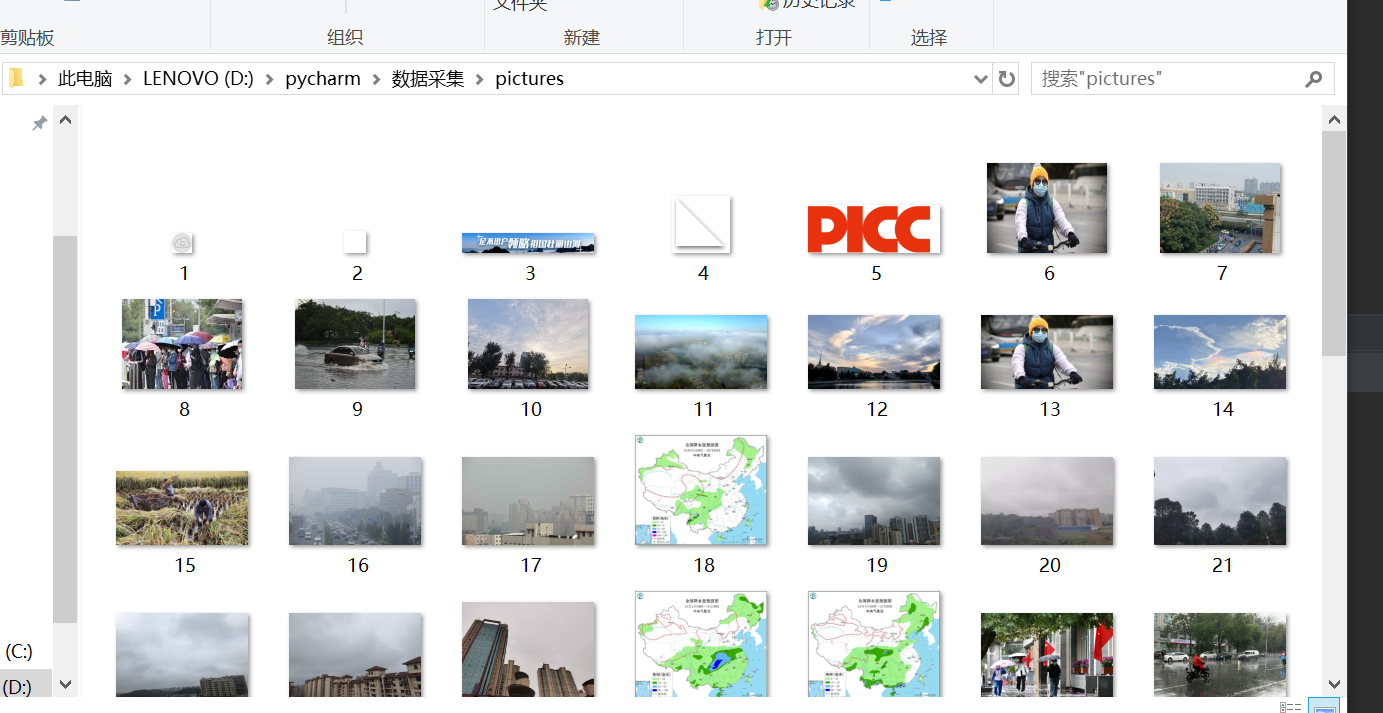
多线程:
`
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"html.parser")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
print(url)
count=count+1
T=threading.Thread(target=download,args=(url,count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
count=count+1
if(url[len(url)-4]=='.'):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("D:pycharm数据采集\pictures2\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101230101.shtml"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
`


心得体会:这次作业主要是对书本内容的复现,加深了对线程与多线程运行过程的认识。
作业②
用scrapy框架爬取网站图片,我选取了一个壁纸网站进行爬取
setting.py
`
BOT_NAME = 'netbian'
SPIDER_MODULES = ['netbian.spiders']
NEWSPIDER_MODULE = 'netbian.spiders'
`
items.py
`
import scrapy
class NetbianItem(scrapy.Item):
# define the fields for your item here like:
imgname = scrapy.Field() # 图片名称
imgurl = scrapy.Field() # 图片地址
dirname = scrapy.Field() # 图片存放文件名
`
pipelines.py
`
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class NetbianPipeline(ImagesPipeline):
# 注释掉原来的函数
# def process_item(self, item, spider):
# return item
# 重写两个方法
# 爬取图片
def get_media_requests(self, item, info):
for i in range(len(item['imgurl'])):
# 爬取的图片地址并不是完整的,需要加上协议和域名
imgurl = "http://pic.netbian.com" + item['imgurl'][i]
# meta 传参给self.file_path()
yield scrapy.Request(imgurl, meta={'imgname': item['imgname'][i], 'dirname': item['dirname']})
# 给图片定义存放位置和图片名
def file_path(self, request, response=None, info=None):
imgname = request.meta['imgname'].strip() + '.jpg'
dirname = request.meta['dirname']
filename = u"{}/{}".format(dirname, imgname)
return filename
`
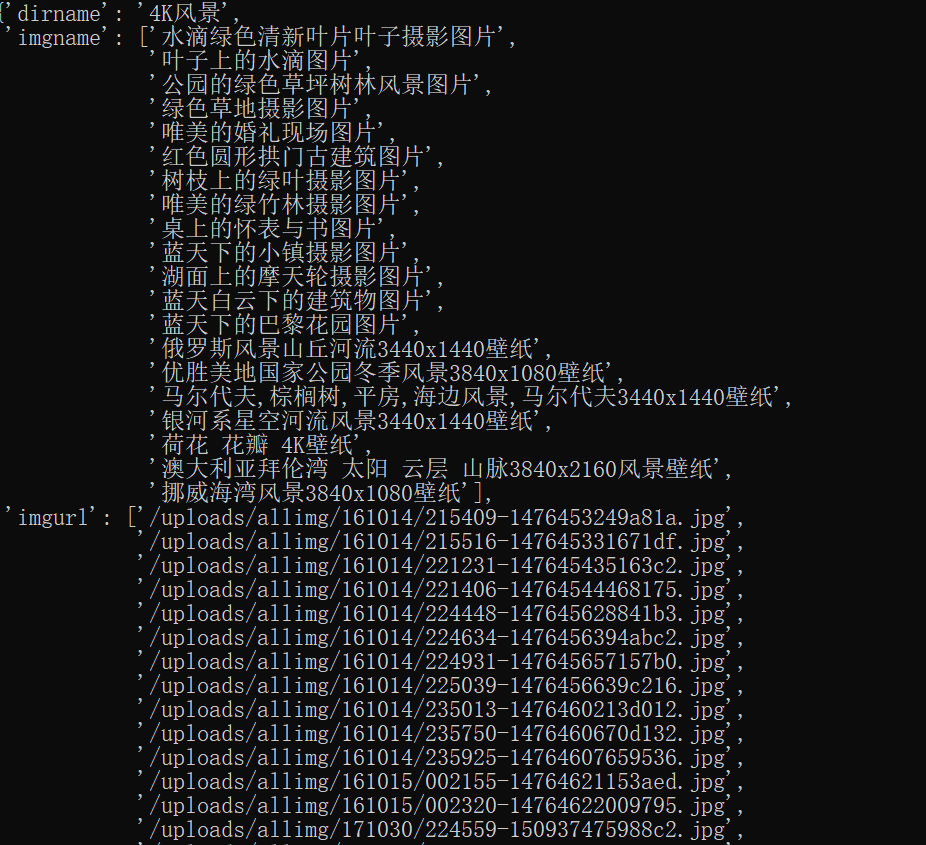
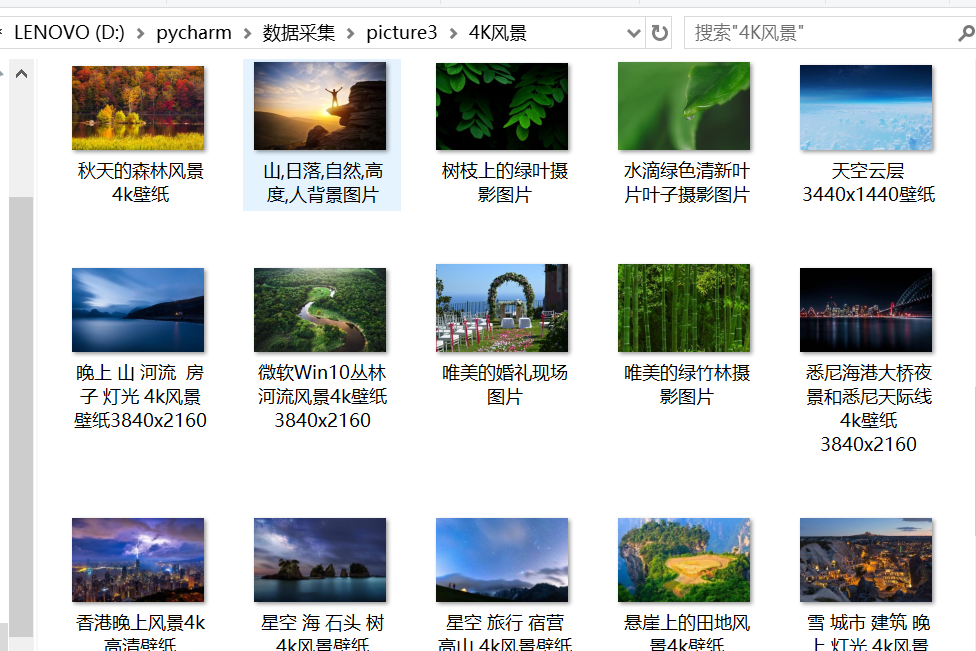
心得体会:
这次实验过程中遇到了from ..items import NetbianItem运行时报错,调用范围出错,看网上的参考教程这样写,没有多加思考就用了,后来改成在本文件夹下调用就正常了,以后还是要仔细一些。
实验③
使用scrapy框架爬取股票相关信息。
settings.py
`
BOT_NAME = 'Dfstocks'
SPIDER_MODULES = ['Dfstocks.spiders']
NEWSPIDER_MODULE = 'Dfstocks.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'Dfstocks.pipelines.DfstocksPipeline': 300,
}
`
items.py
`
import scrapy
class DfstocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
number = scrapy.Field()
f12 = scrapy.Field()
f14 = scrapy.Field()
f2 = scrapy.Field()
f3 = scrapy.Field()
f4 = scrapy.Field()
f5 = scrapy.Field()
f6 = scrapy.Field()
f7 = scrapy.Field()
`
stocks.py
`
import scrapy
import re
from Dfstocks.items import DfstocksItem
class StocksSpider(scrapy.Spider):
name = 'stocks'
#allowed_domains = ['www.eastmoney.com']
start_urls = ['http://99.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408165941736007347_1603177898272&pn=2&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1603177898382']
def parse(self, response):
req = response.text
pat = '"diff":[{(.*?)}]'
data = re.compile(pat, re.S).findall(req)
datas = data[0].split('},{') #对字符进行分片
print("序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 ")
for i in range(len(datas)):
item = DfstocksItem()
s = r'"(w)+":'
line = re.sub(s, " ", datas[i]).split(",")
item["number"] = str(i + 1)
item["f12"] = line[11]
item["f14"] = line[13]
item["f2"] = line[1]
item["f3"] = line[2]
item["f4"] = line[3]
item["f5"] = line[4]
item["f6"] = line[5]
item["f7"] = line[6]
print(item["number"] + " ", item['f12'] + " ", item['f14'] + " ", item['f2'] + " ", item['f3'] + "% ",item['f4'] + " ", item['f5'] + " ", str(item['f6']) + " ", item['f7'])
yield item
`

心得体会:
这次实验我是在第二次实验上加以改动的,因为时间太紧张了,在scrapy框架下进行爬取简便了很多,很不错。