GitHub链接:https://github.com/031804126/031804126
PSP记录表格:

经过查找资料,我发现实现文本相似度的计算大家比较常用并且难度不是很大的有TF-IDF与余弦相似性的应用、引用jieba库使用余弦相似度,还有难度稍微大一点的jaccard相似度,编辑距离,MinHash,SimHash+海明距离(对于我来说),所以这里选用了使用jieba库以及余弦相似度进行计算。原理如下:
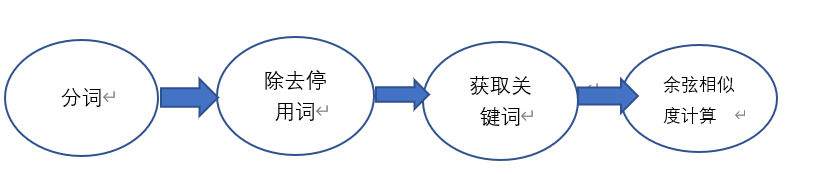
用到的主要函数:①extract_keyword():用来获取关键词。
②one_hot()。
③:cosine_similarity():计算余弦相似度。``
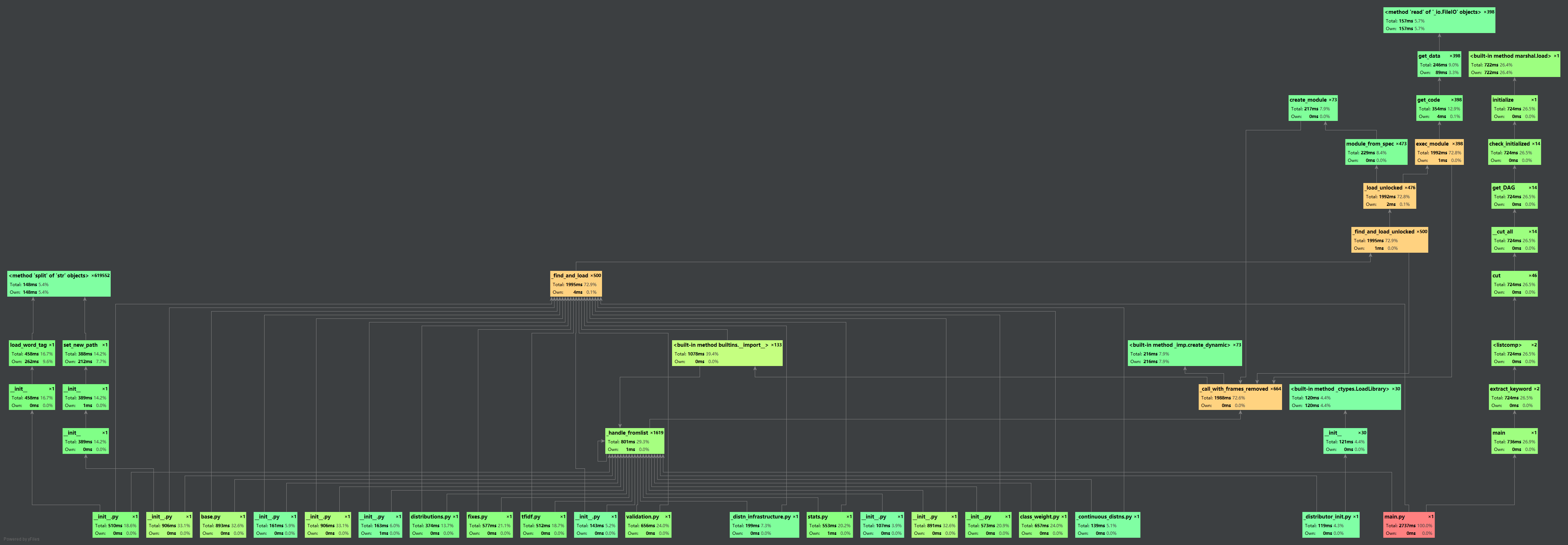
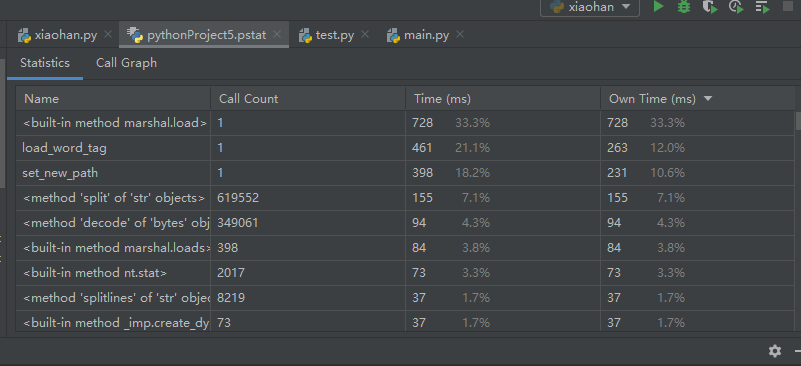
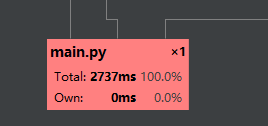
计算模块部分的性能改进
附上性能分析图:
单元测试部分:
函数部分与主函数相同
if __name__ == '__main__':
x=input()
y=input()
z=input()
fx=open(x,'r',encoding='utf-8')
fy=open(y,'r',encoding='utf-8')
content_x = fx.read()
content_y = fy.read()
similarity = CosineSimilarity(content_x, content_y)
similarity = similarity.main()
g = open(r"C:Users123AppDataLocalProgramsPythonPython37
esult.txt",'w+')
file_handle=open('result.txt',mode='w')
file_handle.write('相似度: {:.2f}' .format(similarity))
file_handle.close()
fx.close()
fy.close()
print('相似度: {:.2f}' .format(similarity))
测试结果:
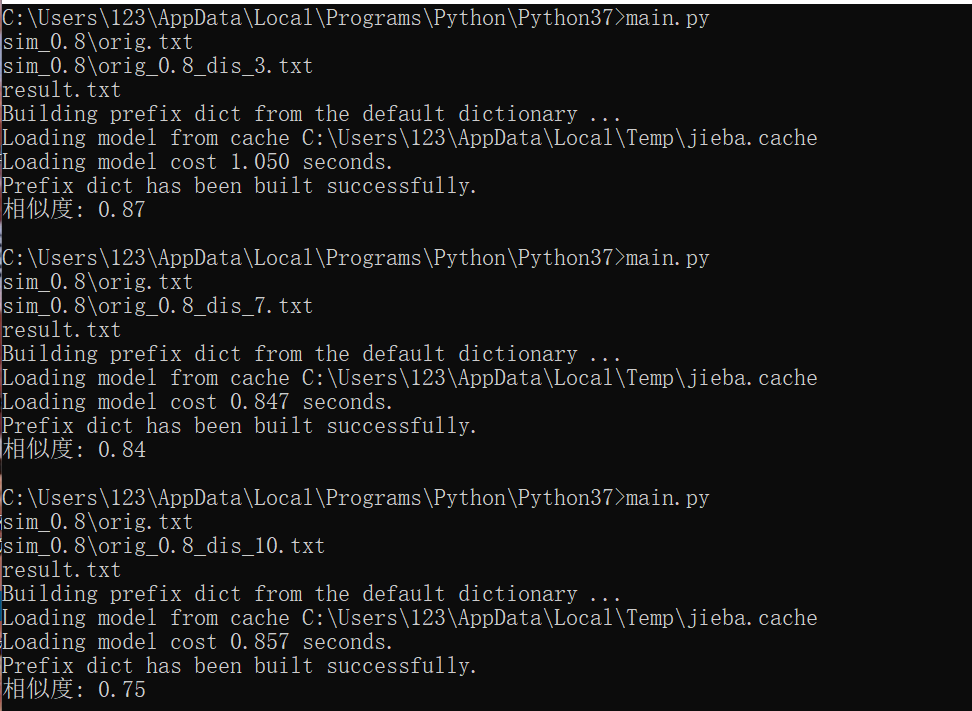
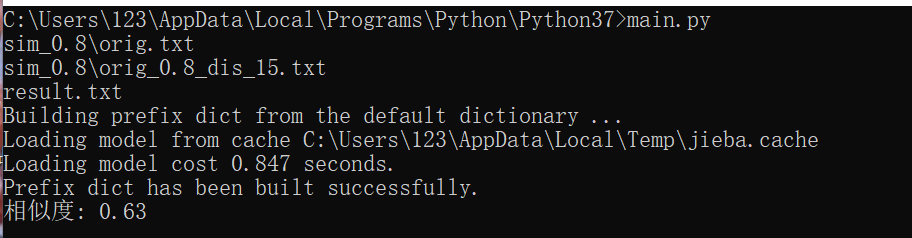

以上是在Windows中Python环境下测试的,读取方法比较low,在pycharm中进行性能测试的时候,进行了以下改进:
文件读取方式改为:fx=open(sys.argv[1],'r',encoding='utf-8'),fy=open(sys.argv[2],'r',encoding='utf-8'),目标文件改为:output = open(sys.argv[3],'w',encoding='utf-8')
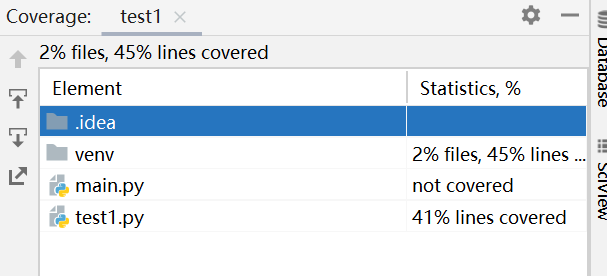
覆盖率:
异常处理
(1)文件为空

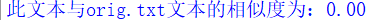
(2)文件不存在

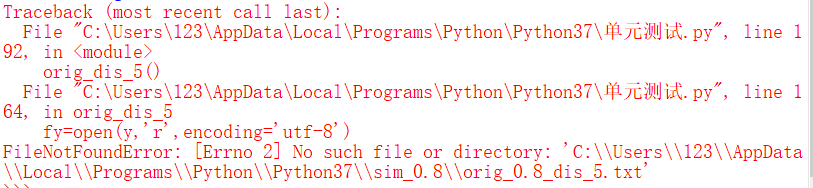
总结:
没想到第一次实际编程就来了这么大的工程,刚开始属实有点吃不消,到处找资料,不过在实践中也丰富了自己,看来以后要多利用闲暇时间学习,才能面对接下来的挑战。