首先讲讲什么是直接寻址
直接寻址表的定义
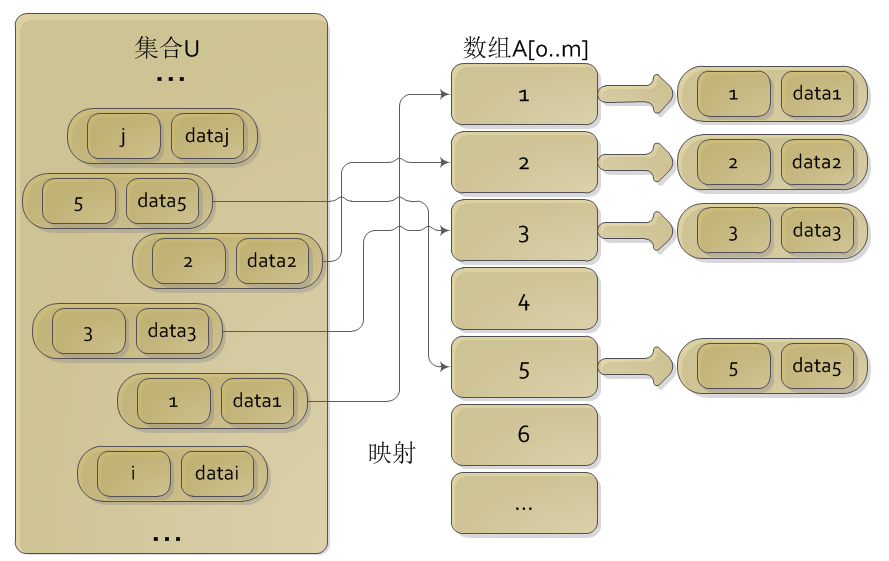
假设有一个数据集合U={d1,d2,d3,...,dn}U={d1,d2,d3,...,dn},该数据集合里面的每一个元素didi都有一个对应的键值keyikeyi和数据dataidatai。集合中的任意一个keyikeyi都是在[0,m][0,m]之间的整数。新建一个数组A[0..m]A[0..m],遍历一遍集合UU,将其中的数据didi放到A[keyi]A[keyi]中。
如果存的是两个树1和10000 那么就要开辟一段内存从1到10000,这样对空间是很大浪费,所以就有来哈希表
哈希表:
.哈希表(Hash Table , 又称散列表 )是线性表对存储结构,由直接寻址表和一个哈希函数组成,哈希函数h(k)将元素k作为自变量
返回元素存储下标
举个栗子:
class HashTable:
def __init__(self,size=101):
self.size = size
self.T = [LinkList() for i in range(self.size)]
def h(self,k):
return k % self.size
def insert(self,k):
i = self.h(k)
if self.find(k):
print('duplicated insert')
else:
self.T[i].append(k)
def find(self,k):
i = self.h(k)
return self.T[i].find(k)
就以上栗子,哈希函数h(k)取余 会有问题,会有重复,那么这就是哈希冲突
处理冲突的方法
(1)开放定址法(2)拉链法 (3)建立公共溢出区法
拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组t[0..m-1]。凡是散列地址为i的结点,均插入到以t为头指针的单链表中。t中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。

处理哈希冲突对方法还有很多种,这里不一一说明