select count(1) as maxsize from person_dt; //获取最大条数
https://blog.csdn.net/weixin_26824207/article/details/113309821
作者:何甜甜在吗
来源:juejin.im/post/5bcc2935f265da0ac66987c9
(一)慢sql一
问题发现
将应用发布到生产环境后,前端页面请求后台API返回数据,发现至少需要6s。查看到慢sql:
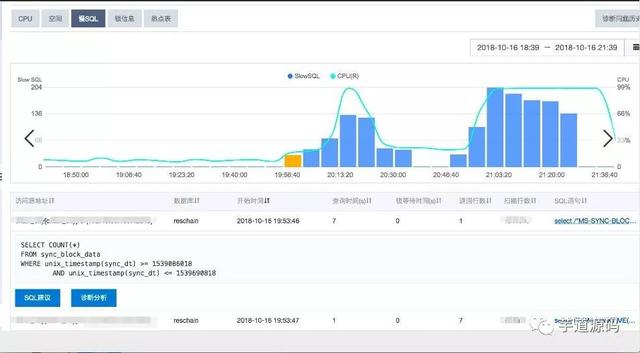
慢sql定位.png
复现慢sql
执行sql:
select count(*) from sync_block_data
where unix_timestamp(sync_dt) >= 1539101010
AND unix_timestamp(sync_dt) <= 1539705810
查看耗时:

慢查询耗时.png
一共耗时为2658ms 查看执行计划:
explain select count(*) from sync_block_data
where unix_timestamp(sync_dt) >= 1539101010
AND unix_timestamp(sync_dt) <= 1539705810
执行计划结果:

慢查询执行计划.png
优化慢sql一
sync_dt的类型为datetime类型。换另外一种sql写法,直接通过比较日期而不是通过时间戳进行比较。将sql中的时间戳转化为日期,分别为2018-10-10 00:03:30和2018-10-17 00:03:30 执行sql:
select count(*) from sync_block_data
where sync_dt >= "2018-10-10 00:03:30"
AND sync_dt <= "2018-10-17 00:03:30"
查看耗时:

快查询耗时.png
一共耗时419毫秒,和慢查询相比速度提升六倍多 查看执行计划:
explain select count(*) from sync_block_data
where sync_dt >= "2018-10-10 00:03:30"
AND sync_dt <= "2018-10-17 00:03:30"
执行计划结果:

快查询执行计划.png
访问页面,优化完成后请求时间平均为900毫秒
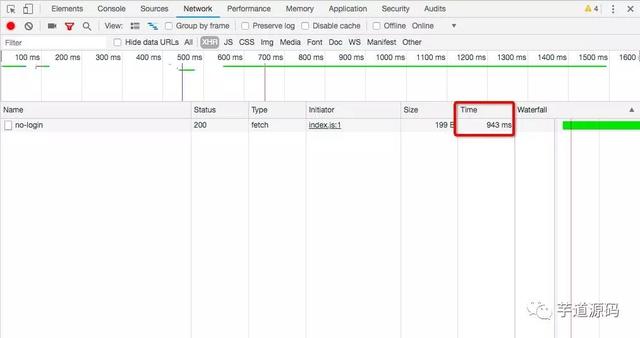
执行计划中慢查询和快查询唯一的区别就是type不一样:慢查询中type为index,快查询中type为range。
优化慢查询二
这条sql的业务逻辑为统计出最近七天该表的数据量,可以去掉右边的小于等于 执行sql:
select count(*) from sync_block_datawhere sync_dt >= "2018-10-10 00:03:30"
查看耗时:

一共耗时275毫秒,又将查询时间减少了一半 查看执行计划:
explain select count(*) from sync_block_datawhere sync_dt >= "2018-10-10 00:03:30"
执行计划结果:

type仍是range。但是通过少比较一次将查询速度提高一倍
优化慢查询三
新建一个bigint类型字段sync_dt_long存储sync_dt的毫秒值,并在sync_dt_long字段上建立索引 测试环境下:优化慢查询二sql
select count(*) from copy_sync_block_datawhere sync_dt >="2018-10-10 13:15:02"
耗时为34毫秒 优化慢查询三sql
select count(*) from copy_sync_block_datawhere sync_dt_long >= 1539148502916
耗时为22毫秒 测试环境中速度提升10毫秒左右
优化慢查询三sql测试小结:在InnoDB存储引擎下,比较bigint的效率高于datetime 完成三步优化以后生产环境中请求耗时:
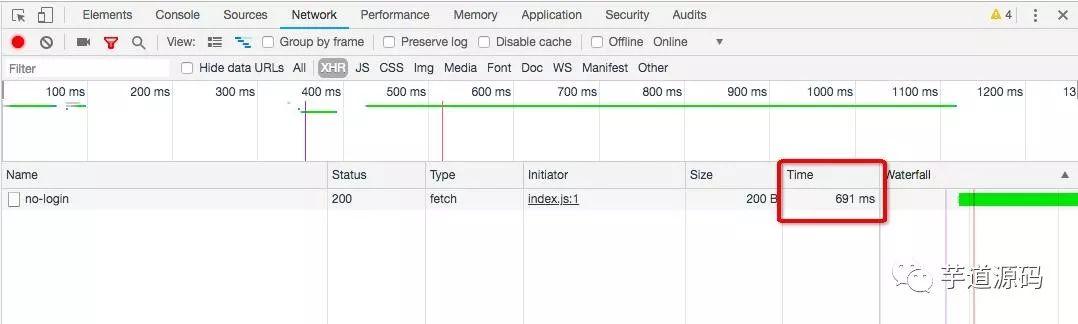
速度又快了200毫秒左右。通过给查询的数据加10s缓存,响应速度最快平均为20ms
explain使用介绍
通过explain,可以查看sql语句的执行情况(比如查询的表,使用的索引以及mysql在表中找到所需行的方式等) 用explain查询mysql查询计划的输出参数有:
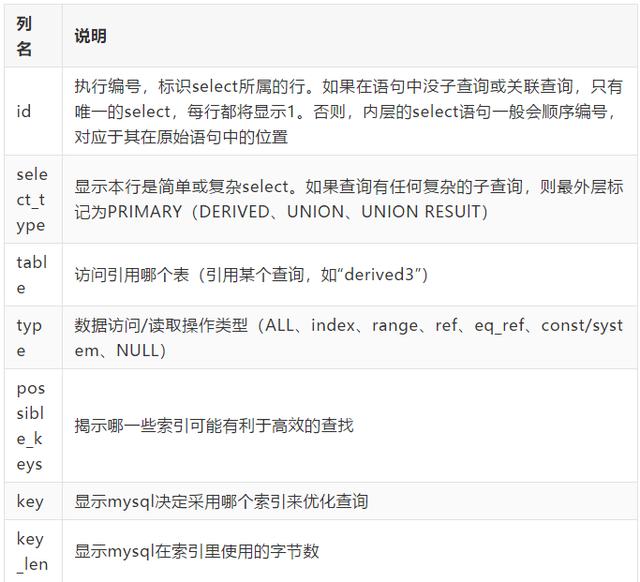

重点关注type,type类型的不同竟然导致性能差六倍!!!

type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref。


出现慢查询的原因
在where子句中使用了函数操作 出现慢查询的sql语句中使用了unix_timestamp函数统计出自'1970-01-01 00:00:00'的到当前时间的秒数差。导致索引全扫描统计出近七天的数据量的
解决方案
尽量避免在where子句中对字段进行函数操作,这将导致存储引擎放弃使用索引而进行全表扫描。对于需要计算的值最好通过程序计算好传入而不是在sql语句中做计算,比如这个sql中我们将当前的日期和七天前的日期计算好传入
后记
这个问题当时在测试环境没有发现,测试环境的请求速度还是可以的。没有被发现可以归结为数据量。生产数据量为百万级别,测试环境数据量为万级,数据量差50倍,数据量的增大把慢查询的问题也放大了。
(二)慢sql二
因为线上出现了很明显的请求响应慢的问题,又去看了项目中的其他sql,发现还有sql执行的效率比较低
复现慢sql
执行sql
select FROM_UNIXTIME(copyright_apply_time/1000,'%Y-%m-%d') point,count(1) numsfrom resource_info
where copyright_apply_time >= 1539336488355
and copyright_apply_time <= 1539941288355 group by point
查看耗时:

耗时为1123毫秒 查看执行计划:
explain select FROM_UNIXTIME(copyright_apply_time/1000,'%Y-%m-%d') point,count(1) numsfrom resource_info
where copyright_apply_time >= 1539336488355
and copyright_apply_time <= 1539941288355 group by point
执行计划结果:
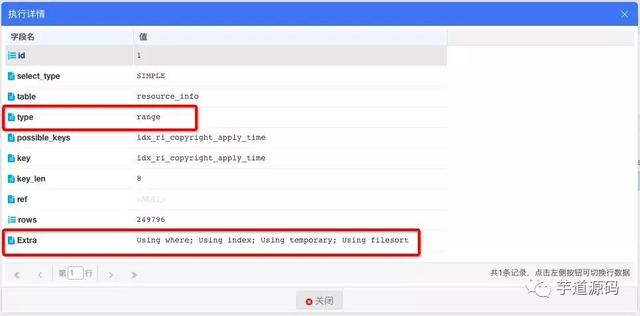
索引是命中了,但是extra字段中出现了Using temporary和Using filesort
优化慢sql一
group by实质是先排序后分组,也就是分组之前必排序。通过分组的时候禁止排序优化sql 执行sql:
select FROM_UNIXTIME(copyright_apply_time/1000,'%Y-%m-%d') point,
count(1) numsfrom resource_info
where copyright_apply_time >= 1539336488355
and copyright_apply_time <= 1539941288355 group by point order by null
查看耗时:

一共耗时1068毫秒,提高100毫秒左右,效果并不是特别明显 查看执行计划:
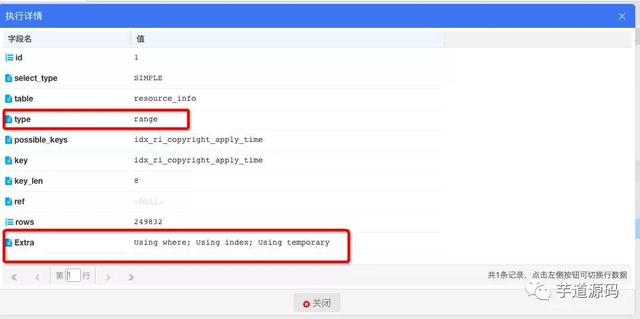
extra字段已经没有Using filesort了,filesort表示通过对返回数据进行排序。所有不是通过索引直接返回排序结果的排序都是FileSort排序,说明优化后通过索引直接返回排序结果 Using temporary依然存在,出现Using temporary表示查询有使用临时表, 一般出现于排序, 分组和多表join的情况, 查询效率不高, 仍需要进行优化,这里出现临时表的原因是数据量过大使用了临时表进行分组运算
优化慢sql二
慢查询的sql业务逻辑为根据时间段分类统计出条件范围内各个时间段的数量 比如给定的条件范围为2018-10-20~2018-10-27的时间戳,这条sql就会统计出2018-10-20~2018-10-27每天的数据增量。现在优化成一天一天查,分别查七次数据,去掉分组操作
select FROM_UNIXTIME(copyright_apply_time/1000,'%Y-%m-%d') point,
count(1) numsfrom resource_info
where copyright_apply_time >= 1539855067355
and copyright_apply_time <= 1539941467355
查看耗时:

耗时为38毫秒,即使查7次所用时间也比1123毫秒少 查看执行计划:
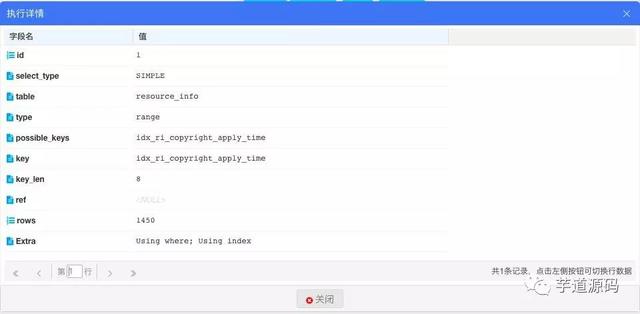
extra字段中和慢查询的extra相比少了Using temporary和Using filesort。完美
就这样第一次经历了真正的慢查询以及慢查询优化,终于理论和实践相结合了