一、单表查询
1. 查询所有 *
mysql> select * from student;
2. 查询选中字段记录
mysql> select s_name from student;

3. 条件查询 where
mysql> select s_name from student where s_id<5;

4. 查询后为字段重命名 as
mysql> select s_name as 名字 from student;

5. 模糊查询 like
%匹配多个字符
mysql> select s_name as 姓名 from student where s_name like '李%';

_匹配一个字符
mysql> select s_name as 姓名 from student where s_name like '李_';

6. 排序(默认升序) order by 以某个字段为主进行排序
升序 asc (asc可以不写)
mysql> select * from student order by sc_id asc;
降序 desc
mysql> select * from student order by sc_id desc;

7. 限制显示数据数量 limit
limit 只接一个数字n时表示显示前面n行
mysql> select * from student limit 5;
limit 接两个数字m,n时表示显示第m行(不包括第m行)之后的n行
mysql> select * from student limit 2,4;

8. 常用聚合函数
mysql> select * from details;

最大值 max
mysql> select max(age) from details;

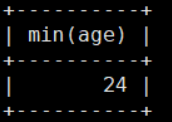
最小值 min
mysql> select min(age) from details;
求和 sum
mysql> select sum(age) from details;
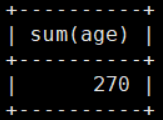
平均值 avg
mysql> select avg(age) from details;
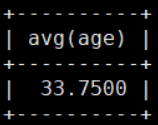
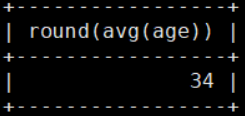
四舍五入 round
mysql> select round(avg(age)) from details;
统计 count
mysql> select count(address) from details;

注1:
1、count(1):可以统计表中所有数据,不统计所有的列,用1代表代码行,在统计结果中包含列字段为null的数据;
2、count(字段):只包含列名的列,统计表中出现该字段的次数,并且不统计字段为null的情况;
3、count(*):统计所有的列,相当于行数,统计结果中会包含字段值为null的列;
注2:count执行效率
列名为主键,count(列名)比count(1)快;列名不为主键,count(1)会比count(列名)快;
如果表中多个列并且没有主键,则count(1)的执行效率优于count(*);
如果有主键,则select count(主键)的执行效率是最优的;如果表中只有一个字段,则select count(*)最优。
例:
CREATE TABLE `user` ( `id` int(5) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) DEFAULT NULL, `password` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=latin1
测试数据为:
1 name1 123456
2 name2 123456
3 name3 123456
4 name4 NULL
进行查询:
mysql>select count(*) from `user` mysql>select count(name) from `user` mysql>select count(password) from `user`
得到的结果:4,4,3
原因:
1,count(*)是对行数目进行计数,所以结果为4。
2,count(column_name)是对列中不为空的行进行计数,所以count(name)=4,而count(password)=3。
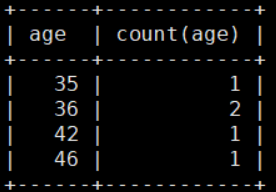
9. 分组查询 group by
筛选条件使用having,having后接条件必须是select后存在的字段
mysql> select age,count(age) from details group by age having age>30;
以age为组统计每个age的人数最后筛选出age大于30的
二、子查询(嵌套查询)
mysql> select * from details where age>(select avg(age) from details);
查询所有age大于平均年龄的信息

三、关联查询
内连接 inner join
无条件内连接 又称笛卡尔连接
mysql> select * from student inner join college;
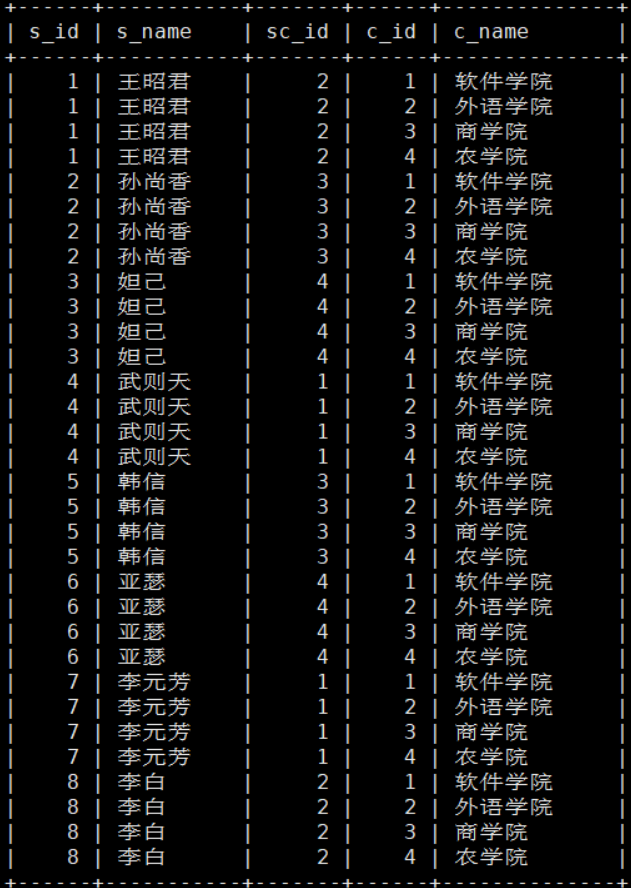
有条件内连接 在无条件基础上,on接条件
mysql> select * from student inner join college on sc_id=c_id;

外连接

- 左外连接 left join
以左表为基准,右表没有对应数据以null填充,多余数据去除
mysql> select * from tb1 left join tb2 on id=t_id;

mysql> select * from tb2 left join tb1 on id=t_id;
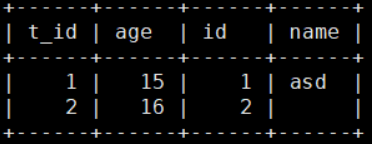
- 右外连接 right join
以右表为基准,左表没有对应数据以null填充,多余数据去除
mysql> select * from tb1 right join tb2 on id=t_id;

mysql> select * from tb2 right join tb1 on id=t_id;

派生表必须命名 as
mysql> select * from (select * from details where age>30) as a left join student on d_id=s_id;

四、去重 distinct 的用法
在使用MySQL时,有时需要查询出某个字段不重复的记录,这时可以使用mysql提供的distinct这个关键字来过滤重复的记录,但是实际中我们往往用distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段,
在使用distinct的过程中主要注意一下几点:
- 在对字段进行去重的时候,要保证distinct在所有字段的最前面
- 如果distinct关键字后面有多个字段时,则会对多个字段进行组合去重,只有多个字段组合起来的值是相等的才会被去重
下面我们通过在开发过程中经常遇到的一些关于distinct的实例来加深大家对该关键字用法的理解:
数据库表结构和数据如下图所示:

- 对单个字段进行去重sql
select distinct age from user; 查询结果 age 10 20 30
- 对多个字段进行去重sql:
select distinct name,age from user; 查询结果 name age One 10 Zero 20 Two 20 Four 30 One 30
- 对多个字段进行去重并求count的sql(实际中我们往往用distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段):
select count(distinct name,age) as total from user; 查询结果 total 5
- 对select * 进行去重
select distinct * from user; 由于 * 代表所有字段,所以该sql和 select distinct id,name,age,sign from user 语义相同 查询结果: id name age sign 1 One 10 梦想要有的,万一实现了呢 2 Zero 20 http://www.chaoshizhushou.com 3 Two 20 OneZeroTwoFour 4 Four 30 加油 5 One 30 学习才是硬道理 6 Four 30 一日三省吾身
如果sql这样写:select id,distinct name from user,这样mysql会报错,因为distinct必须放在要查询字段的开头。
所以一般distinct用来查询不重复记录的条数。
如果要查询不重复的记录,有时候可以用group by :
select id,name from user group by name;
五、group by 的用法
1. group by的常规用法
group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤。

- 聚合函数max
- select max(user_id),grade from user_info group by grade ;

这条sql的含义很明确,将数据按照grade字段分组,查询每组最大的user_id以及当前组内容。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
having
select max(user_id),grade from user_info group by grade having grade>'A'

这条sql与上面例子中的基本相同,不过后面跟了having过滤条件。将grade不满足’>A’的过滤掉了。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
2. group by的非常规用法
select max(user_id),id,grade from user_info group by grade
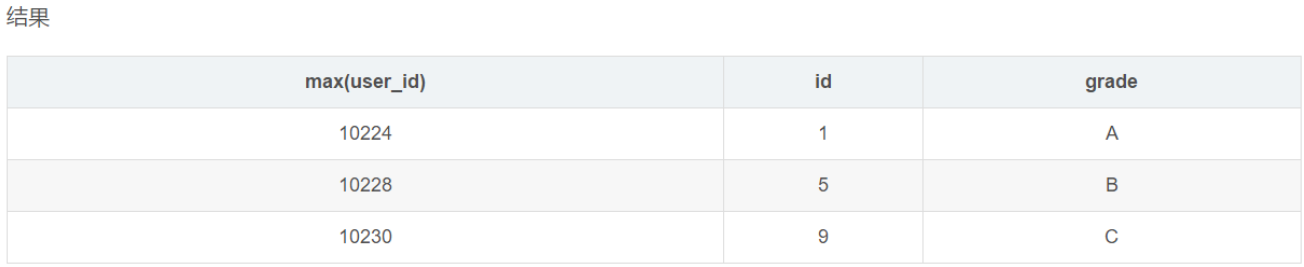
这条sql的结果就值得讨论了,与上述例子不同的是,查询条件多了id一列。数据按照grade分组后,grade一列是相同的,max(user_id)按照数据进行计算也是唯一的,id一列是如何取值的?看上述的数据结果,
推论:id是物理内存的第一个匹配项。
究竟是与不是需要继续探讨。
3. 结论
- 当group by 与聚合函数配合使用时,功能为分组后计算
- 当group by 与having配合使用时,功能为分组后过滤
- 当group by 与聚合函数,同时非聚合字段同时使用时,非聚合字段的取值是第一个匹配到的字段内容,即id小的条目对应的字段内容。