列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
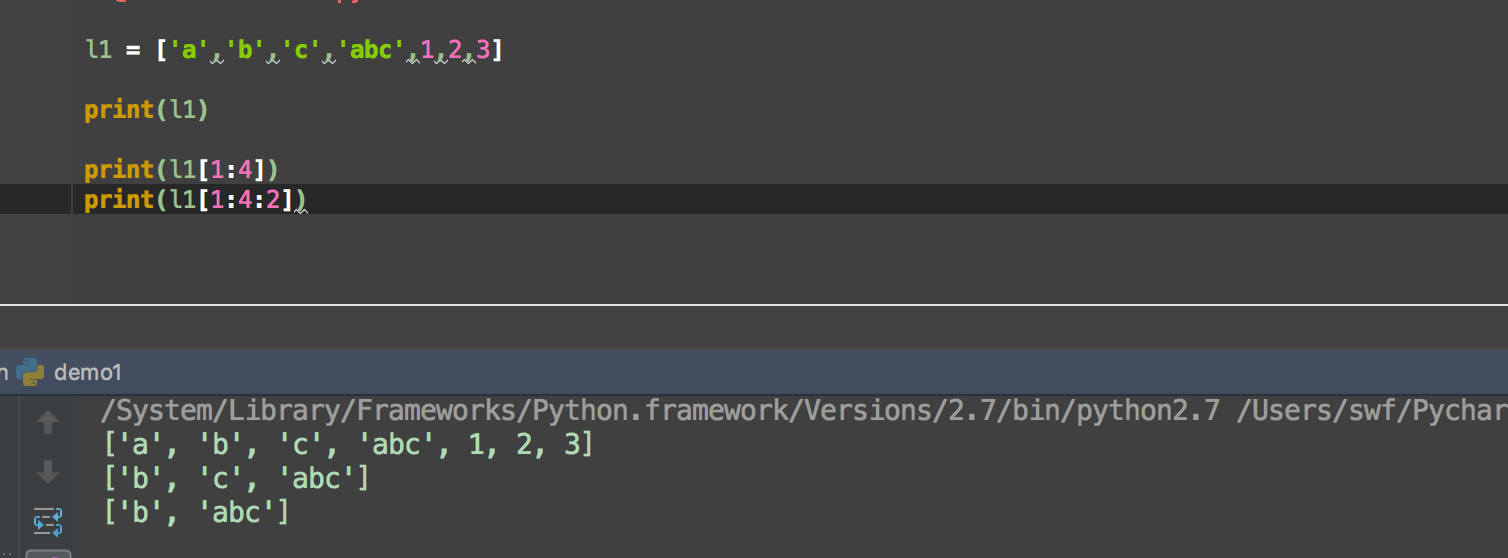
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
例:
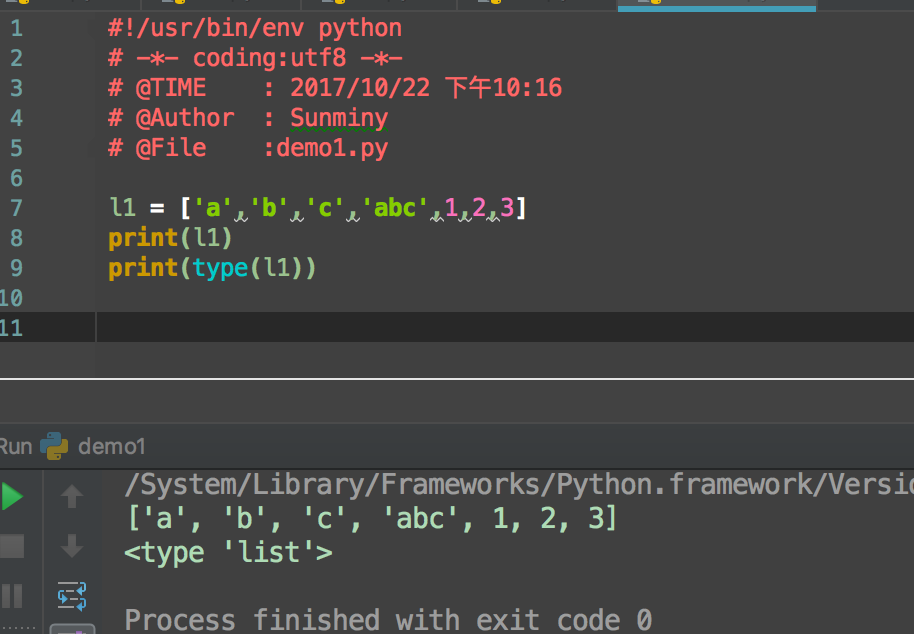
list 常用方法:
append list末尾追加一个元素
index 列出符合条件的list下标
insert 插入list一个元素
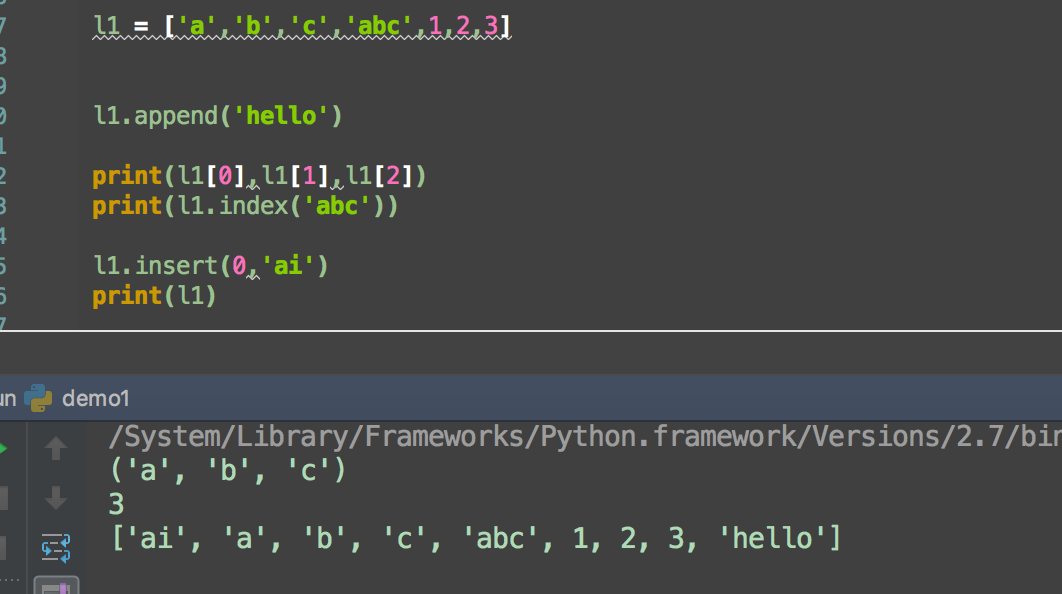
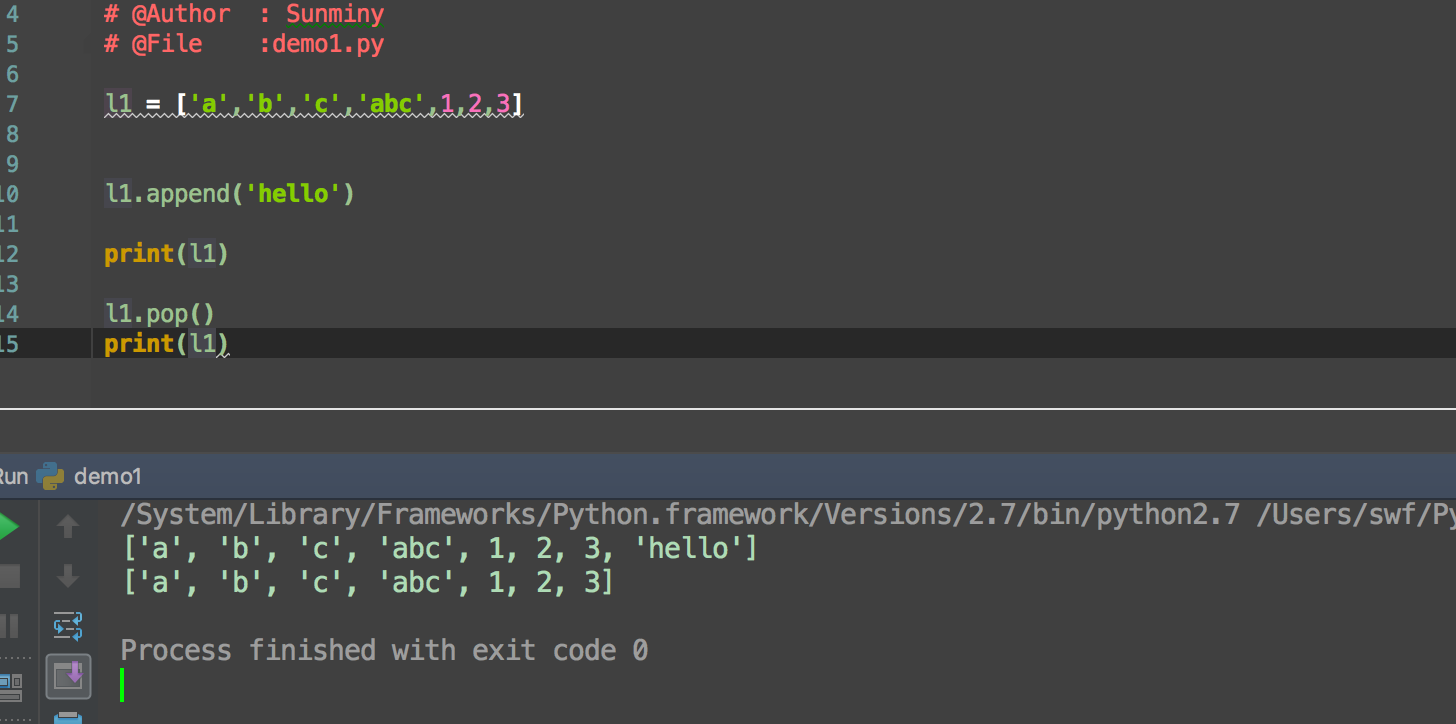
pop 末尾删除一个list元素
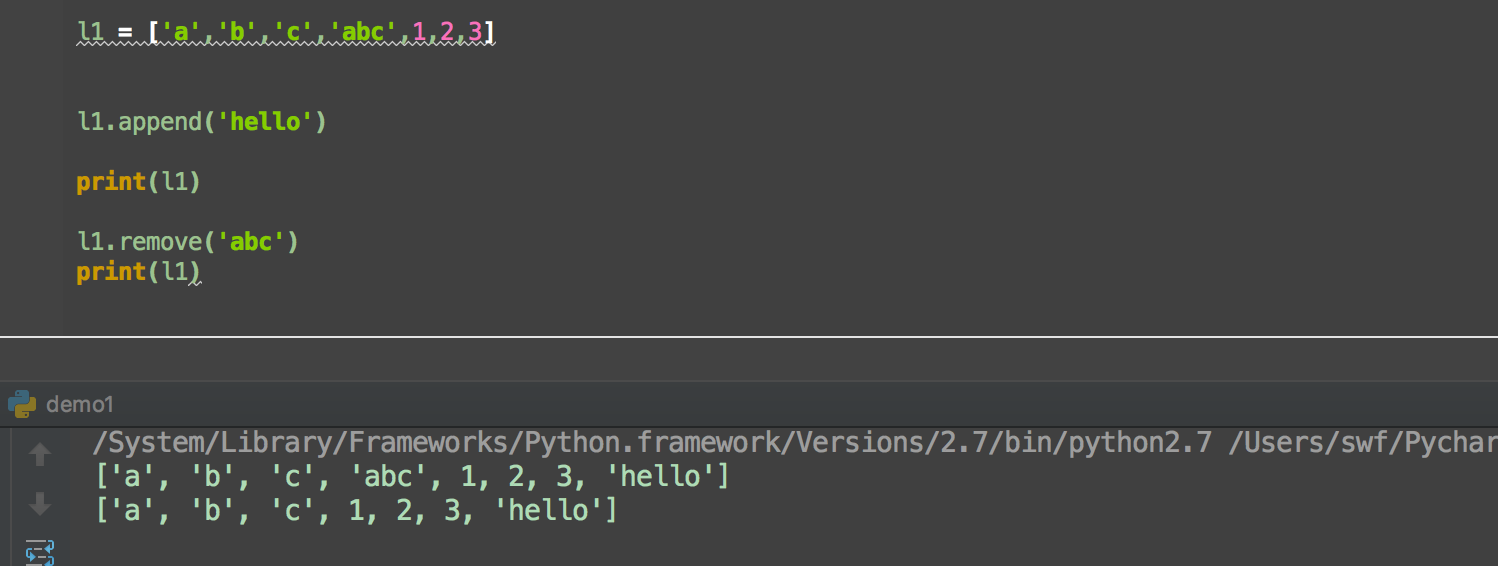
remove 删除list一个元素,如果有多个元素需要多次删除
sort list排序

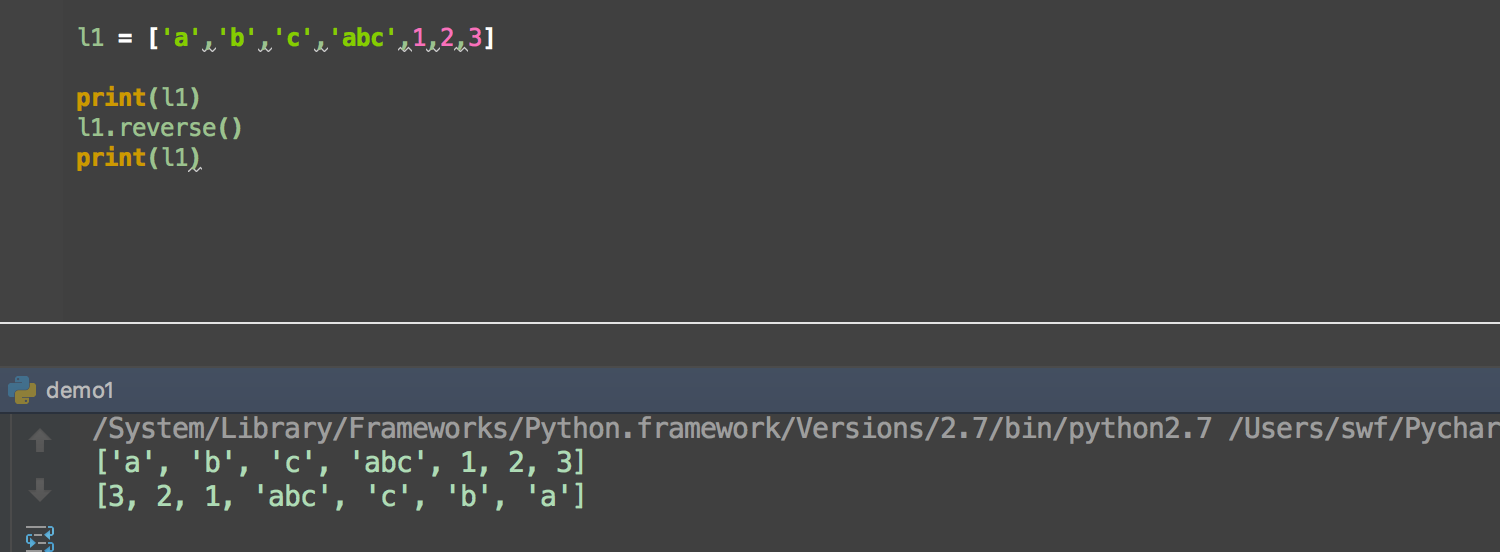
reverse list反序
切片
切片操作符在python中的原型是:
[start:stop:step] 即:[开始索引:结束索引:步长值]
开始索引:同其它语言一样,从0开始,序列从左向右方向中,第一个值的索引为0,最后一个为-1;
结束索引:切片操作符将取到该索引为止,不包含该索引的值;
步长值:默认是一个接一个切取,如果为2,则表示隔一取一的操作;步长值为正时,表示从左向右取;如果为负,则表示从右向左取;步长值不能为0。
元组
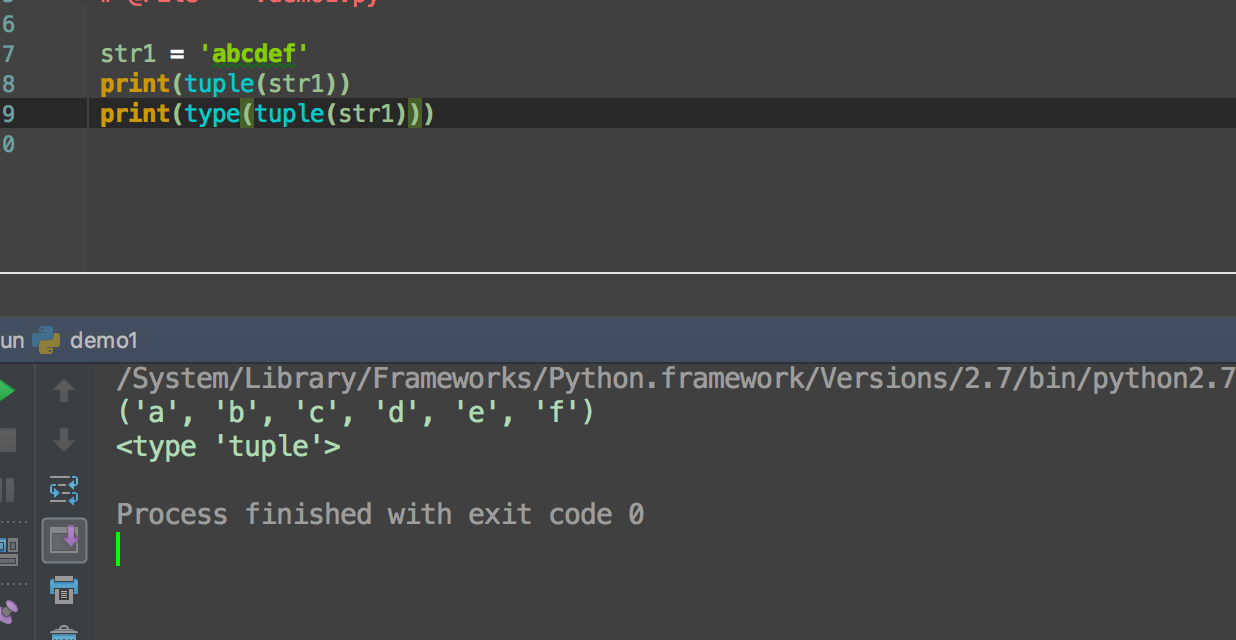
元组是另一个数据类型,类似于List(列表)。
元组用"()"标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
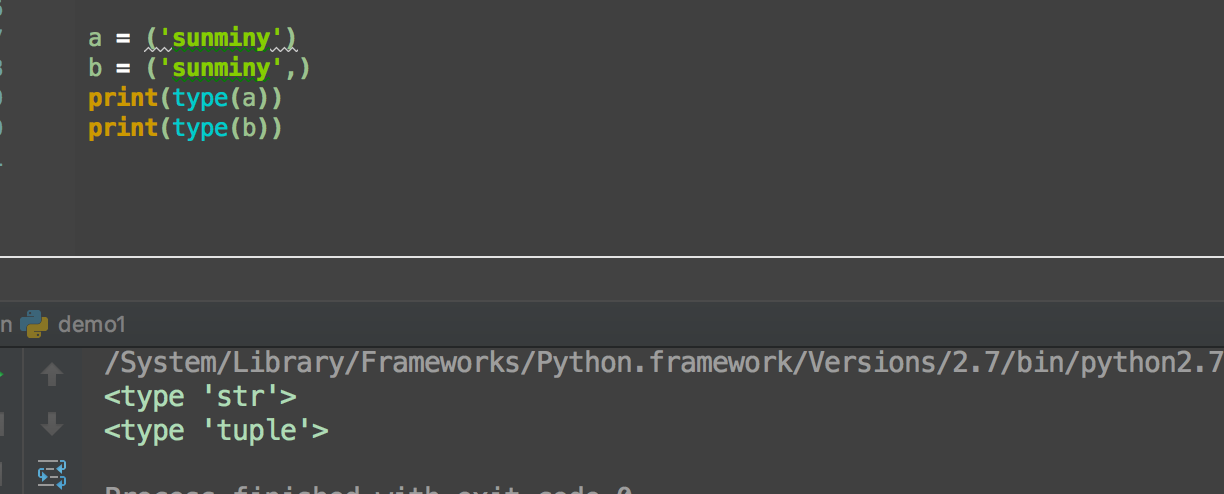
单个tuple时,元素后面需加, ,否则python解析器不会识别tuple类型
tuple 的方法:
count 统计某个元素的数量
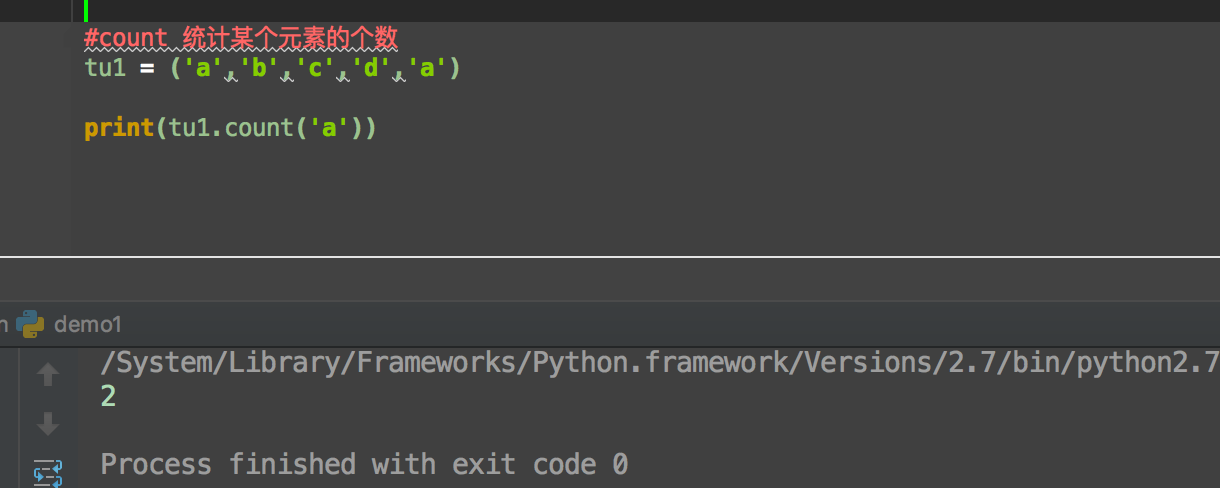
iindex 返回某个元素的下标

字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典的每个键值对(key-value)用:分割,每个对之间用, 分割;字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
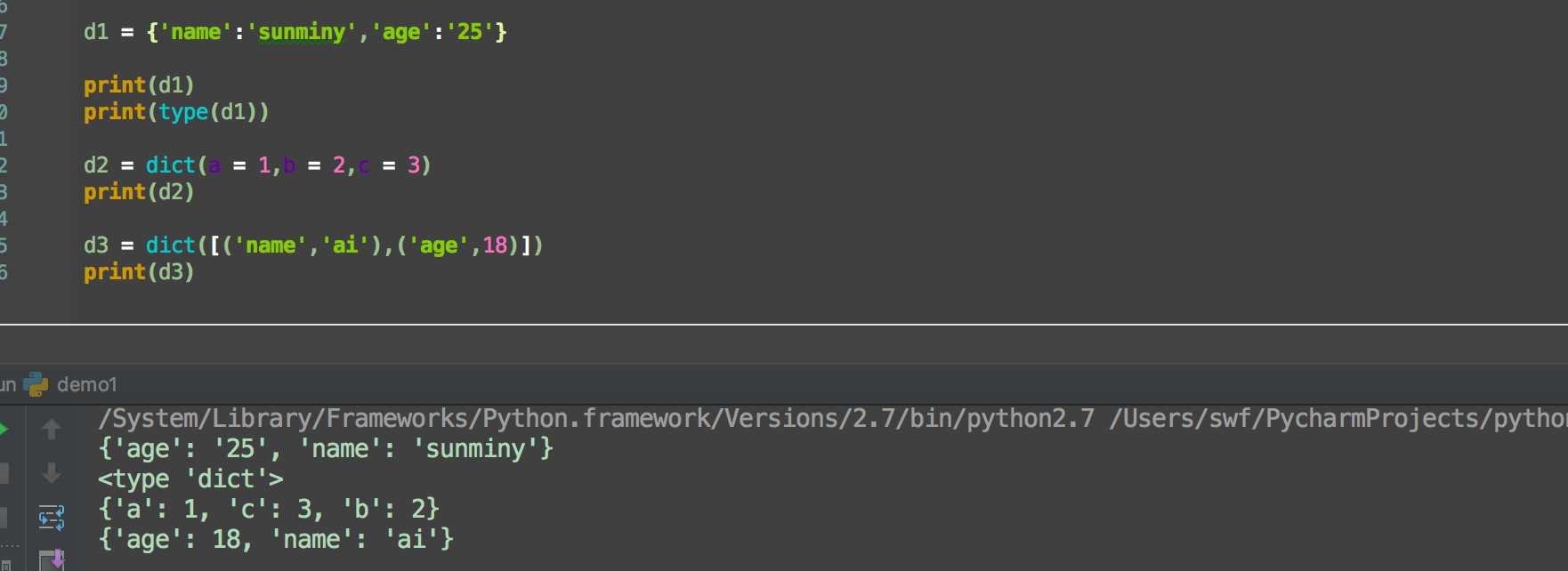
字典的赋值方法有三种:
字典常用的方法:
get 返回指定键的值,如果值不在字典中返回默认值None。

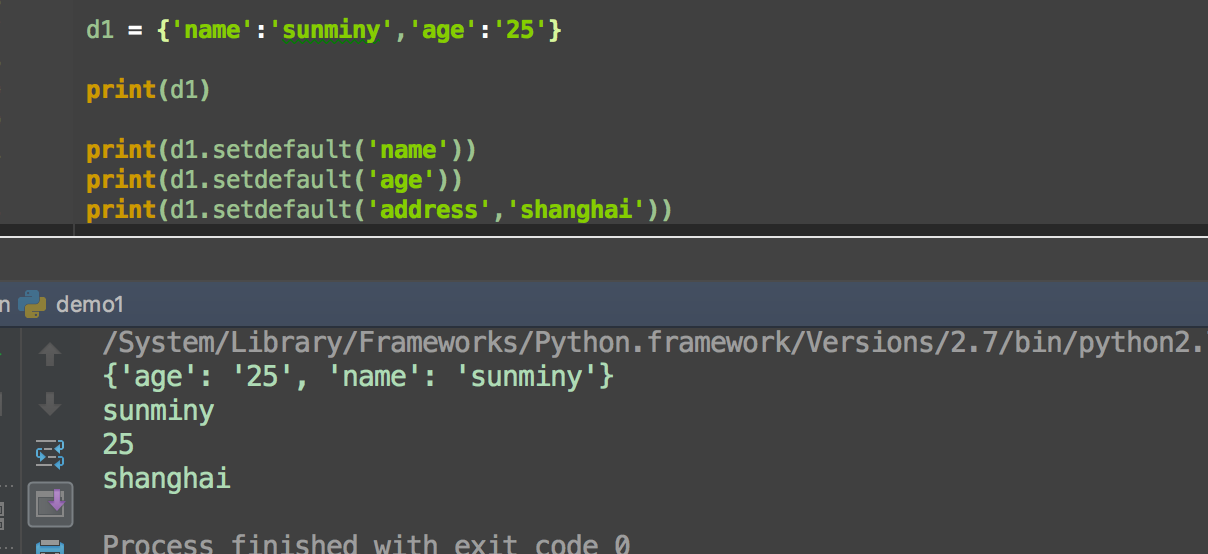
setdefault
如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。
习题:
现有列表 list1 = ['XXXX', 'b', 3, 'c', '&', 'a', 3, '3', 3, 'aa', '3', 'XXXX'] list2 = ['e', 'f', 'g']
要求对其做以下操作:
1. 取出 ‘XXXX’ 中间的部分,形成一个新的列表list3
list3 = list1[1:-1]
print list3
2. 对list3 做一下几部操作
1)删除特殊符号
del list3[4]
print list3
2)统计3 在list3中出现的次数
print list3.count(3)
3)用最简短的代码去除list3中 26个字母以外的元素(要求只能对list3操作)
# ['b', 3, 'c', 3, 'a', 3, '3', 3, 'aa', '3']
list3 = list3[0:5:2]
4)对list3排序
list3.sort()
5)在末尾追加'd',并把list2追加到list3
list3.append('d')
3. 现有两个变量 a = ('h',) b = ('h')
1)将a和b分别追加到上一题的list3中,观察有什么区别
list3.append(a)
list3.append(b)
print list3
2)将1生成的list3转换成元组(扩展:自己搜索方法)
tuple(list3)
3)打印出只有一个元素'h'的元组,在2中生成的元组中的索引
print tuple(list3).index(a)
字典的练习题:
练习: 1. 现有一个字典dict1 保存的是小写字母a-z对应的ASCII码 dict1 = {'a': 97, 'c': 99, 'b': 98, 'e': 101, 'd': 100, 'g': 103, 'f': 102, 'i': 105, 'h': 104, 'k': 107, 'j': 106, 'm': 109, 'l': 108, 'o': 96, 'n': 110, 'q': 113, 'p': 112, 's': 115, 'r': 114, 'u': 117, 't': 116, 'w': 119, 'v': 118, 'y': 121, 'x': 120, 'z': 122}
1) 将该字典按照ASCII码的值排序
import string
dict1 = {'a': 97, 'c': 99, 'b': 98, 'e': 101, 'd': 100, 'g': 103, 'f': 102, 'i': 105, 'h': 104, 'k': 107, 'j': 106, 'm': 109, 'l': 108, 'o': 96, 'n': 110, 'q': 113, 'p': 112, 's': 115, 'r': 114, 'u': 117, 't': 116, 'w': 119, 'v': 118, 'y': 121, 'x': 120, 'z': 122}
print sorted(dict1.iteritems(), key=lambda d:d[1], reverse=False)
2) 有一个字母的ASCII错了,修改为正确的值,并重新排序
dict1['o'] = 111
print sorted(dict1.iteritems(), key=lambda d:d[1], reverse=False)
2. 用最简洁的代码,自己生成一个大写字母 A-Z 及其对应的ASCII码值的字典dict2(使用dict,zip,range方法)
dict2 = dict(zip(string.uppercase,range(65,92)))
print dict2
3. 将dict2与第一题排序后的dict1合并成一个dict3
dict3 = dict(dict1, **dict2)