在很多时候一个表上有一个聚集索引和几个非聚集索引就可以让性能表现的更优秀
一:堆
1.临时对象
最常见的堆应用就是临时对象,由于对象具有临时性特点,因此没必要对其进行聚集索引化,表变量只能在定义时创建聚集索引,定义后就不能单独创建了
--创建临时表 CREATE TABLE #TempWithHeap(SalesOrderID INT); --插入数据,此时是一个堆表 INSERT INTO #TempWithHeap SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE SalesPersonID=283 --开启执行计划,并执行下面语句 SELECT sod. * FROM Sales.SalesOrderDetail sod INNER JOIN #TempWithHeap t ON t.SalesOrderID=sod.SalesOrderID;
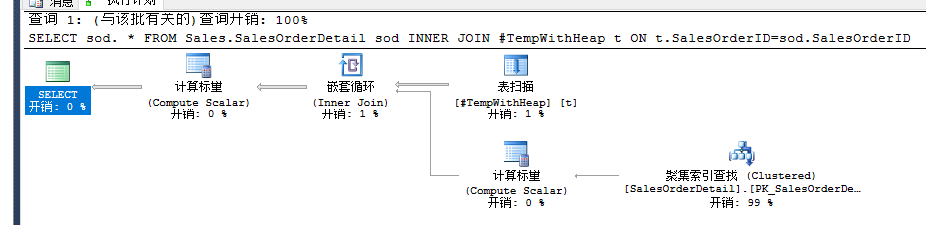
--做少许改动,除了表名和聚集索引外,其他语句和上面一样
--创建临时表 CREATE TABLE #TempWithClusteredIX( SalesOrderID INT PRIMARY KEY CLUSTERED); --插入数据,此时是一个聚集索引表 INSERT INTO #TempWithClusteredIX SELECT SalesOrderID FROM sales.SalesOrderHeader WHERE SalesPersonID=283; --开启执行计划 SELECT sod.* FROM sales.SalesOrderDetail sod INNER JOIN #TempWithClusteredIX t ON t.SalesOrderID=sod.SalesOrderID

使用堆表还是使用具有聚集索引的临时表,基本上没有什么区别。
对于堆表由于EXISTS徐亚预先排序,相对聚集索引来说没有这种特性,所以在堆表中需要额外引入一个排序操作,这和聚集索引表相比,多了一部分的开销
SELECT sod.* FROM sales.SalesOrderDetail sod WHERE EXISTS (SELECT * FROM #TempWithHeap t WHERE t.SalesOrderID=sod.SalesOrderID); SELECT sod.* FROM sales.SalesOrderDetail sod WHERE EXISTS (SELECT * FROM #TempWithClusteredIX t WHERE t.SalesOrderID=sod.SalesOrderID);
带有Exists的临时表执行计划(返回结果集true和false)

聚集索引表的执行计划

2.聚集索引
对聚集索引键值的选择,通常优先考虑下面的类型:
(1)静态,使用静态值,能尽可能使得索引中行的位置不会因为更改而变动。使用了非静态列,非导致数据行在更改时插入到其他页中
(2)窄列,只需要一列作为聚集索引键即可,并且最好使用最小的数据类型
(3)唯一
(自增)
3.非聚集索引
非聚集索引会引用聚集索引的键值或者堆上的行标识符(RID)
创建非聚集索引的时候需要考虑的因素:
(1).非聚集索引键上的更改是否频繁?键值修改越频繁,索引的行位置就变的越频繁。
(2).对于经常执行的查询来说,非聚集索引能使性能提高多少
(3).索引是否支持业务
(4).维护的成本与其给查询带来的好处相比,哪个更好
一.查找列
IF OBJECT_ID(N'Contacts','U') IS NOT NULL
DROP TABLE Contacts
CREATE TABLE dbo.Contacts
(
ContactID INT IDENTITY(1,1),
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
IsActive BIT,
EmailAddress NVARCHAR(50),
CertificationDate CHAR(1000),
CONSTRAINT PK_Contacts PRIMARY KEY CLUSTERED(ContactID)
);
INSERT INTO dbo.Contacts
(
FirstName,
LastName,
IsActive,
EmailAddress,
CertificationDate
)
SELECT pp.FirstName,
pp.LastName,
CASE WHEN pp.BusinessEntityID/10=1 THEN 1 ELSE 0 END,
pea.EmailAddress,
CASE WHEN pp.BusinessEntityID/10=1 THEN pp.ModifiedDate ELSE NULL end
FROM person.Person pp
INNER JOIN Person.EmailAddress pea ON pp.BusinessEntityID=pea.BusinessEntityID
--没有非聚集索引的查询情况
SET STATISTICS IO ON;
SELECT ContactID,FirstName ContactID,FirstName FROM dbo.Contacts WHERE FirstName='Catherine';
SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 2866 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

创建一个非聚集索引:
CREATE INDEX IX_Contacts_FirstName ON dbo.Contacts(FirstName); SET STATISTICS IO ON SELECT ContactID,FirstName FROM dbo.Contacts WHERE FirstName='Catherine' SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

对查找列上加上非聚集索引,通常是提升性能的第一步,它提供了一条高效访问数据的路径。
二:索引交叉
对于SELECT中的一些额外列,如果他们不在聚集索引和创建非聚集索引中,查询就不那么高效了。
SET STATISTICS IO ON SELECT ContactID,FirstName,LastName FROM dbo.Contacts WHERE FirstName='Catherine' AND LastName='Cox'; SET STATISTICS IO OFF;
表 'Contacts'。扫描计数 1,逻辑读取 68 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

额外在LastName列创建一个非聚集索引。
CREATE INDEX IX_Contacts_LastName ON dbo.Contacts(LastName)
SET STATISTICS IO ON
SELECT ContactID,FirstName,LastName FROM dbo.Contacts WHERE FirstName='Catherine' AND LastName='Cox'
SET STATISTICS IO OFF
表 'Contacts'。扫描计数 2,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
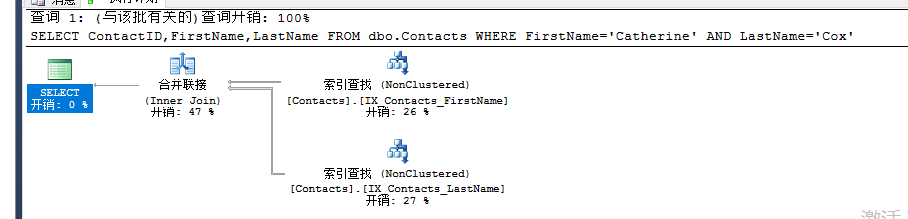
索引交叉方式不需要在索引中定义过多的列,因此统计信息更准确.
三:复合索引
SQL Server的非聚集索引可以包含16列。
CREATE INDEX IX_Contacts_FirstNameLastName ON dbo.Contacts(FirstName,LastName);
SET STATISTICS IO ON
SELECT ContactID,FirstName,LastName FROM dbo.Contacts WHERE FirstName='Catherine' AND LastName='Cox'
SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

4.覆盖索引
覆盖索引也可以算是复合索引的一种,如果一个查询通过索引完全不需要访问底层表,则可以认为是覆盖索引
CREATE INDEX IX_Contacts_FirstNameLastName ON dbo.Contacts(FirstName,LastName);
SET STATISTICS IO ON
SELECT ContactID,FirstName,LastName FROM dbo.Contacts WHERE FirstName='Catherine' AND LastName='Cox'
SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 5 次,物理读取 1 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

将IsActive列添加到索引中,从而减少Select借助聚集索引查找数据
CREATE INDEX IX_Contacts_FirstNameLastNameIsActive ON dbo.Contacts(FirstName,LastName,IsActive) SET STATISTICS IO ON SELECT ContactID,FirstName,LastName,IsActive FROM dbo.Contacts WHERE FirstName='Catherine' AND LastName='Cox' SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

5.包含索引:
允许非键列加到非聚集 索引中,类似于非键值存放在聚集索引上
和覆盖索引的主要区别:
非聚集索引只能定义16列,900bytes,如果列很多,要加入到覆盖索引中,就会导致无法创建,包含索引没有这方面的限制
覆盖索引中的列按定义时的顺序排列,但是包含索引中的列不会排序
没有包含索引的查询语句:
SET STATISTICS IO ON SELECT ContactID,FirstName,LastName,EmailAddress FROM dbo.Contacts WHERE FirstName='Catherine' SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 68 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。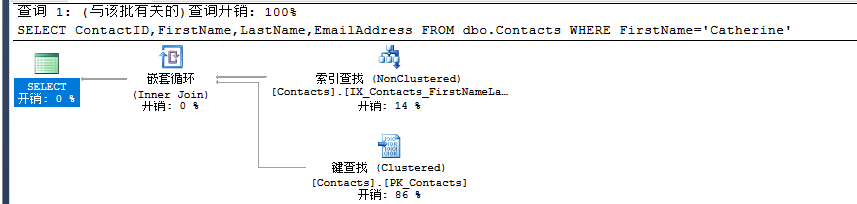
包含索引的查询语句:
CREATE INDEX IX_Contacts_FirstNameINC ON dbo.Contacts(FirstName) INCLUDE (LastName,IsActive,EmailAddress); SET STATISTICS IO ON; SELECT ContactID,FirstName,LastName,EmailAddress FROM dbo.Contacts WHERE FirstName='Catherine' SET STATISTICS IO OFF;
表 'Contacts'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
删除多余的索引:
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id=OBJECT_ID('dbo.Contacts') AND name='IX_Contacts_FirstNameLastName')
DROP INDEX IX_Contacts_FirstNameLastName ON dbo.Contacts
GO
IF EXISTS(SELECT * FROM sys.indexes WHERE object_id=OBJECT_ID('dbo.Contacts') AND name='IX_Contacts_FirstNameLastNameIsActive')
DROP INDEX IX_Contacts_FirstNameLastNameIsActive ON dbo.Contacts
GO
IF EXISTS(SELECT * FROM sys.indexes WHERE object_id=OBJECT_ID('dbo.Contacts') AND name='IX_Contacts_FirstName')
DROP INDEX IX_Contacts_FirstName ON dbo.Contacts
6.筛选索引
可以通过在索引上“移除”这些列值来降低索引的大小,甚至在表关联时也能减少数量级,而这个“移除”动作就是通过筛选索引来实现
SET STATISTICS IO ON
SELECT ContactID,FirstName,LastName,CertificationDate FROM dbo.Contacts WHERE CertificationDate IS NOT NULL
ORDER BY CertificationDate
SELECT ContactID,FirstName,LastName,CertificationDate FROM dbo.Contacts WHERE CertificationDate BETWEEN '20050101' AND '20050201' ORDER BY CertificationDate
SET STATISTICS IO OFF
表 'Contacts'。扫描计数 1,逻辑读取 2866 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Contacts'。扫描计数 1,逻辑读取 2866 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
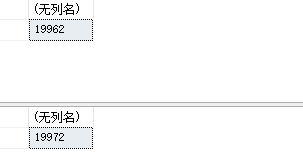
--查看null值 SELECT COUNT(1) FROM dbo.Contacts WHERE CertificationDate IS NULL SELECT COUNT(1) FROM dbo.Contacts
CREATE INDEX IX_Contacts_CertificationDate ON dbo.Contacts(CertificationDate) INCLUDE(FirstName,LastName) WHERE CertificationDate IS NOT NULL
--查询
SET STATISTICS IO ON
SELECT ContactID,FirstName,LastName,CertificationDate FROM dbo.Contacts WHERE CertificationDate IS NOT NULL
ORDER BY CertificationDate
SELECT ContactID,FirstName,LastName,CertificationDate FROM dbo.Contacts WHERE CertificationDate BETWEEN '20050101' AND '20050201'
ORDER BY CertificationDate SET STATISTICS IO OFF
通过减少索引上不必要的行,能从很大程度上降低查询和维护的开销
7.外键
外键用于为两表间的数据提供一致性,它属于数据库设计范畴。
为了提高效率,可以在外键上创建索引。
CREATE TABLE dbo.Customer(
CustomerId INT,
FillterData CHAR(1000),
CONSTRAINT PK_Customer_CustomerID PRIMARY KEY CLUSTERED (CustomerId)
);
CREATE TABLE dbo.SalesOrderHeader(
SalesOrderID INT,
OrderDate DATETIME,
DueDate DATETIME,
CustomerID INT,
FillterData CHAR(1000),
CONSTRAINT PK_SalesOrderHeader_SalesOrderID PRIMARY KEY CLUSTERED (SalesOrderID),
CONSTRAINT GK_SalesOrderHeader_CustomerID_FROM_Customer FOREIGN KEY (CustomerID) REFERENCES dbo.Customer(CustomerId));
--架构不同,可以放心执行,现在插入数据
INSERT INTO dbo.Customer
( CustomerId )
SELECT CustomerID FROM Sales.Customer;
INSERT INTO dbo.SalesOrderHeader(SalesOrderID,OrderDate,DueDate,CustomerID)
SELECT SalesOrderID,OrderDate,DueDate,CustomerID FROM dbo.SalesOrderHeader;
--没有索引的情况
SET STATISTICS IO ON
SELECT MAX(c.CustomerId) FROM dbo.Customer c LEFT OUTER JOIN dbo.SalesOrderHeader soh
ON c.CustomerId=soh.CustomerID WHERE soh.CustomerID IS NULL;
SET STATISTICS IO OFF
SET STATISTICS IO ON
delete FROM dbo.Customer
WHERE CustomerId=701
SET STATISTICS IO OFF
表 'SalesOrderHeader'。扫描计数 1,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'Customer'。扫描计数 1,逻辑读取 2844 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'SalesOrderHeader'。扫描计数 1,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'Customer'。扫描计数 0,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

这个删除操作只影响一行,但是由于有外键关联,导致在dbo.SalesOrderHeader表上产生了很多次逻辑读,这个操作需要通过扫描Customer=701的数据来查找需要删除的数据
--创建一个与外键相关的索引,然后再次删除
CREATE INDEX IS_SalesOrderHeader_CustomerID ON dbo.SalesOrderHeader(CustomerID)
GO
SELECT MAX(c.CustomerId) FROM dbo.Customer c
LEFT OUTER JOIN dbo.SalesOrderHeader soh
ON c.CustomerId=soh.CustomerID
WHERE soh.CustomerID IS NULL;
SET STATISTICS IO ON
DELETE FROM dbo.Customer WHERE CustomerId=608
SET STATISTICS IO OFF
表 'SalesOrderHeader'。扫描计数 1,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'Customer'。扫描计数 0,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
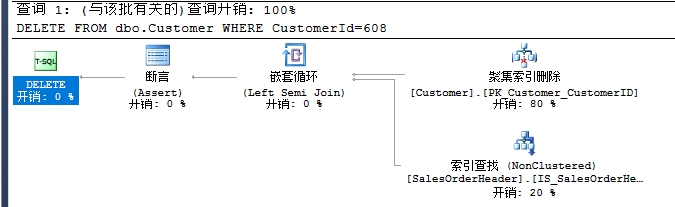
创建索引后,SalesOrderHeader的逻辑读从4000降到2,而且SalesOrderHeader上的聚集索引扫描也变成了索引查找
8.列存储索引
微软从SQL Server 2012开始引入了列存储索引技术,列存储索引有非常特殊的应用情景。
列存储索引主要是数据仓库而设计的,借助列存储和内置压缩,可以不用加载无用的列,从而提高查询的速度。
列存储索引的顺序不重要,每个列都单独存储,在执行查询并组合它们(列)之前,它们之间没有关系
没有列存储时的性能情况
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT dd.CalendarQuarter ,
dpc.ProductCategoryName ,
COUNT(*) AS TotalRows ,
SUM(SalesQuantity) AS TotalSales
FROM dbo.FactSales fs
INNER JOIN dbo.DimDate dd ON fs.DateKey = dd.Datekey
INNER JOIN dbo.DimProduct dp ON fs.ProductKey = dp.ProductKey
INNER JOIN dbo.DimProductSubcategory dps ON dp.ProductSubcategoryKey = dps.ProductSubcategoryKey
INNER JOIN dbo.DimProductCategory dpc ON dps.ProductCategoryKey = dpc.ProductCategoryKey
GROUP BY dd.CalendarQuarter ,
dpc.ProductCategoryName
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
在FactSales表上创建列存储索引
CREATE COLUMNSTORE INDEX IX_FactSales_CStore ON FactSales(SalesKey,DateKey,channelKey,StoreKey,ProductKey,PromotionKey,CurrencyKey, UnitCost,UnitPrice,SalesQuantity,ReturnQuantity,ReturnAmount,DiscountQuantity,DiscountAmount,TotalCost,SalesAmount,ETLLoadID,LoadDate,UpdateDate)
再次执行上面的语句,性能减少了很高