常见的误区:
1.数据库不需要索引
2.主键总是聚集的
3.联机索引操作不引起阻塞
4.复合索引下列的顺序不重要
5.聚集索引以物理顺序存储
6.填充因子可以应用在索引的插入过程中
7.每个表应该有聚集索引
一:数据库不需要索引
--生成堆表
SELECT * INTO MythOne FROM Sales.SalesOrderDetail
--统计查询所用的I/O
SET STATISTICS IO ON
SET NOCOUNT ON
GO
SELECT salesorderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,productID,SpecialOfferID,
UnitPrice,UnitPriceDiscount,LineTotal FROM MythOne WHERE CarrierTrackingNumber='4911-403c-98'
SET STATISTICS IO OFF

在CarrierTrackingNumber创建一个索引,以提高查询性能
CREATE INDEX IX_CarrierTrackingNumber ON mythone(CarrierTrackingNumber)
GO
SET STATISTICS IO ON
SET NOCOUNT ON
GO
SELECT salesorderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,productID,SpecialOfferID,
UnitPrice,UnitPriceDiscount,LineTotal FROM MythOne WHERE CarrierTrackingNumber='4911-403c-98'
GO
SET STATISTICS IO OFF
--表 'MythOne'。扫描计数 1,逻辑读取 15 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
二:主键总是聚集的
当你创建一个主键,默认就会在上面自动创建一个聚集索引,主键的目的是为了保持数据的唯一性、从逻辑上组织数据
--创建测试表
CREATE TABLE dbo.MythoTwo1(
RowID INT NOT NULL,
Column1 NVARCHAR(128),
Column2 NVARCHAR(128)
)
--创建具有聚集特性的主键
ALTER TABLE dbo.MythoTwo1
ADD CONSTRAINT PK_MythoTwo1 PRIMARY KEY (RowID)
GO
CREATE TABLE dbo.MythTwo2(
RowID INT NOT NULL,
Column1 NVARCHAR(128),
Column2 NVARCHAR(128)
)
--先创建聚集索引
CREATE CLUSTERED INDEX INDEX_CL_MythTwo2 ON dbo.MythTwo2(rowid)
--添加主键
ALTER TABLE dbo.MythTwo2
ADD CONSTRAINT PK_MythTwo2 PRIMARY KEY (RowID)
GO
--检查两个表的索引类型
SELECT OBJECT_NAME(object_id) AS table_name,
name, index_id,type,type_desc,is_unique,is_primary_key
FROM sys.indexes
WHERE OBJECT_ID IN (OBJECT_ID('dbo.MythoTwo1'),OBJECT_ID('dbo.MythoTwo2'))

MythoTwo1只有一个聚集索引,并且是唯一的(is_unique)和聚集的(is_primary_key);而MythoTwo2上有两个索引,一个是单纯的聚集索引,一个是唯一且为主键的非聚集索引
3.联机索引操作不引起阻塞
SQL Server 会在表中受联机索引操作影响的数据上加上意向共享锁,并在最终更新原有索引时对这部分数据架构更新锁或者共享锁,然后阻塞其他事务的修改操作
4.复合索引下,列的顺序不重要
一个索引通常不会使用到表中的所有列,并且列的顺序也是有意义的,复合索引中最左的一列有统计信息,其他列不计算统计信息,这就说明索引的列是有顺序,而且非常重要。
--创建表
SELECT SalesOrderID,orderdate,DueDate,ShipDate
INTO dbo.MythFour
FROM Sales.SalesOrderHeader;
--添加一个聚集索引
ALTER TABLE dbo.mythFour
ADD CONSTRAINT PK_MythFour PRIMARY KEY CLUSTERED(SalesOrderID);
--添加由三列组成的非聚集索引
CREATE NONCLUSTERED INDEX IX_MythFour ON dbo.MythFour(orderdate,DueDate,ShipDate);
--执行查询索引最左边
SELECT orderdate FROM dbo.MythFour WHERE orderdate='2008-07-17 00:00:00.000'
--使用索引最右边
SELECT orderdate FROM dbo.MythFour WHERE ShipDate='2008-07-17 00:00:00.000'
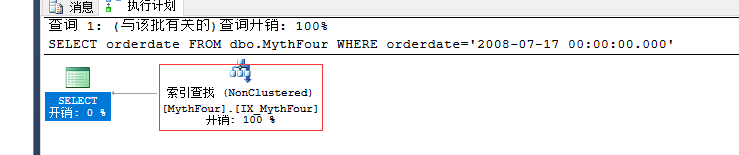

一个是索引扫描,一个是索引查找,因为前面已经说过,除了索引最左侧的列有统计信息之外,其他列没有,所以用其他列,SQLServer 无法预估行数,只能使用扫描来遍历索引
5.聚集索引以物理顺序存储
--创建测试表
CREATE TABLE dbo.MythFive
(
rowid INT PRIMARY KEY CLUSTERED,
TestValue VARCHAR(20) NOT NULL
)
INSERT INTO dbo.MythFive(rowid,TestValue)
VALUES(1,'FirstRecordAdded');
INSERT INTO dbo.MythFive(rowid,TestValue)
VALUES(3,'SecondRecordAdded');
INSERT INTO dbo.MythFive(rowid,TestValue)
VALUES(2,'ThirdRecordAdded');
--检查索引情况
DBCC IND ('AdventureWorks2014','dbo.MythFive',1)
MythFive的索引情况:
检查PageType=1即数据页的情况
DBCC TRACEON(3604);
GO
DBCC PAGE(AdventureWorks2014,1,140107,2)
聚集索引并不是按物理顺序存放数据
6.填充因子可以应用在索引的插入过程中
填充因子用于创建(不是指第一次初始化,而是使用create index with drop_existing这种方式,第一次初始化的时候会尽量填满页)、重建或者重组索引。
--创建测试表
CREATE TABLE dbo.MythSix
(
RowID INT NOT NULL,
Columnl VARCHAR(500)
);
--创建聚集索引,填充因子为50,即只填满页的一半就是分页
ALTER TABLE dbo.MythSix ADD CONSTRAINT
PK_MythSix PRIMARY KEY CLUSTERED (RowID) WITH(FILLFACTOR=50);
--制造测试数据
WITH L1(z) AS (SELECT 0 UNION ALL SELECT 0)
, L2(z) AS (SELECT 0 FROM L1 a CROSS JOIN L1 b)
, L3(z) AS (SELECT 0 FROM L2 a CROSS JOIN L2 b)
, L4(z) AS (SELECT 0 FROM L3 a CROSS JOIN L3 b)
, L5(z) AS (SELECT 0 FROM L4 a CROSS JOIN L4 b)
, L6(z) AS (SELECT TOP 1000 0 FROM L5 a CROSS JOIN L5 b)
INSERT INTO dbo.MythSix
SELECT ROW_NUMBER() OVER(ORDER BY z) AS RowID,REPLICATE('X',500) FROM L6
--检查索引的可用情况
SELECT object_id,index_id,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.MythSix'),NULL,NULL,'DETAILED') WHERE index_level=0
执行结果:

可用空间并不是50,可见填充因子在插入时并未起作用。实际上,插入数据时,SQL Server依旧会尽量填满一页在分配新页。为了证明在重建、重组时填充因子会起作用。可以重建这个表
ALTER TABLE dbo.MythSix rebuild

这时候填充因子才生效,但这些配置并不是绝对的,也就是说不一定设了50就真的是正好50
7.每个表应该有聚集索引
不使用聚集索引的理由:
1.碎片问题增加I/O操作
2.当因为数据修改而产生page split时,会引起聚集索引上多条记录位置变更
3.过渡的key lookup会引起额外的I/O开销,这通常是索引设计的问题
不使用堆的理由:
1.过多的forwarded records会导致额外的I/O,降低性能
2.没有办法通过移除forwarded records来维护堆表
3.非聚集索引往往可能要进行多余的排序操作
选择是否用聚集索引时,可以考虑以下几点:
1.表上是否有唯一、自增的键值。
2.表上是否有高度唯一的列
3是否经常有范围查询
堆表可以比聚集索引更好的性能表现:
1.高频率的增删操作
2.键值经常改变,特别是索引上的位置改变
3.插入大量数据到列中
4.主键值并不自增或者唯一
索引使用建议
1.保留主键创建中的聚集索引选项
由于聚集索引合适建立在唯一、自增的列或者多列上而这些特性在主键中能够得到满足,所以SQL Server 创建主键时默认就是聚集索引。
2.平衡索引的个数
3.填充因子
(1)数据库层面的填充因子用于控制索引创建、维护过程中索引页保留空余空间的默认值。往往数据库层面的填充因子不建议修改,如有必要,可以修改索引层面上的填充因子
(2)如果索引上存在严重的碎片问题,在索引层面上调整填充因子可以在一定程度上减少碎片问题
4.在外键列加索引
创建外键列后,强烈建议在外键列上加索引,这可以帮助父表和子表关联时提高性能
关于索引的查询建议
1.Like 把like 的这列数据进行索引化,把核心的数据或者常用数据当成一个列
SET STATISTICS IO ON ; SELECT AddressID,AddressLine1,AddressLine2,City,StateProvinceID,PostalCode FROM Person.Address WHERE AddressLine1 LIKE '%Cynthia%'

表 'Address'。扫描计数 1,逻辑读取 216 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
创建一个全文索引:
CREATE FULLTEXT CATALOG ftQueryStrategies AS DEFAULT; CREATE FULLTEXT INDEX ON person.Address(AddressLine1) KEY INDEX PK_Address_AddressID; GO SET STATISTICS IO ON; SELECT AddressID,AddressLine1,AddressLine2,City,StateProvinceID,PostalCode FROM Person.Address WHERE CONTAINS (AddressLine1,'Cynthia')
表 'Address'。扫描计数 0,逻辑读取 12 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

串联:
在查询过程中,很多时候需要把某些列串联起来作为新列,特别是在where条件中,使用了FirstName+LastName=‘***’,会导致索引无效
SET STATISTICS IO ON;
CREATE INDEX IX_PersonContact_FirstNameLastName ON Person.Person(FirstName,LastName)
GO
SELECT BusinessEntityID,FirstName,LastName FROM Person.Person WHERE FirstName+' '+ LastName='Gustavo Achong'
表 'Person'。扫描计数 1,逻辑读取 99 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

有两种解决方案:
1.使用计算列,把两个列上的值预先存储,然后在计算列上加上索引
2.改写查询
--使用计算列 ALTER TABLE Person.Person ADD Name AS Firstname+''+ lastname CREATE NONCLUSTERED INDEX IX_PersonContact_Name ON Person.Person(Name)
--用新列查询 SET STATISTICS IO ON; SELECT BusinessEntityID,FirstName,LastName FROM Person.Person WHERE name='Gustavo Achong'
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Person'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
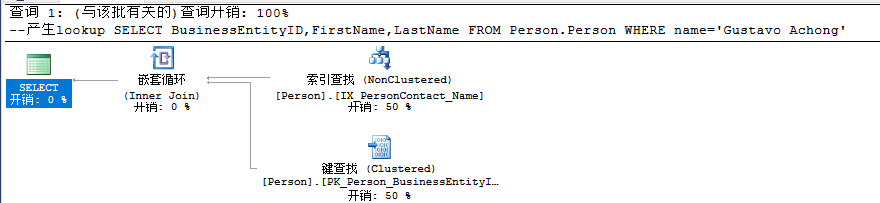
--第二种情况 DROP INDEX IX_PersonContact_Name ON Person.Person SET STATISTICS IO ON ; SELECT BusinessEntityID,FirstName,LastName FROM Person.Person WHERE FirstName='Gustavo' AND LastName='Achong'
表 'Person'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

3.标量函数
使用函数,特别是where条件和on条件中使用标量函数,也会对索引带来影响。标量函数会使列上的值在查询过程中“变成”另一个值,索引上面的统计信息就会失效,进而导致优化器选择扫描操作
SELECT BusinessEntityID,FirstName,LastName FROM person.Person WHERE FirstName='Gustavo' SELECT BusinessEntityID,FirstName,LastName FROM Person.Person WHERE UPPER(FirstName)='Gustavo'


4.数据类型转换
--4.数据类型转换
--创建示例表
SELECT BusinessEntityID
,CAST(FirstName AS VARCHAR(50)) AS FirstName
,CAST(MiddleName AS VARCHAR(50)) AS MiddleName
,CAST(LastName AS VARCHAR(50)) AS LastName
INTO PersonPerson
FROM Person.Person;
CREATE CLUSTERED INDEX IX_PersonPerson_ContactID ON PersonPerson(BusinessEntityID);
GO
SET STATISTICS IO ON
DECLARE @FirstName nvarchar(100) --注意类型
SET @FirstName ='Katherine';
--提高带参数执行SQL语句的索引效率 OPTION(RECOMPILE)
SELECT * FROM PersonPerson WHERE @FirstName=@FirstName OPTION(RECOMPILE);
GO
DECLARE @FirstName VARCHAR(100)--注意类型型,这里不存在类型转换,均为varchar
SET @FirstName='Katherine';
SELECT * FROM PersonPerson
WHERE FirstName=@FirstName
表 'PersonPerson'。扫描计数 1,逻辑读取 89 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
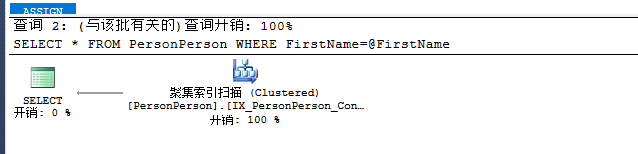
数据类型转换和标量函数的影响类似,都会使得统计信息丢失,从而使索引无效,所以应该尽可能保持WHERE、ON条件两边的类型相等。