使用ES不久,今天发现生产环境数据异常,其使用的ES版本是2.1.2,其它版本也类似。通过使用ES的HTTP API进行查询,发现得到的数据跟javaClient API 查询得到的数据不一致,于是对代码逻辑以及ES查询工具产生了怀疑。通过查阅官方文档找到如下描述:
Precision controledit
This aggregation also supports the
precision_thresholdoption:The
precision_thresholdoption is specific to the current internal implementation of thecardinalityagg, which may change in the future{ "aggs" : { "author_count" : { "cardinality" : { "field" : "author_hash", "precision_threshold": 100} } } }
The
precision_thresholdoptions allows to trade memory for accuracy, and defines a unique count below which counts are expected to be close to accurate. Above this value, counts might become a bit more fuzzy. The maximum supported value is 40000, thresholds above this number will have the same effect as a threshold of 40000. Default value depends on the number of parent aggregations that multiple create buckets (such as terms or histograms).Counts are approximateedit
Computing exact counts requires loading values into a hash set and returning its size. This doesn’t scale when working on high-cardinality sets and/or large values as the required memory usage and the need to communicate those per-shard sets between nodes would utilize too many resources of the cluster.
This
cardinalityaggregation is based on the HyperLogLog++ algorithm, which counts based on the hashes of the values with some interesting properties:
- configurable precision, which decides on how to trade memory for accuracy,
- excellent accuracy on low-cardinality sets,
- fixed memory usage: no matter if there are tens or billions of unique values, memory usage only depends on the configured precision.
For a precision threshold of
c, the implementation that we are using requires aboutc * 8bytes.The following chart shows how the error varies before and after the threshold:
For all 3 thresholds, counts have been accurate up to the configured threshold (although not guaranteed, this is likely to be the case). Please also note that even with a threshold as low as 100, the error remains under 5%, even when counting millions of items.
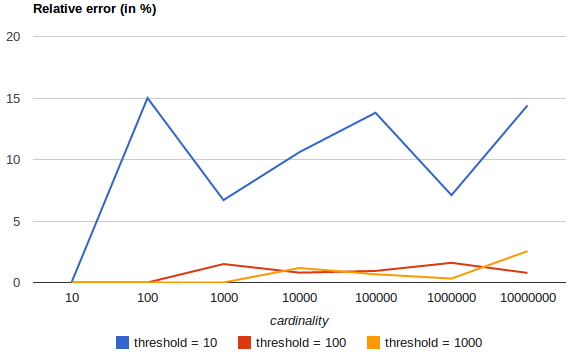
其意思就是:聚合查询存在误差,在5%范围之内,通过调整“precision_threshold”参数进行调整。
于是翻阅查询代码:加入如下部分问题得到解决。该参数在查询时未设置的情况下,默认值为3000。
private void buildSearchQueryForAgg(NativeSearchQueryBuilder nativeSearchQueryBuilder) {
// 设置聚合条件
TermsBuilder agg = AggregationBuilders.terms(aggreName).field(XXX.XXX).size(Integer.MAX_VALUE);
// 查询条件构建
BoolQueryBuilder packBoolQuery = QueryBuilders.boolQuery();
FilterAggregationBuilder packAgg = AggregationBuilders.filter(xxx).filter(packBoolQuery);
packAgg.subAggregation(AggregationBuilders.cardinality(xxx).field(ZZZZ.XXX).precisionThreshold(CARDINALITY_PRECISION_THRESHOLD));//指定精度值
agg.subAggregation(packAgg);
nativeSearchQueryBuilder.addAggregation(agg);
}