一、疑问&目的
1.1 分表使用场景
(1)可扩展架构设计,比如一个ERP用5年不卡,到了10就卡了因为数据太多了,这个时候很多人都是备份然后清空数据,这个工作大并且麻烦,以前的数据很难在使用
(2) 数据量太多 ,例如每天都有 几十上百万的数据进入库,如果不分表后面查询将会非常缓慢
(3) 性能瓶颈 ,数据库现有数据超过1个亿,很多情况下索引会莫名失效,性能大大下降,如果使用分表,我们只需要针对一个分表进行操作性能大大提升
1.2 我的目的
说到ORM很多会想到EF Core Dapper SqlSugar Chloe Freesql等,但是说到分表组件或许者大家想不到一个名词
我写这一篇文章最大的目的是想大家记住 全自动的分表组件 【 SqlSugar 】
没错SqlSugar是一个ORM框架,并且已经完美支持了自动分表 ,希望你能喜欢
二、SqlSugar分表优势
2.1 简单
CURD和分表一体化 ,小白也能很好的使用分表,只要会使用 ORM 就会使用分表 ,2者语法同步 就多 一个 .SplitTable
2.2 功能强大
支持 表结构同步,自动建表,强大的查询语句,插入,更新,删除
2.3 组件化设计
默认集成了按 日、周、月、季、年的方式表, 比如,我想根据加密算法分表,或者根据多个字段分表,或者不满意现在的分表 都可以已扩展实现
三、 自带分表的使用
自带分表支持按年、按月、按日、按季、按周进行分表
3.1 定义实体
我们定义一个实体,主键不能用自增或者int ,设为long或者guid都可以,我例子就用自带的雪花ID实现分表
[SplitTable(SplitType.Year)]//按年分表 (自带分表支持 年、季、月、周、日)
[SugarTable("SplitTestTable_{year}{month}{day}")]//生成表名格式 3个变量必须要有
public class SplitTestTable
{
[SugarColumn(IsPrimaryKey =true)]
public long Id { get; set; }
public string Name { get; set; }
[SplitField] //分表字段 在插入的时候会根据这个字段插入哪个表,在更新删除的时候也能可方便的用这个字段找出相关表
public DateTime CreateTime { get; set; }
}
3.2 初始化和同步结构
(1)如果一张表没有 查询肯定会报错,所以程序启动时需要建一张表
(2)假如分了20张表,实体类发生变更,那么 20张表可以自动同步结构,与实体一致
db.CodeFirst.SplitTables().InitTables<SplitTestTable>(); //程序启动时加这一行
3.2 查询用法
(1)按时间自动过滤
通过开始时间和结束时间自动生成CreateTime的过滤并且找到对应时间的表
var lis2t = db.Queryable<OrderSpliteTest>() .SplitTable(DateTime.Now.Date.AddYears(-1), DateTime.Now) .ToOffsetPage(1,2);
(2)精准筛选
根据分表字段的值可以精准的定位到具体是哪一个分表
比Take(N)性能要高出很多
var name=Db.SplitHelper<SplitTestTable>().GetTableName(data.CreateTime); Db.Queryable<SplitTestTable>().Where(it => it.Id==data.Id).SplitTable(tas => tas.InTableNames(name)).ToList();
(3)表达式过滤
Db.Queryable<SplitTestTable>().Where(it => it.Id==data.Id).SplitTable(tas => tas.Where(y=>y.TableName.Contains("2019"))).ToList();
(4) 联表查询
//分表使用联表查询
var list=db.Queryable<Order>()
.SplitTable(tabs=>tabs.Take(3))//Order表只取最近3张表和Custom JOIN
.LeftJoin<Custom>((o,c)=>o.CustomId==c.Id).Select((o,c)=>new { name=o.Name,cname=c.Name }).ToPageList(1,2);
(5) 分页查询
var count = 0;
db.Queryable<SplitTestTable>().Where(it => it.Name.Contains("a")).SplitTable(tas => tas.Take(3)).ToPageList(1,2,ref count);//
3.3 插入
因为我们用的是Long所以采用雪ID插入(guid也可以禁止使用自增列), 实体结构看上面 3.1
var data = new SplitTestTable()
{
CreateTime=Convert.ToDateTime("2019-12-1"),
Name="jack"
};
db.Insertable(data).SplitTable().ExecuteReturnSnowflakeId();//插入并返回雪花ID
因为我们是根据CreateTime进行的分表,生成的SQL语句如下:
INSERT INTO [SplitTestTable_20190101] --如果表不存在会自动建表
([Id],[Name],[CreateTime])
VALUES
(@Id,@Name,@CreateTime) ;
批量插入
var datas = new List<SplitTestTable>(){new SplitTestTable(){CreateTime=Convert.ToDateTime("2019-12-1"),Name="jack"} ,
new SplitTestTable(){CreateTime=Convert.ToDateTime("2022-02-1"),Name="jack"},
new SplitTestTable(){CreateTime=Convert.ToDateTime("2020-02-1"),Name="jack"},
new SplitTestTable(){CreateTime=Convert.ToDateTime("2021-12-1"),Name="jack"}};
db.Insertable(datas).SplitTable().ExecuteReturnSnowflakeIdList();//插入返回雪花ID集合
执行完生成的表
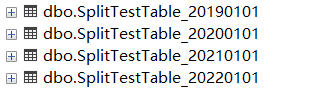
生成的Sql:
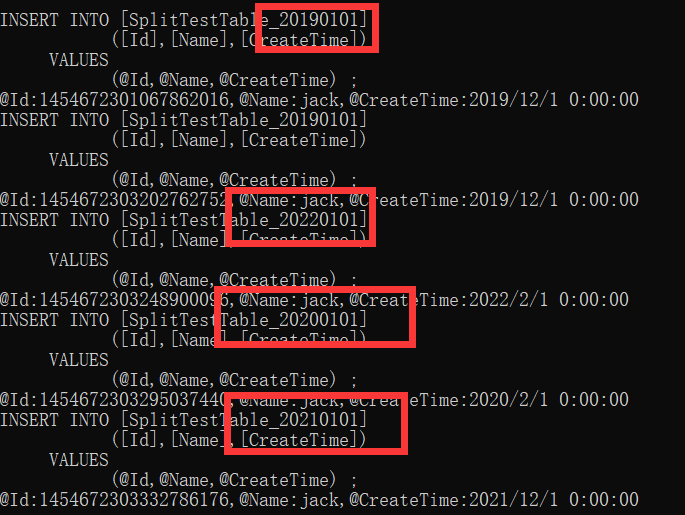
自动识别4条记录,分别插入4个不同的表中
3.4 删除数据
(1)懒人模式删除
最近3张表都执行一遍删除
db.Deleteable<SplitTestTable>().In(id).SplitTable(tas=>tas.Take(3)).ExecuteCommand();
生在的SQL如下:
DELETE FROM [SplitTestTable_20220101] WHERE [Id] IN (1454675372531515392) DELETE FROM [SplitTestTable_20210101] WHERE [Id] IN (1454675372531515392) DELETE FROM [SplitTestTable_20200101] WHERE [Id] IN (1454675372531515392)
(2)精准删除
相对于上面的操作性能更高,可以精准找到具体表
var deldata = new SplitTestTable()
{
Id = id,
CreateTime = DateTime.Now
};
var tableName = db.SplitHelper(deldata).GetTableNames();
db.Deleteable<SplitTestTable>().Where(deldata).SplitTable(tas=>tas.InTableNames(tableName)).ExecuteCommand();
生成的SQL如下:
DELETE FROM [SplitTestTable_20210101] WHERE [Id] IN (1454676863531089920)
3.5 更新数据
更新的用法基本上和删除一样
//更新近3张表
db.Updateable(deldata).SplitTable(tas=>tas.Take(3)).ExecuteCommand();
//精准找到表名并且更新数据
var tableName = db.SplitHelper(deldata).GetTableNames();
db.Updateable(deldata).SplitTable(tas => tas.InTableNames(tableName)).ExecuteCommand();
//通过表达式过滤出要更新的表
db.Updateable(deldata).SplitTable(tas => tas.Where(y=>y.TableName.Contains("_2019"))).ExecuteCommand();
四、 自定义分表使用
上面的分表功能是我们自带集成的,比如我想实现自定义的分表我该如何实现呢?
4.1 按首字母拼音分表
我们就写个按24个字母进行分表的小例子,来学习一下如何自定义分表
4.2 创建分表类
我们新建一个类继承成ISplitTableService 接口
public class WordSplitService : ISplitTableService
{
/// <summary>
/// 返回数据用于 tas 进行筛选
/// </summary>
/// <param name="db"></param>
/// <param name="EntityInfo"></param>
/// <param name="tableInfos"></param>
/// <returns></returns>
public List<SplitTableInfo> GetAllTables(ISqlSugarClient db, EntityInfo EntityInfo, List<DbTableInfo> tableInfos)
{
List<SplitTableInfo> result = new List<SplitTableInfo>();
foreach (var item in tableInfos)
{
if (item.Name.Contains(EntityInfo.DbTableName+"_First")) //区分标识如果不用正则符复杂一些,防止找错表
{
SplitTableInfo data = new SplitTableInfo()
{
TableName = item.Name //要用item.name不要写错了
};
result.Add(data);
}
}
return result.OrderBy(it=>it.TableName).ToList();
}
/// <summary>
/// 获取分表字段的值
/// </summary>
/// <param name="db"></param>
/// <param name="entityInfo"></param>
/// <param name="splitType"></param>
/// <param name="entityValue"></param>
/// <returns></returns>
public object GetFieldValue(ISqlSugarClient db, EntityInfo entityInfo, SplitType splitType, object entityValue)
{
var splitColumn = entityInfo.Columns.FirstOrDefault(it => it.PropertyInfo.GetCustomAttribute<SplitFieldAttribute>() != null);
var value = splitColumn.PropertyInfo.GetValue(entityValue, null);
return value;
}
/// <summary>
/// 默认表名
/// </summary>
/// <param name="db"></param>
/// <param name="EntityInfo"></param>
/// <returns></returns>
public string GetTableName(ISqlSugarClient db, EntityInfo entityInfo)
{
return entityInfo.DbTableName + "_FirstA";
}
public string GetTableName(ISqlSugarClient db, EntityInfo entityInfo, SplitType type)
{
return entityInfo.DbTableName + "_FirstA";//目前模式少不需要分类(自带的有 日、周、月、季、年等进行区分)
}
public string GetTableName(ISqlSugarClient db, EntityInfo entityInfo, SplitType splitType, object fieldValue)
{
return entityInfo.DbTableName + "_First" + GetFirstCode(fieldValue+""); //根据值按首字母
}
#region 获取首字母
/// <summary>
/// 在指定的字符串列表CnStr中检索符合拼音索引字符串
/// </summary>
/// <param name="CnStr">汉字字符串</param>
/// <returns>相对应的汉语拼音首字母串</returns>
private static string GetFirstCode(string CnStr)
{
string Surname = CnStr.Substring(0, 1);
string strTemp = GetSpellCode(Surname);
return strTemp;
}
/// <summary>
/// 得到一个汉字的拼音第一个字母,如果是一个英文字母则直接返回大写字母
/// </summary>
/// <param name="CnChar">单个汉字</param>
/// <returns>单个大写字母</returns>
private static string GetSpellCode(string CnChar)
{
long iCnChar;
byte[] arrCN = System.Text.Encoding.Default.GetBytes(CnChar);
//如果是字母,则直接返回
if (arrCN.Length == 1)
{
CnChar = CnChar.ToUpper();
}
else
{
int area = (short)arrCN[0];
int pos = (short)arrCN[1];
iCnChar = (area << 8) + pos;
// iCnChar match the constant
string letter = "ABCDEFGHJKLMNOPQRSTWXYZ";
int[] areacode = { 45217, 45253, 45761, 46318, 46826, 47010, 47297, 47614, 48119, 49062, 49324, 49896, 50371, 50614, 50622, 50906, 51387, 51446, 52218, 52698, 52980, 53689, 54481, 55290 };
for (int i = 0; i < 23; i++)
{
if (areacode[i] <= iCnChar && iCnChar < areacode[i + 1])
{
CnChar = letter.Substring(i, 1);
break;
}
}
}
return CnChar;
}
#endregion
}
4.2 创建实体类
/// <summary>
/// 随便设置一个分类
/// </summary>
[SplitTable(SplitType._Custom01)]
public class WordTestTable
{
[SugarColumn(IsPrimaryKey =true)]
public long Id { get; set; }
[SplitField] //标识一下分表字段
public string Name { get; set; }
public DateTime CreateTime { get; set; }
}
4.3 使用自定义分表
代码:
//使用自定义分表
db.CurrentConnectionConfig.ConfigureExternalServices.SplitTableService =new WordSplitService();
//插入数据
db.Insertable(new WordTestTable(){CreateTime=DateTime.Now,Name="BC"}).SplitTable().ExecuteReturnSnowflakeId();
db.Insertable(new WordTestTable(){CreateTime = DateTime.Now,Name = "AC"}).SplitTable().ExecuteReturnSnowflakeId();
db.Insertable(new WordTestTable(){ CreateTime = DateTime.Now, Name = "ZBZ"}).SplitTable().ExecuteReturnSnowflakeId();
执行完数据库就多了3张表,因为是按首字母分的表 ,插入了3条记录自动创建了3张表

插入生成的SQL:
INSERT INTO [WordTestTable_FirstB]
([Id],[Name],[CreateTime])
VALUES
(@Id,@Name,@CreateTime) ;
INSERT INTO [WordTestTable_FirstA]
([Id],[Name],[CreateTime])
VALUES
(@Id,@Name,@CreateTime) ;
INSERT INTO [WordTestTable_FirstZ]
([Id],[Name],[CreateTime])
VALUES
(@Id,@Name,@CreateTime) ;
查询指定表
var listall = db.Queryable<WordTestTable>().Where(it => it.Name == "all").SplitTable(tas => tas.ContainsTableNames("_FirstA")).ToList();
生成的SQL:
SELECT * FROM (SELECT [Id],[Name],[CreateTime] FROM [WordTestTable_FirstA] WHERE ( [Name] = @Name0UnionAll1 )) unionTable
SqlSugar ORM 新语法
需要 NUGET安装 SqlSugarCore 5.0.4.3-proview-03
以前有些人说SQLSUGAR联表不优美,所以我也支了最优美联表语法:
新语法1:
简单的联表
var leftQueryable = db.Queryable<Custom>()
.LeftJoin<OrderItem>((c, i) => c.Id == i.ItemId)
.Select(c =>c).ToList();
SQL如下:
SELECT c.* FROM [Custom] c Left JOIN [OrderDetail] i ON ( [c].[Id] = [i].[ItemId] )
新语法2:
表 和 Queryable 进行联表
var rigtQueryable = db.Queryable<Custom>()
.LeftJoin<OrderItem>((o, i) => o.Id == i.ItemId)
.Select(o => o);
var List = db.Queryable<Order>()
.LeftJoin(rigtQueryable, (c, j) => c.CustomId == j.Id)
.Select(c => c).ToList();
SQL如下:
SELECT c.* FROM [Order] c Left JOIN (SELECT o.* FROM [Custom] o Left JOIN [OrderDetail] i ON ( [o].[Id] = [i].[ItemId] ) ) j ON ( [c].[CustomId] = [j].[Id] )
新语法3
Queryable 和表 进行联表
var leftQueryable = db.Queryable<Custom>()
.LeftJoin<OrderItem>((c, i) => c.Id == i.ItemId)
.Select(c =>c) ;
var List = db.Queryable(leftQueryable)
.LeftJoin<Order>((o, cu) => o.Id == cu.Id)
.Select(o => o).ToList();
SQL如下:
SELECT o.* FROM (SELECT * FROM (SELECT c.* FROM [Custom] c Left JOIN [OrderDetail] i ON ( [c].[Id] = [i].[ItemId] ) ) t ) o Left JOIN [Order] cu ON ( [o].[Id] = [cu].[Id] )
总结
SqlSugar 一直在创新,并且越来越好,相信分表功能,新的语法一定会让很多人喜欢
源码下载:
https://github.com/donet5/SqlSugar 没点关注的点一波关注 ,你们的赞或者一个star就是我们这些开源些的动力
Nuget 安装
