结论:
1. 数组查询快, 链表增删快
2. hash(散列)算法使得数据成散列分布, 插入和取出两次计算确定位置, 可能发生碰撞
3. 集合长度是可变的
根据结论可以得到如下推论:
1. 哈希(散列)表是数组和链表的组合, 不仅查询快, 而且增删快
2. 确保元素唯一的时, 先比较 hashCode(), 再比较 equals()
3. 解释了 ArrayList 和 HashMap 有自动扩容机制
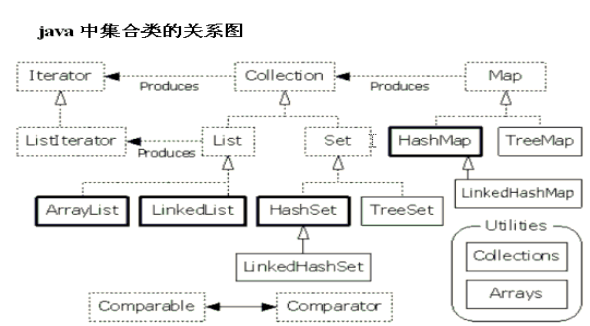
集合
|--Collection
|--List
|--ArrayList: 底层数组, 线程不同步, 查询快
|--LinkedList: 底层链表, 线程不同步, 增删快
|--Vector: 底层数组, 线程同步, 查询增删都慢
|--Set(底层使用的 Map 集合)
|--HashSet: 底层 hash 表, 线程不同步, 无序
|--LinkedHashSet: 有序
|--TreeSet: 底层红黑树, 线程不同步, 元素排序
|--Map
|--HashMap: 底层 hash 表, 线程不同步, K-V 可为null
|--Hashtable: 底层哈希表, 线程同步, K-V 不可为null
|--TreeMap: 底层红黑树, 指定的 K 顺序排序
ArrayList
|--源码 add() 没有 synchronized 关键字, 因而线程不同步
|--初始大小为10, 容量不够则扩容为原来的1.5倍(>>1相当于 /2)


HashSet
|--源码 add() 没有 synchronized 关键字, 因而线程不同步
|--底层调用的 Map 集合的 put()
|--K 已存在, 新 V 替旧 V, 元素不重复

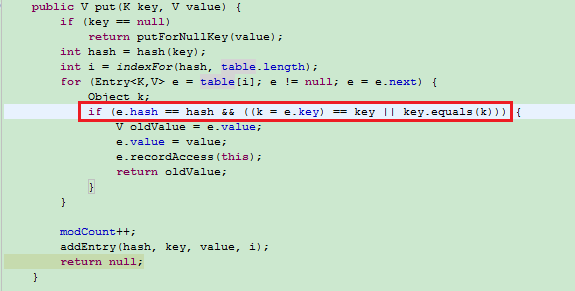
HashMap
|--源码 put() 没有 synchronized 关键字, 因而线程不同步
|--先比较 hash 值, 再用 equals() 比较
|--K 已存在, 新 V 替旧 V
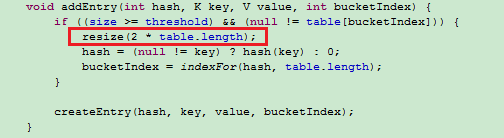
|--初始大小为16, 负载因子0.75, 最大容量即12, 容量不够扩容为原来的 2倍
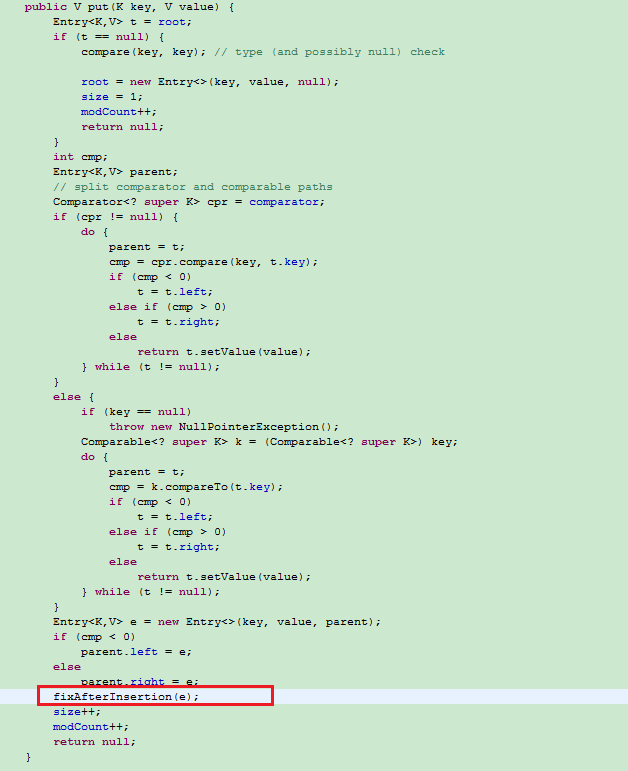
TreeMap
|--源码 put() 没有 synchronized 关键字, 因而线程不同步
|--红黑树需要每次调用平衡算法