一 前期准备
1.1 anaconda配置
打开Anaconda Prompt(anaconda),创建虚拟环境
输入命令:
conda create -n pytorch_py36 python=3.6
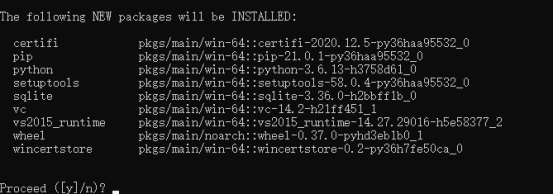
图1-1
创建的过程中会有一个选择,输入y就可以了,如图1-1所示
创建成功之后如图所示
激活环境
activate pytorch_py36

图1-2
看到左侧有(pytorch_py36)就代表转换环境成功,如图1-2所示
pip list可以查看当前环境安装有哪些工具包,如图1-3所示,此时虚拟环境中并没有pytorch的环境
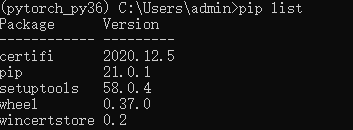
图1-3
https://pytorch.org
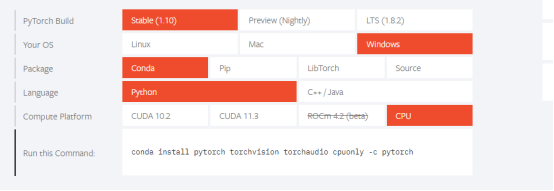
图1-4
进入上面的官网,然后向下啦,就会看到如图1-4所示,在里面选择相应的安装信息会产生命令,在上面激活的pytorch_py36虚拟环境中运行此命令就可以了,中间也有一个选择的过程,直接输入y就可以,这个的安装时间稍微会长一点。
查看pytorch是否安装成功,命令行下输入python,然后输入import torch
查看是否可以使用GPU :torch.cuda.is_available() 返回False表示不能使用
1.2 两个常用帮助函数
ctrl+p可以看到一个函数的形参
dir(torch) 表明查看这个cuda下的具体小库
dir(torch.cuda)
dir(torch.cuda.is_available) 会返回很多左右下划线,表明这是一个具体的函数,这个时候需要使用help(torch.cuda.is_available)会有这个函数的官方帮助信息
二数据处理
2.1 pytorch加载数据
主要涉及两个类Dataset Dataloader
Dataset:提供一种方式去获取数据及其label
Dataloader:为后面的网络提供不同的数据形式
打开图片
点击查看代码
#方法一
from PIL import Image
img=Image.open(img_path)
ims.show()
#方法二
#opencv读取图像,结果是ndarray
import cv2
cv_img=cv2.imread(img_path)
print(cv_img)
加载数据集
首先在代码的同级目录下创建dataset目录
链接:https://pan.baidu.com/s/1YtqGZKa1I_IwFghW9vMwzA
提取码:obcp
然后将上面下载的数据集解压,将产生的两个文件train,test复制到创建的dataset目录中
代码:
点击查看代码
from torch.utils.data import Dataset
from PIL import Image
import os
import os.path
class MyData(Dataset):
#创建实例的时候运行的初始化函数,一般为整个class提供全局变量
#self相当于一个全局变量,可以创建相应的变量
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path)
#按下标查询图片
def __getitem__(self, idx):
img_name=self.img_path[idx]
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
img=Image.open(img_item_path)
label=self.label_dir
return img,label
#返回数据集长度
def __len__(self):
return len(self.img_path)
root_dir="dataset/train"
ants_label_dir="ants"
ants_dataset=MyData(root_dir,ants_label_dir)
print(ants_dataset)
img,label=ants_dataset[1] #这个类中定义了getitem,所以可以使用下标
print(label)
img.show()
bees_label_dir="bees"
bees_dataset=MyData(root_dir,bees_label_dir)
train_dataset=ants_dataset+bees_dataset
2.2TensorBoard的使用
安装tensorboard
在命令行下输入:
pip install tensorboard
可以使用tensorboard绘制表格图像
点击查看代码
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs") #创建类实例 将内容放到这个文件夹logs,没有会自动创建该文件夹
#绘制y=2*x图像
for i in range(100):
writer.add_scalar("y=2x",2*i,i) #标题,y,x
writer.close()
图2-1
在图2-1中输入
tensorboard --logdir=logs --port=6006 #命令行输入
在浏览器localhost:6006中就可以访问了
放入图片
点击查看代码
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs") #创建类实例 将内容放到这个文件夹logs,没有会自动创建该文件夹
img_path="data/train/ants_image/5650366_e22b7e1065.jpg"
img_PIL=Image.open(img_path)
img_array=np.array(img_PIL)
print(img_array.shape) #(375,500,3)
writer.add_image("test",img_array,1,dataformats='HWC') #指定上面图片的形状顺序 1表示step1
writer.close()
2.3Transform
简单例子
点击查看代码
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
#通过transforms.ToTensor理解两个问题
#1)transforms如何使用
#2)为什么需要Tensor数据
from PIL import Image
img_path="data/train/ants_image/0013035.jpg"
img=Image.open(img_path)
writer=SummaryWriter("logs") #日志文件夹
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)#可以传入PIL格式,也可以是numpy格式 返回的是tensor格式
writer.add_image("Tensor_Img",tensor_img)
writer.close()
常用transform
点击查看代码
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("images/5650366_e22b7e1065.jpg")
#1)ToTensor
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img) #输入为PIL格式或者ndsrray格式
writer.add_image("ToTensor",img_tensor)
#2)Normalize input=(input-mean)/std
trand_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #分别是均值 标准差,因为图片是RGB,是三个通道,所以每个提供三个
#上面都是0.5 这样input=(input-0.5)/0.5=2*(input-0.5) 如果input=[0,1]那么转换后的input=[-1,1]
img_norm=trand_norm(img_tensor)#输入只能是tensor
writer.add_image("Normalize",img_norm,1)
#3)Resize
print(img.size)
trans_resize=transforms.Resize((512,512)) #如果只有一个值,就是将原先的长宽中的较小值和这个值匹配,另一个值等比缩放
#img PIL->resize->img_resize PIL
img_resize=trans_resize(img)
#img_resize PIL->totensor->img_resize tensor
img_resize=trans_totensor(img_resize)
writer.add_image("resize",img_resize,0)
#4)Compose() 参数需要是一个列表,数据需要是tranforms类型 所以为Compose([tranforms1,tranforms2,...])
trans_resize_2=transforms.Resize(512)
trans_compose=transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2=trans_compose(img) #依次进行上述参数列表中的变换
writer.add_image("resize",img_resize_2,1)
#RendomCrop() 随机裁剪
trans_random=transforms.RandomCrop(224) #这里只填写一个值,表示裁剪的正方形的边长 也可以(224,224)
trans_compose_2=transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop=trans_compose_2(img)
writer.add_image("crop",img_crop,i)
writer.close()
为什么需要tensor的数据类型
tensor包含了神经网络常用的参数
关注输入和输出类型
多看官方文档
关注方法需要什么参数
不知道返回值的时候,使用print(type())
2.4 torchvision数据集的使用
点击查看代码
#root下载的数据集的存放位置
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0])
print(test_set.classes)
img,target=test_set[0]
print(img)
print(target)
发现test_set[0]是两部分,所以可以使用img,target=test_set[0]来接受(注意这里已经自动将文字类别转换成对应的数字类别了),可以使用test_Set.classes来显示其中的类别,而3对应的就是cat
点击查看代码
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_tranaform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#root下载的数据集的存放位置 transform对所有的图片都进行transform转换
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_tranaform,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_tranaform,download=True)
writer=SummaryWriter("logs")
for i in range(10):
img,target=test_set[i]
writer.add_image("test_set",img,i)
writer.close()
可以直接在官网查看这些数据集的相关用法 pytorch.org
2.5 DataLoader的使用
参数
dataset数据集
batch_size:一次取几个数据,绑定一起
shuffle:默认为False表示不打乱数据,但是通常会设置为True
num_workers:表示取数据的时候是否使用多个进程,0表示只有一个主进程,在windows中好像设置多个进程有时会出问题。
drop_last:如果有10个数据,此时batch_size设置成3,取3次之后还剩一个数据。如果为True表示只要前9个数据,最后一个数据就不要了 一般设置为True
点击查看代码
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#测试集中第一张图片及target
img,target=test_data[0]
print(img.shape)
print(target)
print(test_loader)
writer=SummaryWriter("logs")
step=0
#每个data都是四个数据打包到一起
for data in test_loader:
imgs,targets=data
print(imgs.shape)
print(targets)
writer.add_images("test_Data",imgs,step)#多张图片使用add_images
step+=1
writer.close()
三 神经网络
3.1神经网络的基本骨架
基本都需要使用torch.nn.Module,继承于这个类
点击查看代码
class Model(nn.Module): #自定义类名Model
def __init__(self):
super(Model, self).__init__() #这个必须要有,继承父类初始化函数
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
#给神经网络一个输入,会经过forward然后给出一个输出,这里是前向传播
#x相当于代表的是输入
def forward(self, x):
x = F.relu(self.conv1(x)) #经过一次卷积和非线性处理
return F.relu(self.conv2(x))
简单网络
点击查看代码
class Sjz(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output=input+1
return output
sjz=Sjz()
x=torch.tensor(1.0)
output=sjz(x)
print(output)
3.2 卷积
stride=1,就是每次将卷积核右移一位,如果是2则是右移两位.stride可以是一个元祖(Sh,Sw)分别控制右移和下移
padding:给原先的输入的左右上下插入padding行,插入的行里面的值默认为0
点击查看代码
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
output=F.conv2d(input,kernel,stride=1)
print(output)
卷积层
bias通常设置为True
in_channels:输入的通道数,对于彩色图像而言,一般就是3
out_channels:通过卷积之后产生的输出的通道数
kernel_size:卷积核大小,可以是整数,也可以是元组
stride:步骤大小
padding:是否在图像边缘填充
padding_mode:填充的内容模式
dilation:默认为1
groups:默认为1
bias:设置为True
点击查看代码
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
sjz=Sjz()
writer=SummaryWriter("./logs")
step=0
for data in dataloader:
imgs,targets=data
output=sjz(imgs)
print(imgs.shape) #64,3,32,32
print(output.shape) # 64,6,30,30
#需要转换为3个通道才能显示,第一维是-1,表明具体的值根据后面的维度值自动确定
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step+=1
writer.close()
3.3 池化层
MaxPool2d()
kernel_size:用来取最大值的窗口的大小
stride:默认是kernel_size
padding:
dilation:一般不设置
return_indices:
ceil_mode:true为ceill模式(向上取整剩余部分不够kernel_size的时候会进行保存,也就是从剩余部分取一个最大值,而不是舍弃),False为floor模式(向下取整)。默认为False
点击查看代码
import torch
from torch import nn
from torch.nn import MaxPool2d
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
input=torch.reshape(input,(1,1,5,5))
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,x):
output=self.maxpool1(input)
return output
sjz=Sjz()
output=sjz(input)
print(output)
最大池化的作用是保持输入特征,同时减少输入量
3.4非线性激活
Relu()
input=-1
Relu(input,inplace=True)
此时input=0 其值被改变了
input=-1
output=Relu(input,inplace=False)
此时input=-1,input的值没有被改变
一般inplace是False
点击查看代码
import torch
from torch import nn
from torch.nn import ReLU
input=torch.tensor([[1,-0.5],
[-1,3]])
input=torch.reshape(input,(1,1,2,2))
print(input.shape)
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.relu1=ReLU()
def forward(self,input):
output=self.relu1(input)
return output
sjz=Sjz()
output=sjz(input)
print(output)
非线性变化为了给网络中引入非线性特征,非线性越多才能训练出符合各种曲线。各种特征的模型
3.5 线性层及其他层
正则化层Normalization 使用较少
Recurrent层 多用于文字识别中
Transformer层
Dropout层 主要为了防止过拟合
Sparse层 主要用于自然语言处理
线性层 Linear
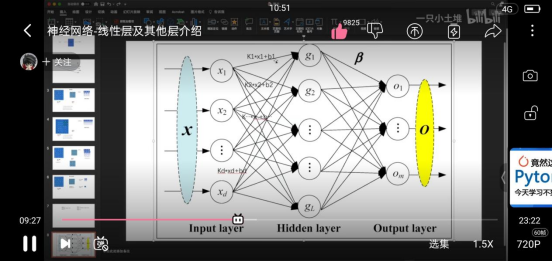
线性层就是给出左边x的个数,各处右边g的个数,并确定bias是否为True然后自动计算中间的计算权重等等
点击查看代码
import torch
import torchvision.datasets
from torch.nn import Linear
from torch import nn
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64,drop_last=True) #注意这里的drop_last要设置为True,否则最后一组数据会出现batch_size=16,那么网络的1996608的数据就会不对
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.linear1=Linear(196608,10)#这里的196608是根据64*3*32*32计算出来的
def forward(self,input):
output=self.linear1(input)
return output
sjz=Sjz()
for data in dataloader:
imgs,targets=data
print(imgs.shape) #64,3,32,32
# output=torch.reshape(imgs,(1,1,1,-1)) #1,1,1,1996608
output=torch.flatten(imgs) #展平,效果和上一行一样 [1996608]
print(output.shape)
output=sjz(output) #1,1,1,10
print(output.shape)
四 网络搭建小实战
点击查看代码
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.conv1=Conv2d(3,32,5,padding=2)
self.maxpool1=MaxPool2d(2)
self.conv2=Conv2d(32,32,5,padding=2)
self.maxpool2=MaxPool2d(2)
self.conv3=Conv2d(32,64,5,padding=2)
self.maxpool3=MaxPool2d(2)
self.flatten=Flatten()
self.linear1=Linear(1024,64)
self.linear2=Linear(64,10) #因为有十类,所以最后是10
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
#如果到某一步,不知道当前尺寸是多大,只需要将当前步及下面的步删掉,然后找一个数据运行网络,看看输出的形状就可以了
def forward(self,x):
# x=self.conv1(x)
# x=self.maxpool1(x)
# x=self.conv2(x)
# x=self.maxpool2(x)
# x=self.conv3(x)
# x=self.maxpool3(x)
# x=self.flatten(x)
# x=self.linear1(x)
# x=self.linear2(x)
x=self.model1(x) #这一步与上面注释的作用一样
return x
sjz=Sjz()
print(sjz)
#验证网络是否正确,只需要创建一个数据放入进行测试就行
input=torch.ones((64,3,32,32))
output=sjz(input)
print(output.shape)
#可以使用tensorboard显示 这样可以用图形显示整个网络的网络结构
writer=SummaryWriter("logs")
writer.add_graph(sjz,input)
writer.close()
五参数、模型使用
5.1损失函数和反向传播
损失Loss是预测的结果与实际结果的差距,为更新输出提供一定的依据,也就是反向传播
Loss是越小越好
点击查看代码
import torch
from torch.nn import L1Loss
from torch import nn
inputs=torch.tensor([1,2,3],dtype=torch.float32)
targets=torch.tensor([1,3,5],dtype=torch.float32)
inputs=torch.reshape(inputs,(1,1,1,3))
targets=torch.reshape(targets,(1,1,1,3))
loss=L1Loss() #(1-1+3-2+5-3)/3
loss=nn.MSELoss() #(0*0+1*1+2*2)/3=1.6667
result=loss(inputs,targets)
print(result)
x=torch.tensor([0.1,0.2,0.3]) #三分类,当前对每个分类的概率
y=torch.tensor([1]) #标识真实值是第二类,因为从0开始
x=torch.reshape(x,(1,3))
loss_cross=nn.CrossEntropyLoss()
result_cross=loss_cross(x,y)
print(result_cross)
loss可以用于反向传播,给卷积核上的参数进行调整,给上面的每一个参数设置了一个grad梯度,当反向传播的时候会求出每一个梯度,会根据梯度进行优化,达到loss降低的目的。
点击查看代码
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=1,drop_last=True)
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.conv1=Conv2d(3,32,5,padding=2)
self.maxpool1=MaxPool2d(2)
self.conv2=Conv2d(32,32,5,padding=2)
self.maxpool2=MaxPool2d(2)
self.conv3=Conv2d(32,64,5,padding=2)
self.maxpool3=MaxPool2d(2)
self.flatten=Flatten()
self.linear1=Linear(1024,64)
self.linear2=Linear(64,10) #因为有十类,所以最后是10
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
#如果到某一步,不知道当前尺寸是多大,只需要将当前步及下面的步删掉,然后找一个数据运行网络,看看输出的形状就可以了
def forward(self,x):
# x=self.conv1(x)
# x=self.maxpool1(x)
# x=self.conv2(x)
# x=self.maxpool2(x)
# x=self.conv3(x)
# x=self.maxpool3(x)
# x=self.flatten(x)
# x=self.linear1(x)
# x=self.linear2(x)
x=self.model1(x) #这一步与上面注释的作用一样
return x
sjz=Sjz()
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets=data
outputs=sjz(imgs)
results_loss=loss(outputs,targets) #loss值
results_loss.backward() #反向传播 计算各个节点的grad梯度值
5.2 优化器
优化器都在torch.optim中
lr学习速率 设置大训练起来模型不稳定,设置小模型训练速度慢,一般是开始设置大,后面再训练设置小
点击查看代码
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=1,drop_last=True)
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
#如果到某一步,不知道当前尺寸是多大,只需要将当前步及下面的步删掉,然后找一个数据运行网络,看看输出的形状就可以了
def forward(self,x):
x=self.model1(x) #这一步与上面注释的作用一样
return x
sjz=Sjz()
loss=nn.CrossEntropyLoss()
optim=torch.optim.SGD(sjz.parameters(),0.01) #第一个是网络的参数,第二个是学习速率
for epoch in range(20):#进行20轮训练
running_loss=0.0
for data in dataloader:
imgs,targets=data
outputs=sjz(imgs)
results_loss=loss(outputs,targets) #loss值
optim.zero_grad() #将上一步的反向传播产生的梯度值设置为0,不设置为0,对模型会有影响,产生问题
results_loss.backward() #反向传播 计算各个节点的grad梯度值
optim.step() #按照反向传播产生的梯度值对参数进行调优
running_loss+=results_loss
print(running_loss)
5.3 现有网络模型的使用和修改
点击查看代码
import torch
import torchvision
# train_data=torchvision.datasets.ImageNet("./dataset",split="train",download=True,transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true=torchvision.models.vgg16(pretrained=True) #为True表示下载的是在ImageNet上预训练好的模型参数,因此需要下载
print(vgg16_false)
print(vgg16_true)
#因为vgg模型是对ImageNet数据集进行训练,这个数据集有1000类
#而我们想让这个模型对CIFAR10进行训练,可以将最后的线性层的1000改为10,也可以在最后再加一个线性层为1000->10的线性层
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#为vgg16_true加一层1000->10
# vgg16_true.add_module("add_linear",nn.Linear(1000,10)) #这样是在整个Vgg16中加
# vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10)) #这样是在vgg16的classifier中加
# print(vgg16_true)
#对线性层进行修改
vgg16_true.classifier[6]=nn.Linear(4096,10)
print(vgg16_true)
5.4 网络模型的保存与读取
点击查看代码
import torchvision
import torch
vgg16=torchvision.models.vgg16(pretrained=False)
#保存方式1
torch.save(vgg16,"./model/vgg16.pth") #不仅保存了网络模型结构+模型参数
#保存方式2 保存模型参数 官方推荐
torch.save(vgg16.state_dict(),"./model/vgg16_method2.pth") #将vgg16中的参数保存成字典
#使用方式1的时候,会存在一个问题
#当自定义网络结构并保存的时候,当我们需要加载的时候,需要将定义的class网络类的定义复制到调用加载语句的py中
import torch
import torchvision
#保存方式1进行加载
model=torch.load("./model/vgg16.pth")
print(model)
#保存方式2进行加载
model=torch.load("./model/vgg16_method2.pth")
print(model)
#加载成网络模型结构
vgg16=torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("./model/vgg16_method2.pth"))
print(vgg16)
5.5 模型训练套路
一般将自己定义的网络模型单独写在一个model.py文件中
model.py
点击查看代码
#搭建神经网络
import torch
from torch import nn
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
#测试网络模型正确性
if __name__=='__main__':
sjz=Sjz()
input=torch.ones((64,3,32,32))
output=sjz(input)
print(output.shape)
train.py
点击查看代码
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import * #引入自己写的model.py 注意和当前文件在同一目录下
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size=len(train_data)
test_data_size=len(test_data)
#使用DAtaLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64,drop_last=True)
test_dataloader=DataLoader(test_data,batch_size=64,drop_last=True)
#创建网络模型
sjz=Sjz()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learning_rate=0.01
optimizer=torch.optim.SGD(sjz.parameters(),lr=learning_rate)
#设置训练网络的一些参数
total_train_step=0 #记录训练的次数
total_test_step=0 #记录测试的次数
epoch=10 #训练的轮数
monitor_step=100 #每过一百步就监控显示一次
#添加tensorboard
writer=SummaryWriter("logs")
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#训练步骤开始
sjz.train() #进入训练状态,只对某一些特定层起作用
for data in train_dataloader:
imgs,targets=data
outputs=sjz(imgs)
loss=loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100==0:
print("第{}轮训练次数:{},Loss:{}".format(i+1,total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
sjz.eval()#进入测试状态,只对某一些特定层起作用
total_test_loss=0
total_accuracy=0
with torch.no_grad():
#在这里的代码没有了梯度,为了不会对模型进行调优,因为这是测试数据集
for data in test_dataloader:
imgs,targets=data
outputs=sjz(imgs)
loss=loss_fn(outputs,targets)
total_test_loss+=loss
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy+=accuracy
print("第{}轮训练后,整体测试集上的loss为{}".format(i+1,total_test_loss))
print("第{}轮训练后,整体测试机上的正确率为{}".format(i+1,total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step+=1
#保存每一轮模型
torch.save(sjz,"sjz_{}.pth".format(i))
print("模型已保存")
writer.close()
# outputs=torch.tensor([[0.1,0.2],[0.05,0.4]])
# print(outputs.argmax(1)) #1表示横着看,也就是结果为[1,1] 如果为0,结果为[0,1]为竖着看, 取最大值的下标
# preds=outputs.argmax(1)
# targets=torch.tensor([0,1])
# print()
5.6 GPU进行训练
利用只需要对数据(输入、标注)、模型、损失函数放到cuda上就可以
方式1:
点击查看代码
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import * #引入自己写的model.py 注意和当前文件在同一目录下
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size=len(train_data)
test_data_size=len(test_data)
#使用DAtaLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64,drop_last=True)
test_dataloader=DataLoader(test_data,batch_size=64,drop_last=True)
#创建网络模型
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
sjz=Sjz()
if torch.cuda.is_available():#如果支持GPU就转到GPU上
sjz=sjz.cuda() #将网络模型转到cuda上
#损失函数
loss_fn=nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn=loss_fn.cuda() #损失函数到cuda
#优化器
learning_rate=0.01
optimizer=torch.optim.SGD(sjz.parameters(),lr=learning_rate)
#设置训练网络的一些参数
total_train_step=0 #记录训练的次数
total_test_step=0 #记录测试的次数
epoch=10 #训练的轮数
monitor_step=100 #每过一百步就监控显示一次
#添加tensorboard
writer=SummaryWriter("logs")
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#训练步骤开始
sjz.train() #进入训练状态,只对某一些特定层起作用
for data in train_dataloader:
imgs,targets=data
if torch.cuda.is_available():
imgs=imgs.cuda() #将数据到cuda上
targets=targets.cuda()
outputs=sjz(imgs)
loss=loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100==0:
print("第{}轮训练次数:{},Loss:{}".format(i+1,total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
sjz.eval()#进入测试状态,只对某一些特定层起作用
total_test_loss=0
total_accuracy=0
with torch.no_grad():
#在这里的代码没有了梯度,为了不会对模型进行调优,因为这是测试数据集
for data in test_dataloader:
imgs,targets=data
if torch.cuda.is_available():
imgs=imgs.cuda()
targets=targets.cuda()
outputs=sjz(imgs)
loss=loss_fn(outputs,targets)
total_test_loss+=loss
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy+=accuracy
print("第{}轮训练后,整体测试集上的loss为{}".format(i+1,total_test_loss))
print("第{}轮训练后,整体测试机上的正确率为{}".format(i+1,total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step+=1
#保存每一轮模型
torch.save(sjz,"sjz_{}.pth".format(i))
print("模型已保存")
writer.close()
# outputs=torch.tensor([[0.1,0.2],[0.05,0.4]])
# print(outputs.argmax(1)) #1表示横着看,也就是结果为[1,1] 如果为0,结果为[0,1]为竖着看, 取最大值的下标
# preds=outputs.argmax(1)
# targets=torch.tensor([0,1])
# print()
方式2:
点击查看代码
#device=torch.device("cpu") #cpu方式
device=torch.device("cuda") #和cuda:0等价,都是第一张显卡,1代表第二张显卡
sjz=sjz.to(device) #只需要在方式1的基础上将所有的.cuda()都改成.to(device)
5.7 模型验证测试
利用已经训练好的模型,提供输入
点击查看代码
import torch
import torchvision
from PIL import Image
from torch import nn
image_path="./img/img.png"
image=Image.open(image_path)
#因为png格式是四个通道,除了RGB三通道外,还有一个透明度通道,所以这里调用下面这句话保留其颜色通道
#如果图片本来就是三个颜色通道,经过此操作后,不变。加上这一步可以适应png jpg各种格式的图片
image=image.convert("RGB")
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image=transform(image)
#因为之前是方式1保存的,所以需要将模型的定义复制过来
class Sjz(nn.Module):
def __init__(self):
super(Sjz, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
image=torch.reshape(image,(1,3,32,32)) #因为输入需要四维
model=torch.load("sjz_9.pth",map_location=torch.device('cpu')) #如果在GPU上训练的,需要加上这里的cpu来进行对应
model.eval()
with torch.no_grad():
output=model(image)
print(output.argmax(1))