1、打开文件
open()
f=open('haha') #打开一个名为haha的txt文件,不写后缀默认txt文件,其他类型文件必须写后缀
2、read()读取文件内容
print(f.read()) #阅读模式,获取里面所有的内容,该模式只能读取内容,不能对其进行修改。
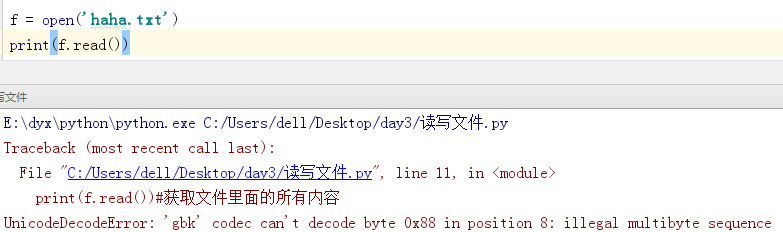
有时候会产生该错误,表示gbk解码时报错,存在一些字符不能使用gbk来解码(例如中文) 所以我们可以在open()中再添加一个参数 encoding='utf-8' 就可以解决该问题。

若文件不存在运行,会报错。

在读取路径时,比如c:\niu\desktop 这种,open在打开文件时会把c:\niu 认为里面有一个 ,所以我们可以在文件路径前加一个r,比如f=open(r'c:\niu\desktophaha') 表示原字符,不需要转义。
print(f.readline()) #读取一行数据
print(f.readlines())#获取文件里面所有的数据,每一行数据放到一个list里面
print(f.read()) #获取全部文件内容
依次执行上面三种函数,读取时,readline读取第一行,readlines 读取剩余内容,read读取不到内容,产生这种原因,是因为文件指针的原因。
文件指针:打开文件,默认指针在前,readline 读取第一行,读取完后,指针读取到第二行,readlines表示读取全部,所以将文件所有内容都读取完,指针读取到最后,再使用read读取的时候,就读取不到任何东西了。
3、write()写
f.write() 修改文件内容,该模式只能修改不能读,若使用此函数,则需要去文件夹看,谨慎使用该函数,修改后无法撤回。
f.write('kkkkk')
names=['lxy','zyf','zxd','lcs']
for name in names:
print(name+' ') #依次读出来,然后换行
writelines([list]) #传一个list,然后把list里面的每一个元素写入到文件中
1 names=['lxy','zyf','zxd','lcs']
2 writelines(names)
换行的话,可以在数组里面加
names=['lxy ','zyf ','zxd ','lcs ']
4、文件的模式:
读模式 r:默认读模式,只能读,不能写,文件不存在会报错;
写模式 w:写模式,只能写,会覆盖以前文件里面的内容,不能读,文件不存在会新建;
读写模式 r+:可以读,可以写,文件不存在会报错;
写读模式 w+:可以读,可以写,文件不存在会创建;
追加模式 a:只能写,不能读,文件不存在会创建,不会清空以前的内容;
追加模式 a+:读写模式,文件不存在会创建,能读能写,不会清空以前的内容。
只要沾上r,文件不存在都会报错;
只要沾上w,文件内容肯定会被清空。
5、追加模式 a+
f=open('hh','a+')
f.seek(0) #移动指针到最前面
f.close() #关闭文件