概念
狭义:正在运行的程序
广义:是操作系统动态执行的基本单位
程序是永久的(写好的代码,还没运行);
进程是暂时的(运行中的代码)
调度算法
先来先服务(FCFS)
短作业优先(SJ/PF)
时间片轮转法
多级反馈队列
1,时间片轮转
2,优先级:先来后执行
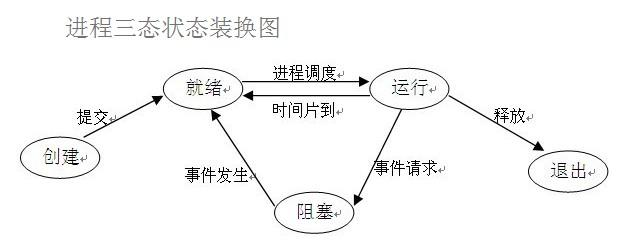
进程三状态
multiprocess模块
创建进程部分
Windows下的注意事项
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
multiprocess.process模块
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)


1 import os 2 from multiprocessing import Process 3 4 5 def func(args): 6 print('in func') 7 print(args) 8 print('子进程:', os.getpid()) 9 print('子进程的父进程', os.getppid()) 10 11 12 if __name__ == '__main__': 13 p = Process(target=func, args=('参数', )) # p是一个进程对象 14 p.start() # 启动子进程 15 print('在主进程中') 16 print('主进程: ', os.getpid()) 17 print('主进程的父进程', os.getppid())
1 import os 2 import time 3 from multiprocessing import Process 4 5 def func(arg1, arg2): 6 print('*'*arg1) 7 time.sleep(2) 8 print('='*arg2) 9 print('子进程id', os.getpid()) 10 11 12 if __name__ == '__main__': 13 for i in range(10): 14 p = Process(target=func, args=(10, 20)) 15 p.start() 16 print('主进程ID:', os.getpid())
1 import os 2 from multiprocessing import Process 3 4 5 class MyProcess(Process): 6 def __init__(self, arg1, arg2): 7 super().__init__() 8 self.arg1 = arg1 9 self.arg2 = arg2 10 11 def run(self): 12 print('子进程中', os.getpid()) 13 print('参数1', self.arg1) 14 print('参数1', self.arg2) 15 16 17 if __name__ == '__main__': 18 print('主进程中:', os.getpid()) 19 p1 = MyProcess(1, 2) 20 p1.start() 21 p2 = MyProcess(3, 4) 22 p2.start()
方法
- 1 p.start():启动进程,并调用该子进程中的p.run()
- 2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
- 3 p.terminate():
- 强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
- 结束一个进程不是执行结束方法之后立即生效,需要一个操作系统的响应的时间过程
- 4 p.is_alive():如果p仍然运行,返回True
- 5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
1 import time 2 from multiprocessing import Process 3 4 5 def func(arg1, arg2): 6 print('*'*arg1) 7 time.sleep(3) 8 print('*'*arg2) 9 10 11 if __name__ == '__main__': 12 p = Process(target=func, args=(10, 20)) 13 p.start() # 开始一个进程 14 print('haha') # 和上面的子进程还是异步执行 15 p.join() # 感知一个子进程的结束, 将异步的程序改为同步 16 print('----运行完了')
属性
- 1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
- 2 p.name:进程的名称
- 3 p.pid:进程的pid
- 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
- 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
1 import os 2 from multiprocessing import Process 3 4 5 def func(): 6 global n # 声明一个全局变量 7 n = 0 # 重新定义n 8 print('子进程PID: %s' % os.getpid(), n) 9 10 11 if __name__ == '__main__': 12 n = 100 # 全局变量 13 p = Process(target=func) 14 p.start() 15 p.join() 16 print('父进程PID:%s' % os.getpid(), n) # 数据是隔离的,在子进程中无法修改全局中的变量
守护进程
守护进程会随着主进程【的代码】结束而结束
""" 守护进程的代码会随着主进程的**代码结束**而结束 """ import time from multiprocessing import Process def fun1(): print('fun1 start') while True: time.sleep(0.5) print("I'm still alive!") def fun2(): print('fun2 starting') time.sleep(8) print('fun2 end') if __name__ == '__main__': p1 = Process(target=fun1) p2 = Process(target=fun2) p1.daemon = True # 设置p1为守护进程 p1.start() p2.start() time.sleep(4) print('last code') # 此时守护进程也结束了
进程同步部分
锁 —— multiprocess.Lock模块
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
方法(Lock实例化lock)
- lock.acquire() 上锁
- lock.release() 解锁
// main.py """ 加锁可以多个进程修改同一个数据时,同一个时间只能有一个任务可以进行修改,即串行的修改。 """ import time import json from multiprocessing import Process, Lock def buy_ticket(x, lock): lock.acquire() with open('ticket.stock') as f: ticket = json.load(f) time.sleep(0.1) if ticket['ticket_stock'] > 0: ticket['ticket_stock'] -= 1 print('顾客%s, 恭喜你买到票了!' % x) else: print('顾客%s, 抱歉,票抢完了!' % x) time.sleep(0.1) with open('ticket.stock', 'w') as f: json.dump(ticket, f) lock.release() if __name__ == '__main__': lock = Lock() # 注意:各进程用的是同一个`锁` for i in range(1, 11): Process(target=buy_ticket, args=(i, lock)).start() // ticket.stock {"ticket_stock": 0}
信号量 —— multiprocess.Semaphore模块
加了计数器的锁
方法(Semaphore(4)实例化sem)
- sem.acquire() 上锁
- sem.release() 解锁
""" 加了计时器的锁 > 同时有几个进程同时运行 """ import random import time from multiprocessing import Process, Semaphore """ 需求:同一个时刻,只有5个人能进KTV,有人出来之后,才能再进去 """ def ktv(x, sem): sem.acquire() print('-->顾客%s 走进了KTV' % x) time.sleep(random.randint(3, 8)) print('<--顾客%s 走出了KTV' % x) sem.release() if __name__ == '__main__': sem = Semaphore(5) # 创造一个semaphore对象,**同一个时间**只有5个进程被执行。 注意:各进程用的是同一个`信号量` for x in range(1, 21): Process(target=ktv, args=(x, sem)).start()
事件 —— multiprocess.Event模块
用于主进程控制其他进程的执行
event.is_set() # 默认是 False
event.set() # 将 event.is_set() = True 即Event状态为True
event.clear() # 将 event.is_set() = False 即Event状态为False
event.wait() # Event状态是False,则`wait`阻塞;Event状态是True时,`wait`不阻塞。
import random import time from multiprocessing import Process, Event def control_event_status(e): """ 一秒钟切换一次 event 的状态。 False True False ... :param e: :return: """ while True: if e.is_set(): # 默认的 is_set() = False e.clear() else: e.set() # print('event status: %s ' % e.is_set()) time.sleep(1) def car(e, x): """ :param e: 事件 :param x: 车牌号 :return: """ e.wait() print('状态:', e.is_set()) print('粤A %s 通过了' % x) if __name__ == '__main__': e = Event() Process(target=control_event_status, args=(e,)).start() # 开一个线程一直切换 Event状态 for _car in range(1, 21): # 每过 random.random 秒 之后启动一个进程 Process(target=car, args=(e, _car)).start() time.sleep(random.random())
进程间通信
队列 —— multiprocess.Queue模块
先进先出
方法(Queue实例化q)
- q.put(item [, block [,timeout ] ] )
- 将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
- q.get( [ block [ ,timeout ] ] )
- 返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
- q.qsize()
- 返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
- q.empty()
- 如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目
- q.full()
- 如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的
1 from multiprocessing import Queue 2 3 q = Queue(5) 4 5 for i in range(5): # 循环往队列q里存值 6 q.put(i) 7 8 print(q.full()) 9 for i in range(5): # 循环从队列q里取值 10 print(q.get()) 11 12 print(q.empty())
""" 生产者消费 示例 """ import random import time from multiprocessing import Process, Queue def producer(name, food, _queue): """ 生产者进程 :param name: 生产者名字 :param food: 生产食物 :param _queue: 仓库 :return: """ for i in range(10): time.sleep(random.randint(1, 2)) _food = food + str(i) print('%s 生产了 %s' % (name, _food)) _queue.put(_food) _queue.put(None) _queue.put(None) def consumer(name, _queue): """ 消费者进程 :param name: 消费者 :param _queue: :return: """ while True: _food = _queue.get() if _food is None: print('没有食物了') break print('%s 消费了 %s' % (name, _food)) time.sleep(random.randint(1, 2)) if __name__ == '__main__': stock = Queue() Process(target=producer, args=('生产者1号', '包子', stock)).start() Process(target=producer, args=('生产者2号', '馒头', stock)).start() Process(target=consumer, args=('消费者1号', stock)).start() Process(target=consumer, args=('消费者2号', stock)).start()
队列 ——JoinableQueue模块
加了计数器的队列
方法(JoinableQueue实例化)
- q.task_done()-->和get一起用
- put一个数据时,则计数器+1
- get一个数据时,则计数器-1
- q.join()-->和join一起用
- 感知task_done,等待被刻上的记号被消耗
1 import random 2 import time 3 from multiprocessing import Process, JoinableQueue 4 5 6 def producer(name, food, q): 7 """生产者""" 8 for i in range(10): 9 time.sleep(random.randint(1, 3)) 10 f = food + str(i) 11 print('%s生产了%s' % (name, f)) 12 q.put(f) 13 q.join() # 阻塞, 当没有记号了通行 14 15 16 def consumer(name, q): 17 """消费者""" 18 while True: 19 food = q.get() 20 print('�33[31m%s吃了%s�33[0m' % (name, food)) 21 time.sleep(random.randint(1, 3)) 22 q.task_done() # 记号 23 24 25 if __name__ == '__main__': 26 q = JoinableQueue() 27 p1 = Process(target=producer, args=('alex', '包子', q)) # 生产者1进程 28 p2 = Process(target=producer, args=('jin', '泔水', q)) # 生产者2进程 29 c1 = Process(target=consumer, args=('顾客1', q)) # 顾客1进程 30 c2 = Process(target=consumer, args=('顾客2', q)) # 顾客2进程 31 p1.start() 32 p2.start() 33 c1.daemon = True # 把c1,c2 变成守护进程 34 c2.daemon = True 35 c1.start() 36 c2.start() 37 p1.join() 38 p2.join()
管道 —— multiprocess.Pipe模块
1,通信
- conn1,conn2 = Pipe()
- conn1.send() 发送一个str类型的数据给管道的对端conn2
- coon2.recv() 接收一个对端conn1发过来的数据
- conn1.close() 关闭管道的conn1口
2,EEOFError异常
如果管道不通会触发
3,数据不安全性
- 原因
- 多个对端均可能拿到数据
- 解决办法
- 加锁控制管道的行为,来避免进程之间争抢数据不安全现象
1 from multiprocessing import Pipe, Process 2 3 4 """通过发送一个None关闭recv""" 5 6 7 def func(conn1): 8 while True: 9 ret = conn1.recv() 10 if ret is None: 11 break # 不关闭的会一直阻塞在这里 12 print(ret) 13 14 15 if __name__ == '__main__': 16 conn1, conn2 = Pipe() 17 Process(target=func, args=(conn1, )).start() 18 for i in range(20): 19 conn2.send('你好啊%s' % i) 20 conn2.send(None) 21 22 23 """通过异常关闭recv""" 24 25 26 def func(conn1, conn2): 27 conn2.close() 28 while True: 29 try: 30 ret = conn1.recv() 31 print(ret) 32 except EOFError: 33 conn1.close() 34 break 35 36 37 if __name__ == '__main__': 38 conn1, conn2 = Pipe() 39 Process(target=func, args=(conn1, conn2)).start() 40 conn1.close() 41 for i in range(20): 42 conn2.send('你好啊%s' % i) 43 conn2.close()
1 import time 2 import random 3 from multiprocessing import Process, Pipe, Lock 4 5 6 def producer(name, food, con, pro): 7 con.close() 8 # print('%s关了左边门了' % name) 9 for i in range(10): 10 time.sleep(random.random()) 11 f = food + str(i) 12 pro.send(f) 13 print('%s生产了%s' % (name, f)) 14 pro.close() 15 # print('%s关了右边门了' % name) 16 17 18 def consumer(name, con, pro, lock): 19 pro.close() 20 # print('%s关了右边门了' % name) 21 while True: 22 try: 23 time.sleep(random.random()) 24 lock.acquire() # 加锁保证数据的安全性 25 food = con.recv() 26 lock.release() 27 print('�33[31m%s吃了%s�33[0m' % (name, food)) 28 except EOFError: 29 con.close() 30 # print('%s关了左边门了' % name) 31 break 32 33 34 if __name__ == '__main__': 35 con, pro = Pipe() 36 lock = Lock() 37 p = Process(target=producer, args=('alex', '泔水', con, pro)) 38 p.start() 39 c1 = Process(target=consumer, args=('顾客1', con, pro, lock)) 40 c1.start() 41 c2 = Process(target=consumer, args=('顾客2', con, pro, lock)) 42 c2.start() 43 c3 = Process(target=consumer, args=('顾客3', con, pro, lock)) 44 c3.start() 45 con.close() 46 pro.close()
bug:有多个消费者是无法关闭程序
进程间的数据共享
multiprocessing.Manager模块
- 所有进程共享的数据
m = Manger()
dic = m.dict({'count':100})
所有的进程都共享dic - 数据不安全性
- 原因 :有可能进程之间同时修改数据,但只有一个修改成功
- 解决办法:加锁
1 from multiprocessing import Process, Manager, Lock 2 3 4 def main(dic, lock): 5 lock.acquire() # 加锁保证数据安全 6 dic['count'] -= 1 7 print('子进程', dic) 8 lock.release() 9 10 11 if __name__ == '__main__': 12 m = Manager() # 13 lock = Lock() 14 dic = m.dict({'count': 100}) # 数据共享 15 p_lst = [] 16 for i in range(50): 17 p = Process(target=main, args=(dic, lock)) 18 p.start() 19 p_lst.append(p) 20 for p in p_lst: 21 p.join() 22 print('主进程', dic)
进程池部分
概念
- 1,由于没开启一个进程,操作系统就开启属于这个进程的内存空间、寄存器、堆栈、文件,而开启的进程过多,操作系统的调度频繁,效率下降
- 2,产生进程池,控制可同时运行的进程的数量
- 3,更高级的进程池(python不支持)
- 可同时运行的进程数量会变化的进程池
- 弹性的伸缩
multiprocess.Pool模块
Pool([numprocess [,initializer [, initargs]]]):创建进程池
- numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值
- initializer:是每个工作进程启动时要执行的可调用对象,默认为None
- initargs:是要传给initializer的参数组
1 import time 2 import os 3 from multiprocessing import Pool 4 5 6 def func(n): 7 print('start fun%s' % n, os.getpid()) 8 time.sleep(1) 9 print('end func%s' % n, os.getpid()) 10 11 12 # if __name__ == '__main__': 13 # p = Pool() 14 # for i in range(10): 15 # p.apply(func, args=(i, )) # apply 同步机制 16 17 if __name__ == '__main__': 18 p = Pool() 19 for i in range(10): 20 p.apply_async(func, args=(i, )) # apply_async 异步机制 21 22 p.close() # 结束进程池接收任务 23 p.join() # 感知进程池中的任务结束
1 from multiprocessing import Pool, Process 2 import time 3 4 5 def func(n): 6 for i in range(10): 7 print(n + 1) 8 9 10 if __name__ == '__main__': 11 start = time.time() 12 pool = Pool(5) # 创建一个进程池,同时【并行】5个进程 13 pool.map(func, range(100)) # 100个进程任务同时【并行】5个进程 14 t1 = time.time() - start 15 16 start = time.time() 17 p_lst = [] 18 for i in range(100): # 100个进程并行 19 p = Process(target=func, args=(i, )) 20 p.start() 21 p_lst.append(p) 22 for p in p_lst: 23 p.join() 24 t2 = time.time() - start 25 26 print(t1, t2) # t1是用进程池并行100的进程的时间;t2是100个进程同时并行的时间
主要方法(Pool(5)实例化p)
- p.apply(func [, args [, kwargs]]) 同步
- 在一个池工作进程中执行func(*args,**kwargs),然后返回结果
- p.apply_async(func [, args [, kwargs]],callback=None) 异步
- 在一个池工作进程中执行func(*args,**kwargs),然后返回结果
- 回调函数callback
- callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。
- 回调函数在【主进程】执行
- 回调函数的参数是异步进程的返回值
- p.close() -->结束进程池接收任务
- 关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成
- P.jion() -->感知进程池中的人物结束
- 等待所有工作进程退出。此方法只能在close()或teminate()之后调用
- p,map(func,<可迭代参数>)
- for 循环【异步】执行func
- 自带close,join
进程池的返回值
方法apply_async()和map_async()的返回值是AsyncResul的实例obj
- obj.get()
- 返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发。
1 from multiprocessing import Pool 2 import time 3 4 5 def func(n): 6 time.sleep(0.5) 7 print('in func') 8 return n * n 9 10 11 """同步""" 12 # if __name__ == '__main__': 13 # p = Pool() 14 # ret = p.apply(func, args=(9, )) 15 # print(ret) # func的返回值 16 17 """异步""" 18 if __name__ == '__main__': 19 p = Pool() 20 p_lst = [] 21 for i in range(10): 22 ret = p.apply_async(func, args=(i, )) # 分次获取返回值 23 p_lst.append(ret) 24 25 for p in p_lst: 26 print(p.get()) # get会阻塞,等待结果 27 28 """异步""" 29 # if __name__ == '__main__': 30 # p = Pool() 31 # ret = p.map(func, range(10)) # 一次性返回结果 32 # print(ret)