@
使用场景
Map Join 适用于一张表十分小、一张表很大的场景。
优点
思考:在Reduce 端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map 端业务,减少Reduce 端数据的压力,尽可能的减少数据倾斜。
具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
/缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt");
案例
每个MapTask在map()中完成Join
注意:
- 只需要将要Join的数据order.txt作为切片,让MapTask读取
- pd.txt不以切片形式读入,而直接在MapTask中使用HDFS下载此文件,下载后,使用输入流手动读取其中的数据
- 在map()之前通常是将大文件以切片形式读取,小文件手动读取!
order.txt---->切片(orderId,pid,amount)----JoinMapper.map()
pd.txt----->切片(pid,pname)----JoinMapper.map()
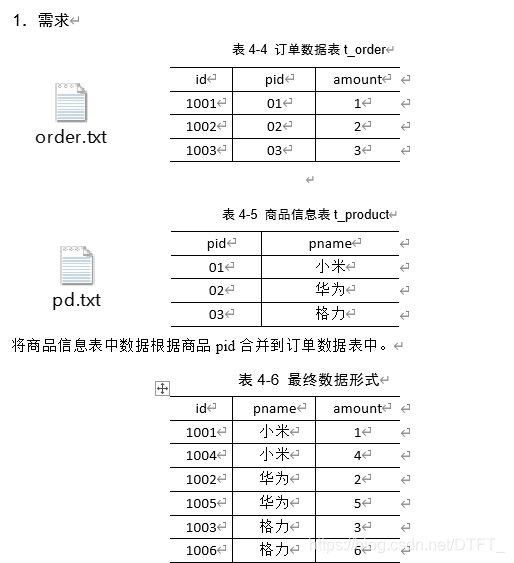
需求分析
MapJoin适用于关联表中有小表的情形
代码实现
JoinBean.java
public class JoinBean {
private String orderId;
private String pid;
private String pname;
private String amount;
@Override
public String toString() {
return orderId + " " + pname + " " + amount ;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public String getAmount() {
return amount;
}
public void setAmount(String amount) {
this.amount = amount;
}
}
MapJoinMapper.java
/*
* 1. 在Hadoop中,hadoop为MR提供了分布式缓存
* ①用来缓存一些Job运行期间的需要的文件(普通文件,jar,归档文件(har))
* ②通过在Job的Configuration中,使用uri代替要缓存的文件
* ③分布式缓存会假设当前的文件已经上传到了HDFS,并且在集群的任意一台机器都可以访问到这个URI所代表的文件
* ④分布式缓存会在每个节点的task运行之前,提前将文件发送到节点
* ⑤分布式缓存的高效是由于每个Job只会复制一次文件,且可以自动在从节点对归档文件解归档
*
*
*
*
*/
public class MapJoinMapper extends Mapper<LongWritable, Text, JoinBean, NullWritable>{
private JoinBean out_key=new JoinBean();
private Map<String, String> pdDatas=new HashMap<String, String>();
//在map之前手动读取pd.txt中的内容
@Override
protected void setup(Mapper<LongWritable, Text, JoinBean, NullWritable>.Context context)
throws IOException, InterruptedException {
//从分布式缓存中读取数据
URI[] files = context.getCacheFiles();
for (URI uri : files) {
BufferedReader reader = new BufferedReader(new FileReader(new File(uri)));
String line="";
//循环读取pd.txt中的每一行
while(StringUtils.isNotBlank(line=reader.readLine())) {
String[] words = line.split(" ");
pdDatas.put(words[0], words[1]);
}
reader.close();
}
}
//对切片中order.txt的数据进行join,输出
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, JoinBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
out_key.setOrderId(words[0]);
out_key.setPname(pdDatas.get(words[1]));
out_key.setAmount(words[2]);
context.write(out_key, NullWritable.get());
}
}
MapJoinDriver.java
public class MapJoinDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/mapjoin");
Path outputPath=new Path("e:/mroutput/mapjoin");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
job.setJarByClass(MapJoinDriver.class);
// 为Job创建一个名字
job.setJobName("wordcount");
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(MapJoinMapper.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置分布式缓存
job.addCacheFile(new URI("file:///e:/pd.txt"));
//取消reduce阶段
job.setNumReduceTasks(0);
// ③运行Job
job.waitForCompletion(true);
}
}