指对Reduce阶段的数据根据某一个或几个字段进行分组。
案例
需求
有如下订单数据
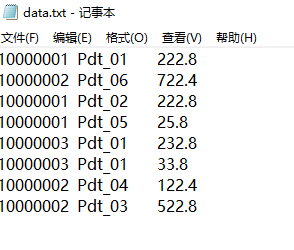
现在需要找出每一个订单中最贵的商品,如图

需求分析
-
利用“订单id和成交金额”作为
key,可以将Map阶段读取到的所有订单数据先按照订单id(升降序都可以),再按照acount(降序)排序,发送到Reduce。 -
在Reduce端利用
groupingComparator将订单id相同的kv聚合成组,然后取第一个成交金额即是最大值(若有多个成交金额并排第一,则都输出)。 -
Mapper阶段主要做三件事:
keyin-valuein
map()
keyout-valueout -
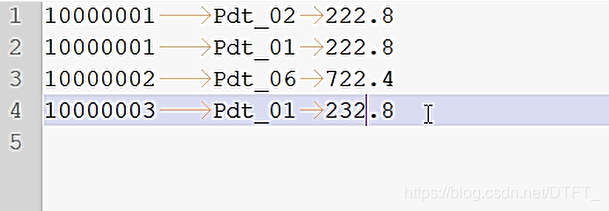
期待shuffle之后的数据:
10000001 Pdt_02 222.8
10000001 Pdt_01 222.8
10000001 Pdt_05 25.810000002 Pdt_06 722.4
10000002 Pdt_03 522.8
10000002 Pdt_04 122.410000003 Pdt_01 232.8
10000003 Pdt_01 33.8 -
Reducer阶段主要做三件事:
keyin-valuein
reduce()
keyout-valueout -
进入Reduce需要考虑的事
- 获取分组比较器,如果没设置默认使用MapTask排序时key的比较器
- 默认的比较器比较策略不符合要求,它会将orderId一样且acount一样的记录才认为是一组的
- 自定义分组比较器,只按照orderId进行对比,只要OrderId一样,认为key相等,这样可以将orderId相同的分到一个组!
在组内去第一个最大的即可
编写程序
利用“订单id和成交金额”作为key,所以把每一行记录封装为bean。由于需要比较ID,所以实现了WritableComparable接口
OrderBean.java
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private String pId;
private Double acount;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getpId() {
return pId;
}
public void setpId(String pId) {
this.pId = pId;
}
public Double getAcount() {
return acount;
}
public void setAcount(Double acount) {
this.acount = acount;
}
public OrderBean() {
}
@Override
public String toString() {
return orderId + " " + pId + " " + acount ;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(pId);
out.writeDouble(acount);
}
@Override
public void readFields(DataInput in) throws IOException {
orderId=in.readUTF();
pId=in.readUTF();
acount=in.readDouble();
}
// 二次排序,先按照orderid排序(升降序都可以),再按照acount(降序)排序
@Override
public int compareTo(OrderBean o) {
//先按照orderid排序升序排序
int result=this.orderId.compareTo(o.getOrderId());
if (result==0) {//订单ID相同,就比较成交金额的大小
//再按照acount(降序)排序
result=-this.acount.compareTo(o.getAcount());
}
return result;
}
}
自定义比较器,可以通过两种方法:
- 继承
WritableCompartor - 实现
RawComparator
MyGroupingComparator.java
//实现RawComparator
public class MyGroupingComparator implements RawComparator<OrderBean>{
private OrderBean key1=new OrderBean();
private OrderBean key2=new OrderBean();
private DataInputBuffer buffer=new DataInputBuffer();
@Override
public int compare(OrderBean o1, OrderBean o2) {
return o1.getOrderId().compareTo(o2.getOrderId());
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2);
}
}
MyGroupingComparator2.java
//继承WritableCompartor
public class MyGroupingComparator2 extends WritableComparator{
public MyGroupingComparator2() {
super(OrderBean.class,null,true);
}
public int compare(WritableComparable a, WritableComparable b) {
OrderBean o1=(OrderBean) a;
OrderBean o2=(OrderBean) b;
return o1.getOrderId().compareTo(o2.getOrderId());
}
}
OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
private OrderBean out_key=new OrderBean();
private NullWritable out_value=NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
out_key.setOrderId(words[0]);
out_key.setpId(words[1]);
out_key.setAcount(Double.parseDouble(words[2]));
context.write(out_key, out_value);
}
}
OrderReducer.java
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
/*
* OrderBean key-NullWritable nullWritable在reducer工作期间,
* 只会实例化一个key-value的对象!
* 每次调用迭代器迭代下个记录时,使用反序列化器从文件中或内存中读取下一个key-value数据的值,
* 封装到之前OrderBean key-NullWritable nullWritable在reducer的属性中
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
Double maxAcount = key.getAcount();
for (NullWritable nullWritable : values) {
if (!key.getAcount().equals(maxAcount)) {
break;
}
//复合条件的记录
context.write(key, nullWritable);
}
}
}
OrderBeanDriver.java
public class OrderBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\mrinput\groupcomparator");
Path outputPath=new Path("e:/mroutput/groupcomparator");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置自定义的分组比较器
job.setGroupingComparatorClass(MyGroupingComparator2.class);
// ③运行Job
job.waitForCompletion(true);
}
}
输出结果