一、理论学习
1、基本理论
对于定义一个类,都要继承nn.Module。在类里,通常不可缺少的两个函数分别是__init__()和forward()。__init__()函数首先调用父类的__init__()函数,再定义所需要的层以及所需要的操作;forward()前向函数将输入进行__init__()里定义的操作。
1 class MLP(nn.Module): 2 def __init__(self): 3 super().__init__() 4 self.hidden = nn.Linear(20, 256) 5 self.out = nn.Linear(256, 10) 6 7 def forward(self, X): 8 return self.out(F.relu(self.hidden(X)))
定义一个顺序块,用循环设置了_modules的字典,构造了一个类似nn.Sequential的类。
1 class MySequential(nn.Module): 2 def __init__(self, *args): 3 super().__init__() 4 for block in args: 5 self._modules[block] = block 6 7 def forward(self, X): 8 for block in self._modules.values(): 9 X = block(X) 10 return X 11 12 net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10)) 13 net(X)
在__init__()函数里可以定义网络,最后应用nn.Sequential实现各种组合块的混合搭配。
1 class NestMLP(nn.Module): 2 def __init__(self): 3 super().__init__() 4 self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(), 5 nn.Linear(64, 32), nn.ReLU()) 6 self.linear = nn.Linear(32, 16) 7 8 def forward(self, X): 9 return self.linear(self.net(X)) 10 11 chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP()) 12 chimera(X)
对于net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))来说,net[2]指的是nn.Sequential的最后一层,net[2].state_dict()指的是网络最后一层的参数,其中weight的大小是(8,1),bias的大小是一个标量。
一次显示所有参数,分别是访问net[0]即第一层的参数和访问net所有层的参数。因此也可以用net.state_dict()['2.bias'].data中的2.bias来访问第三层网络中的bias的值。
1 print(*[(name, param.shape) for name, param in net[0].named_parameters()]) 2 print(*[(name, param.shape) for name, param in net.named_parameters()])
网络嵌套可以先设计net = nn.Sequential(),再用net.add_module()给网络里嵌套别的网络。
可以设置函数对全连接层的weight和bias进行定义,再使用net.apply(定义的函数)将内置函数初始化。
参数绑定:将net的第三层和第五层设置为shared,哪怕修改了其中一个的权重的值,修改的是shared这个层,所以另一个也会改变。
1 shared = nn.Linear(8, 8) 2 net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), shared, nn.ReLU(), shared, 3 nn.ReLU(), nn.Linear(8, 1)) 4 net(X) 5 print(net[2].weight.data[0] == net[4].weight.data[0]) 6 net[2].weight.data[0, 0] = 100 7 print(net[2].weight.data[0] == net[4].weight.data[0])

自定义层和自定义网络本质上都是module的子类。
1 class CenteredLayer(nn.Module): 2 def __init__(self): 3 super().__init__() 4 5 def forward(self, X): 6 return X - X.mean() 7 8 layer = CenteredLayer() 9 layer(torch.FloatTensor([1, 2, 3, 4, 5]))
带参数的层要用到torch.nn.Parameter,该函数是继承自torch.Tensor的子类,其主要作用是作为nn.Module中的可训练参数使用。它与torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而module中非nn.Parameter()的普通tensor是不在parameter中的。
1 #带参数的层 2 class MyLinear(nn.Module): 3 def __init__(self, in_units, units): 4 super().__init__() 5 self.weight = nn.Parameter(torch.randn(in_units, units)) 6 self.bias = nn.Parameter(torch.randn(units,)) 7 8 def forward(self, X): 9 linear = torch.matmul(X, self.weight.data) + self.bias.data 10 return F.relu(linear) 11 12 linear = MyLinear(5, 3)
文件的读写还是比较简单的,张量列表读写是torch.save([x, y], 'x-files'),x2, y2 = torch.load('x-files');
1 x = torch.arange(4) 2 torch.save(x, 'x-file')#写数据 3 4 x2 = torch.load('x-file')#读数据 5 x2#tensor([0,1,2,3])
1 #张量列表 2 y = torch.zeros(4) 3 torch.save([x, y], 'x-files') 4 x2, y2 = torch.load('x-files') 5 (x2, y2) 6 7 #字典读取 8 mydict = {'x': x, 'y': y} 9 torch.save(mydict, 'mydict') 10 mydict2 = torch.load('mydict') 11 mydict2
2、卷积
对全连接层应用平移不变性和局部性得到卷积层,平移不变性指的是卷积核不随位置变化而变化,即共享权重;局部性指的是感受野对领域有效。卷积层是一个卷积核从左到右、从上至下遍历整个输入,卷积和二维交叉由于对称性,实际应用没有区别。
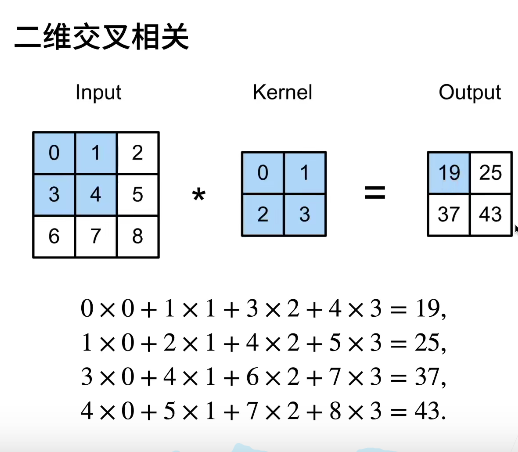
对该图片的相关实现如下所示:
1 def corr2d(X, K): 2 """计算二维互相关运算。""" 3 h, w = K.shape 4 Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) 5 for i in range(Y.shape[0]): 6 for j in range(Y.shape[1]): 7 Y[i, j] = (X[i:i + h, j:j + w] * K).sum() 8 return Y 9 10 X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) 11 K = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) 12 corr2d(X, K)
设置一个二维卷积,可以直接采用nn.Conv2d设置输入层输出层和卷积核大小,以下是二维卷积的实现:conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad做了backward之后grad有了值,与自定义的学习率相乘不断更新权重。
1 conv2d = nn.Conv2d(1, 1, kernel_size=(1, 2), bias=False) 2 3 X = X.reshape((1, 1, 6, 8)) 4 Y = Y.reshape((1, 1, 6, 7)) 5 6 for i in range(10): 7 Y_hat = conv2d(X) 8 l = (Y_hat - Y)**2 9 conv2d.zero_grad() 10 l.sum().backward() 11 conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad 12 if (i + 1) % 2 == 0: 13 print(f'batch {i+1}, loss {l.sum():.3f}')
3、填充和步长
填充指的是在周围添加padding,规范化的padding使得原先是h*w的输入填充后是(h+padding*2)*(w+padding*2),一般情况下:

步幅指的是行和列的滑动步长
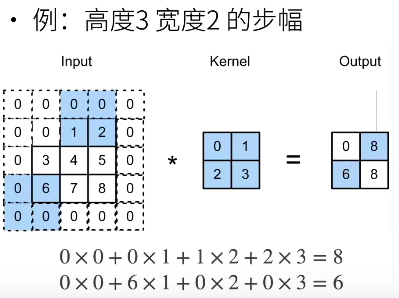
下图中原尺寸为8*8,增加了两边为1的padding后尺寸为10*10,卷积核大小为3*3,所以最后输出的尺寸大小为10-3+1=8,尺寸不变。


此处(image_shape-filter_shape+2*padding)/stride + 1,(8-3+2)/2+1=4
1 conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2) 2 comp_conv2d(conv2d, X).shape
此处(8-3+2*0)/3+1=2,(8-5+2*1)/4+1=2
1 conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4)) 2 comp_conv2d(conv2d, X).shape
彩色图像通常有三个通道,对于多个通道数来说,每个通道都有一个卷积核,结果是所有通道卷积结果的和。
将三个卷积核在0维度上压栈,可得到输出3,输入2(与X的通道数相同),高和宽分别是2
1 def corr2d_multi_in_out(X, K): 2 return torch.stack([corr2d_multi_in(X, k) for k in K], 0) 3 4 K = torch.stack((K, K + 1, K + 2), 0) 5 K.shape#torch.size([3,2,2,2])
4、池化层:输出通道=输入通道,缓解卷积层位置的敏感性
最大池化:选择窗口里最大值;平均池化:选择窗口里平均值。
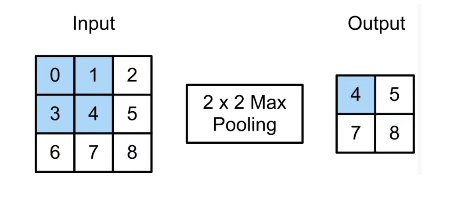
首先获取池化层的高和宽,与卷积类似进行计算,对于mode为max和avg分别对应最大池化和平均池化。简便方法可以调用nn.MaxPool2d(窗口大小=number,padding=number,stride=number)进行池化,number不仅可以是个值,也可以设为任意大小的窗口。深度学习框架中的步幅与池化窗口的大小相同。
1 def pool2d(X, pool_size, mode='max'): 2 p_h, p_w = pool_size 3 Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) 4 for i in range(Y.shape[0]): 5 for j in range(Y.shape[1]): 6 if mode == 'max': 7 Y[i, j] = X[i:i + p_h, j:j + p_w].max() 8 elif mode == 'avg': 9 Y[i, j] = X[i:i + p_h, j:j + p_w].mean() 10 return Y
二、猫狗大战
1、先去官网下载数据,对数据进行预处理:
首先是解压数据集
1 pip install pyunpack 2 !pip install patool 3 from pyunpack import Archive 4 Archive('/content/drive/MyDrive/test_learn/cat_dog.rar').extractall('/content/drive/MyDrive/test_learn')
创建文件夹,对给定图像的类别放在相应文件夹里
1 !ls drive//MyDrive/test_learn/cat_dog/train 2 %cd drive//MyDrive/test_learn/cat_dog/train 3 !mkdir cat dog 4 %cd .. 5 %cd val 6 !mkdir cat dog 7 %cd .. 8 !mv train/cat*.jpg train/cat/ 9 !mv train/dog*.jpg train/dog/ 10 !mv val/cat*.jpg val//cat/ 11 !mv val/dog*.jpg val/dog/
创建dataset和dataloader,由于数据的尺寸不一致,需要做transform,构建好数据集
1 cd_path = '/content/drive/MyDrive/test_learn/cat_dog' 2
9 10 #训练时可以打乱顺序增加多样性,测试时没有必要,所以shuffle=False 11 dataset={x:datasets.ImageFolder(root=os.path.join(cd_path,x),transform=data_transform) for x in ['train','val']} 12 trainloader=torch.utils.data.DataLoader(dataset=dataset['train'],batch_size=64,shuffle=True,num_workers=6) 13 #testloader=torch.utils.data.DataLoader(dataset=dataset['test'],batch_size=64,shuffle=False,num_workers=6) 14 valloader=torch.utils.data.DataLoader(dataset=dataset['val'],batch_size=64,shuffle=False,num_workers=6)
创建LeNet模型,主要是依据李沐的课程源码
1 device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 2 class LeNet(nn.Module): 3 def __init__(self): 4 super().__init__() 5 self.classifier = nn.Sequential(nn.Conv2d(3, 6, kernel_size=5), nn.Sigmoid(), 6 nn.AvgPool2d(kernel_size=2, stride=2), 7 nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(), 8 nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), 9 nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(), 10 nn.Linear(120, 84), nn.Sigmoid(), nn.Linear(84, 2)) 11 def forward(self, img): 12 cls = self.classifier(img) 13 return cls 14 model = LeNet().to(device)
损失函数使用交叉熵损失函数,优化器选择SGD随机梯度下降函数
1 criterion = nn.CrossEntropyLoss() 2 optimizer = torch.optim.SGD(model.parameters(), lr=0.1, weight_decay=0.01, momentum=0.9)
预训练和测试代码用的是之前的代码,发现之前的错误是对数据的裁剪不对,不能因为LeNet的输入大小就裁剪到那样的大小。
训练的数据跑的真慢,不过正确率还在慢慢提升,5个epoch已经从0.5提升到0.61了,继续训练吧。。。明天再来更新