数据聚合
1、
可以让我们极其方便的实现对数据的统计、分析、运算。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合常见的有三类:
桶(Bucket)聚合:用来对文档做分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
语法如下:
GET /hotel/_search { "size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果 "aggs": { // 定义聚合 "brandAgg": { //给聚合起个名字 "terms": { // 聚合的类型,按照品牌值聚合,所以选择term "field": "brand", // 参与聚合的字段 "size": 20 // 希望获取的聚合结果数量 } } } }结果:
二、聚合排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为count,并且按照count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search { "size": 0, "aggs": { "brandAgg": { "terms": { "field": "brand", "order": { "_count": "asc" // 按照_count升序排列 }, "size": 20 } } } }三、限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search { "query": { "range": { "price": { "lte": 200 // 只对200元以下的文档聚合 } } }, "size": 0, "aggs": { "brandAgg": { "terms": { "field": "brand", "size": 20 } } } }四、Metric聚合
GET /hotel/_search { "size": 0, "aggs": { "brandAgg": { "terms": { "field": "brand", "size": 20 }, "aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算 "score_stats": { // 聚合名称 "stats": { // 聚合类型,这里stats可以计算min、max、avg等 "field": "score" // 聚合字段,这里是score } } } } } }结果:

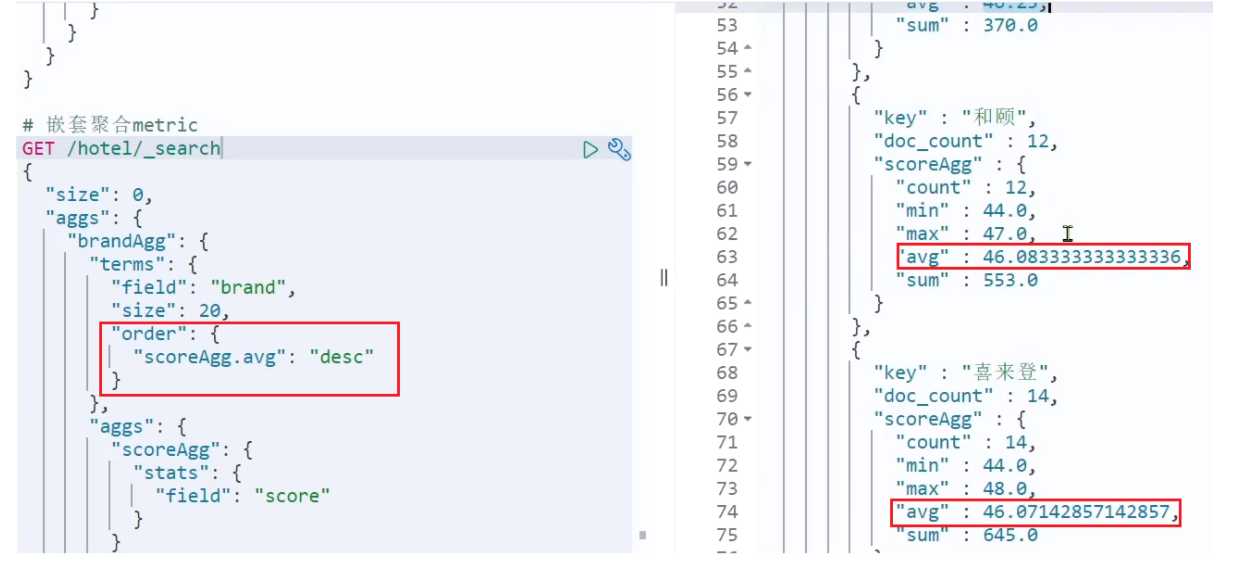
aggs代表聚合,与query同级,此时query的作用是?
限定聚合的的文档范围
聚合必须的三要素:
聚合名称
聚合类型
聚合字段
聚合可配置属性有:
size:指定聚合结果数量
order:指定聚合结果排序方式
field:指定聚合字段
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:
测试代码:
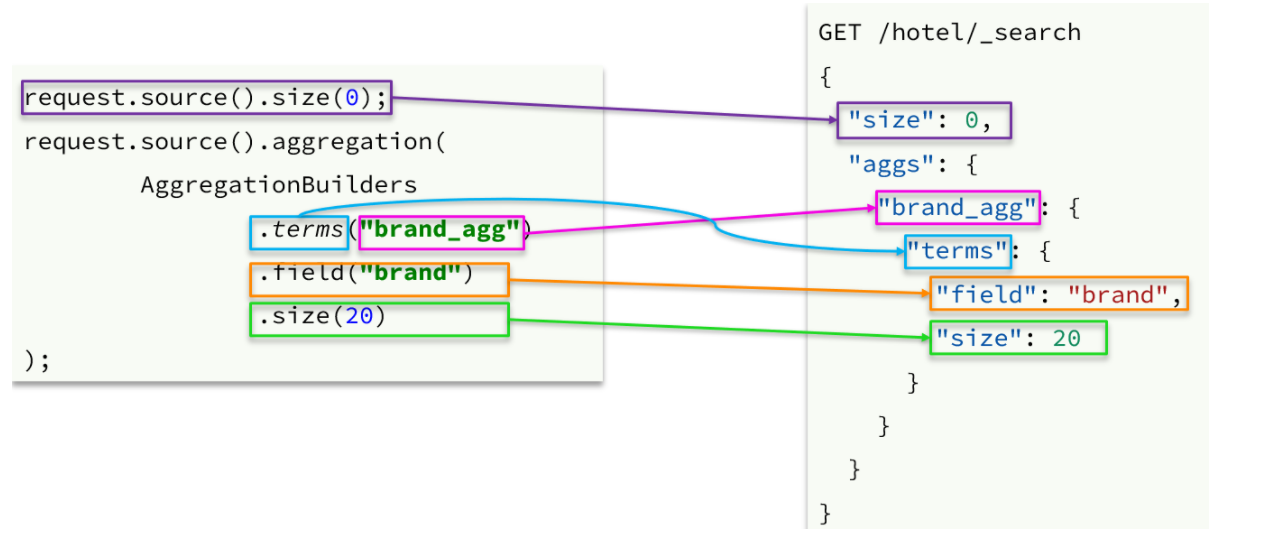
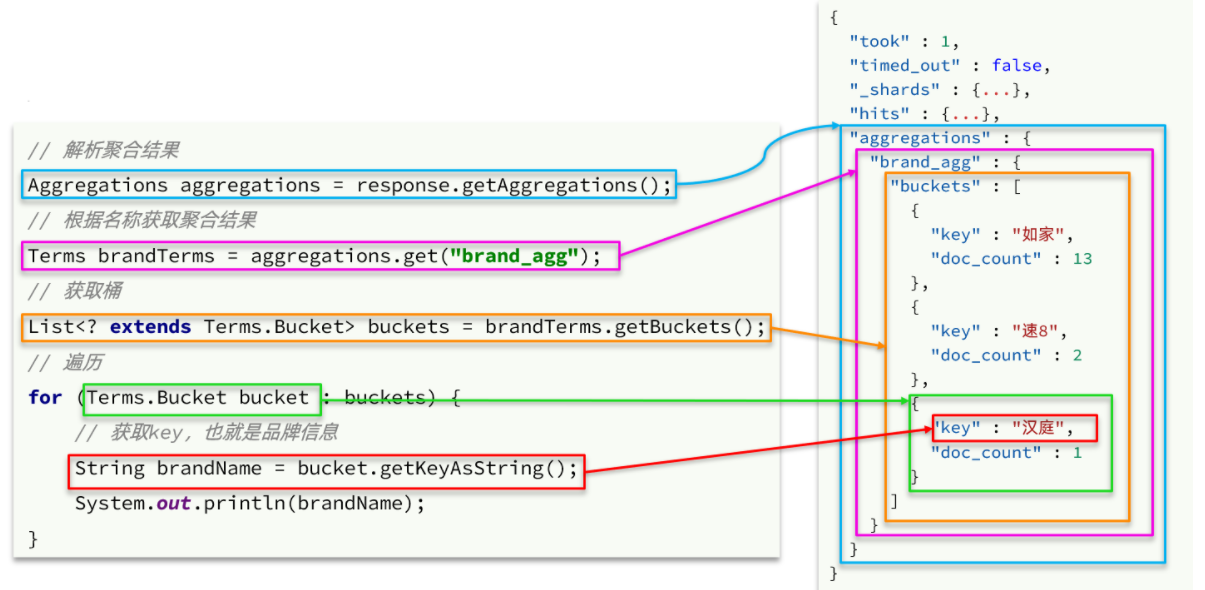
@Test public void terms() throws IOException { // 1 构建查询请求 SearchRequest request = new SearchRequest("hotel"); // 2 构造DSL request.source().size(0); request.source().aggregation(AggregationBuilders .terms("brandAggs") .field("brand") .size(10) ); // 3 发起查询,获取响应 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4 解析响应 Aggregations aggregations = response.getAggregations(); Terms terms = aggregations.get("brandAggs"); List<? extends Terms.Bucket> buckets = terms.getBuckets(); for (Terms.Bucket bucket : buckets) { System.out.println(bucket.getKeyAsString()+"-"+bucket.getDocCount()); } }
自动补全
拼音分词器下载路径:https://www.aliyundrive.com/s/cQ8BsrS13nN
测试:
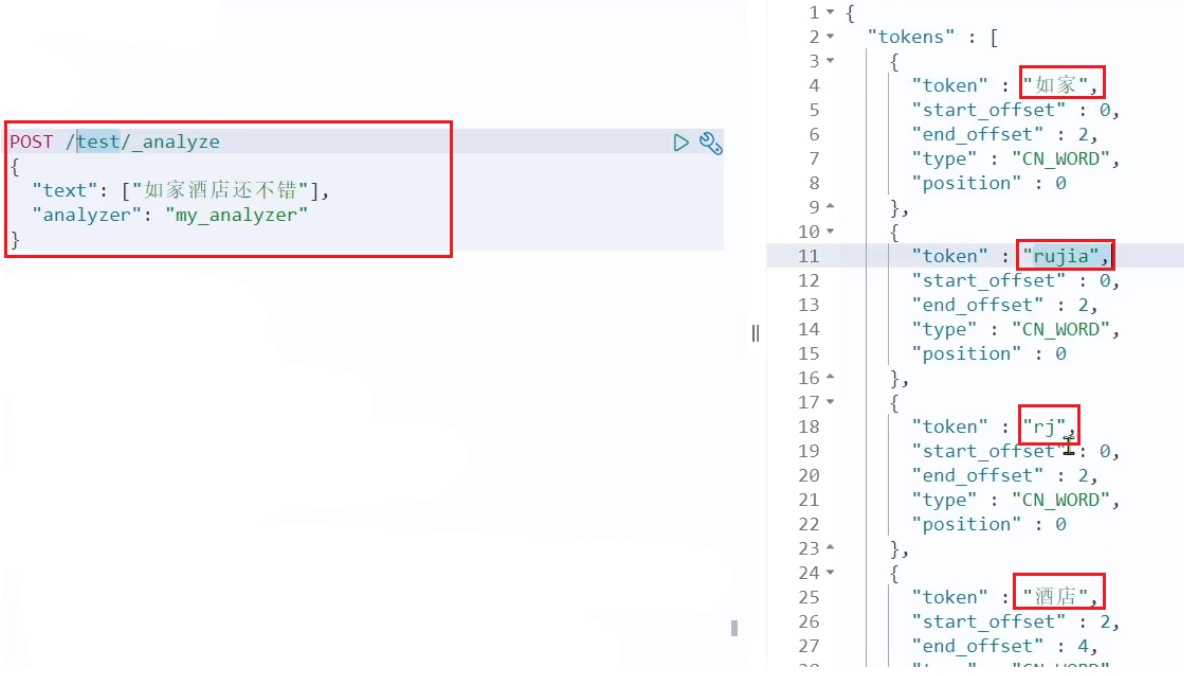
POST /_analyze { "text": "如家酒店还不错", "analyzer": "pinyin" }
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
声明自定义分词器的语法如下:
PUT /test { "settings": { "analysis": { "analyzer": { // 自定义分词器 "my_analyzer": { // 分词器名称 "tokenizer": "ik_max_word", "filter": "py" } }, "filter": { // 自定义tokenizer filter "py": { // 过滤器名称 "type": "pinyin", // 过滤器类型,这里是pinyin "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "name": { "type": "text", "analyzer": "my_analyzer", "search_analyzer": "ik_smart" } } } }测试:

如何使用拼音分词器?
①下载pinyin分词器
②解压并放到elasticsearch的plugin目录
③重启即可
如何自定义分词器?
①创建索引库时,在settings中配置,可以包含三部分
②character filter
③tokenizer
④filter
拼音分词器注意事项?
为了避免搜索到同音字,搜索时不要使用拼音分词器
elasticsearch提供了
参与补全查询的字段必须是completion类型。
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库 PUT test { "mappings": { "properties": { "title":{ "type": "completion" } } } }然后插入下面的数据:
// 示例数据 POST test/_doc { "title": ["Sony", "WH-1000XM3"] } POST test/_doc { "title": ["SK-II", "PITERA"] } POST test/_doc { "title": ["Nintendo", "switch"] }查询的DSL语句如下:
// 自动补全查询 GET /test/_search { "suggest": { "title_suggest": { "text": "s", // 关键字 "completion": { "field": "title", // 补全查询的字段 "skip_duplicates": true, // 跳过重复的 "size": 10 // 获取前10条结果 } } } }
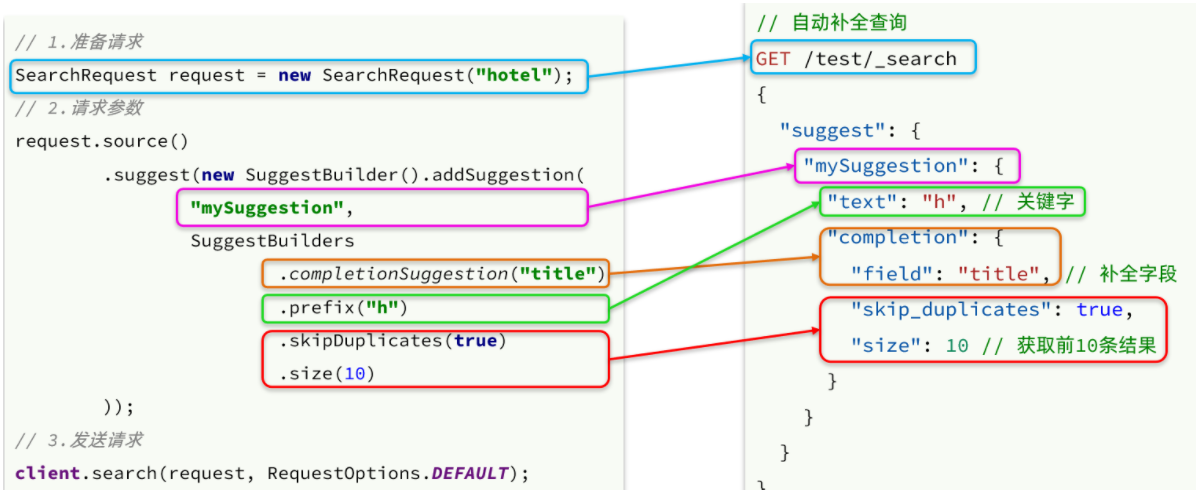
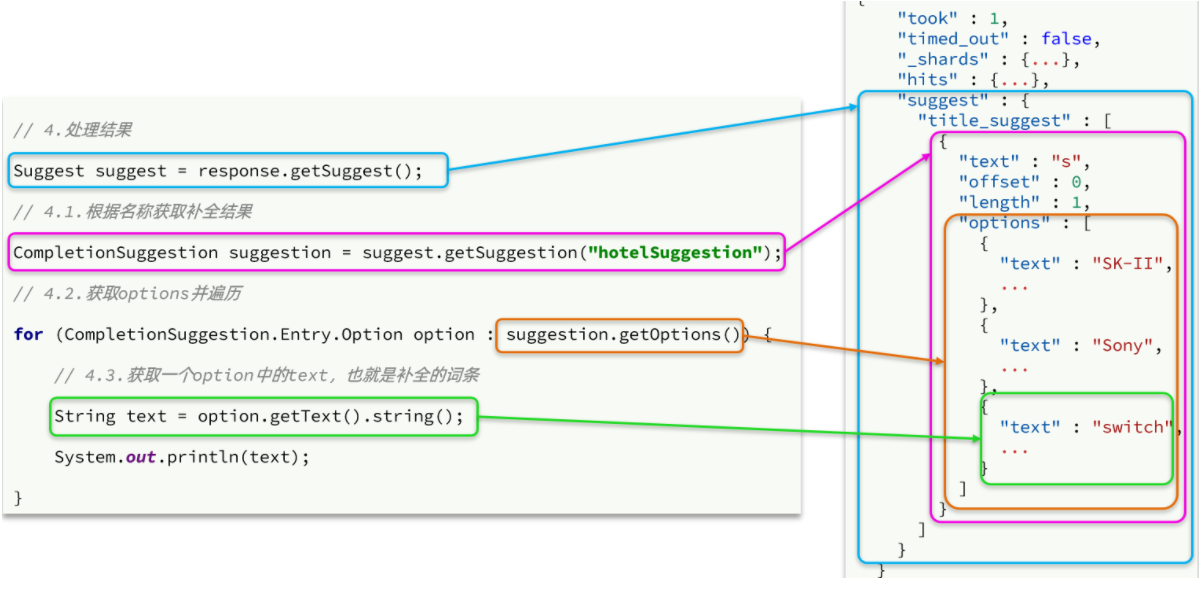
4、自动补全的JavaAPI
而自动补全的结果也比较特殊,解析的代码如下:
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
方案一:同步调用
基本步骤如下:
hotel-demo对外提供接口,用来修改elasticsearch中的数据
酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
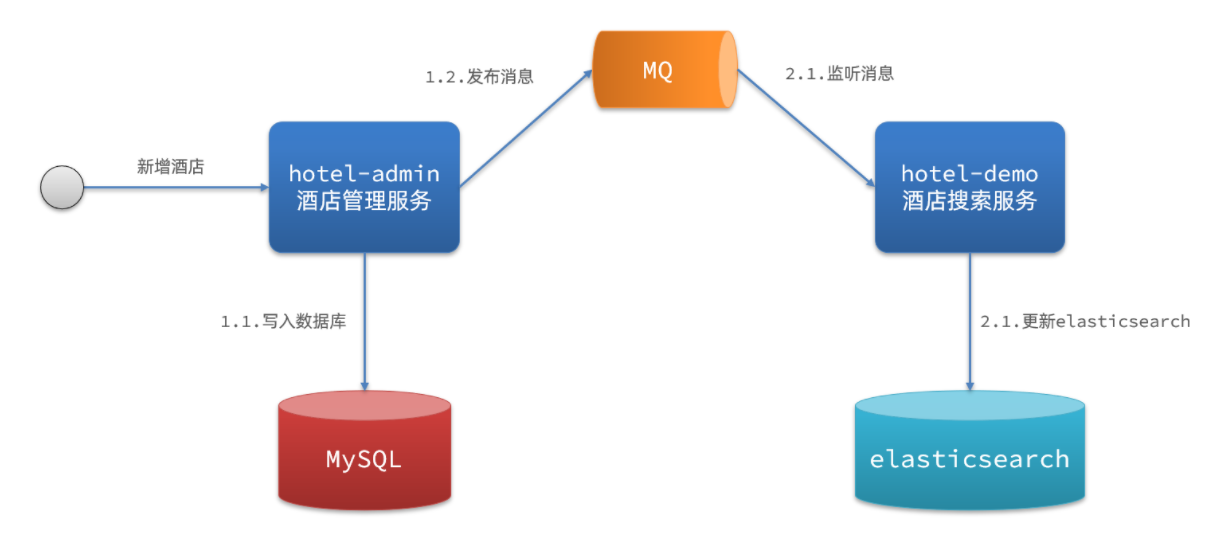
方案二:异步通知
流程如下:
hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
方案三:监听binlog
流程如下:
给mysql开启binlog功能
mysql完成增、删、改操作都会记录在binlog中
hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
方式一:同步调用
优点:实现简单,粗暴
缺点:业务耦合度高
方式二:异步通知
优点:低耦合,实现难度一般
缺点:依赖mq的可靠性
方式三:监听binlog
优点:完全解除服务间耦合
缺点:开启binlog增加数据库负担、实现复杂度高


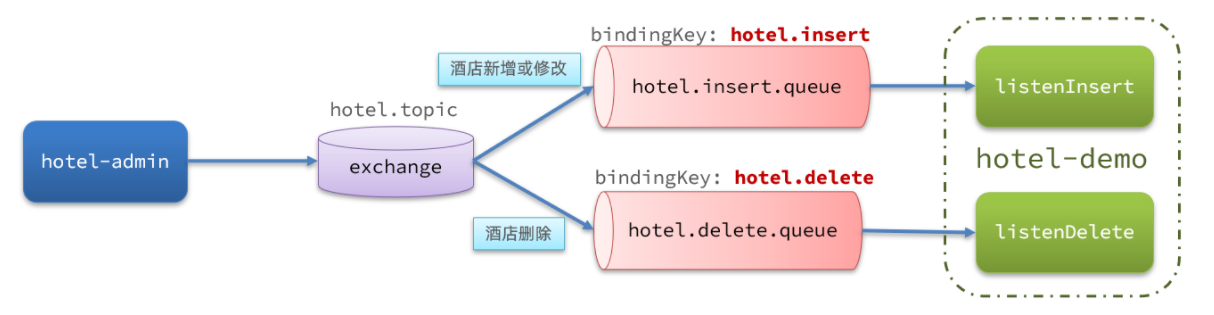
1、MQ方式实现数据同步
集群
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
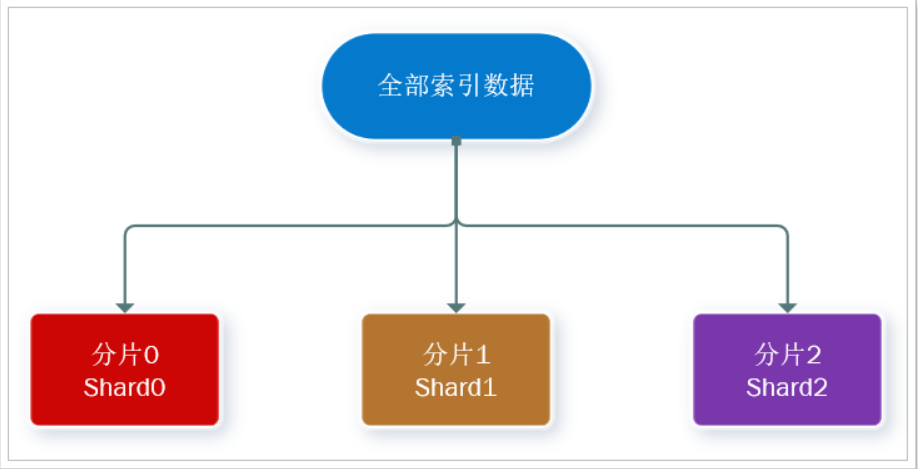
海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念:
集群(cluster):一组拥有共同的 cluster name 的 节点。
节点(node) :集群中的一个 Elasticearch 实例
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
此处,我们把数据分成3片:shard0、shard1、shard2
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
首先对数据分片,存储到不同节点
然后对每个分片进行备份,放到对方节点,完成互相备份
1、集群搭建
2、集群的脑裂问题
一、集群的职责划分
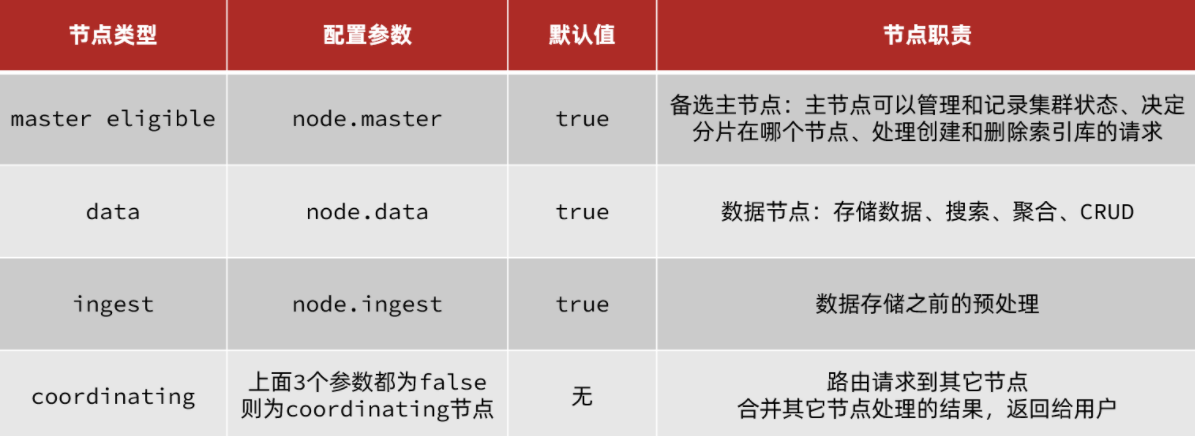
elasticsearch中集群节点有不同的职责划分:
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
master节点:对CPU要求高,但是内存要求第
data节点:对CPU和内存要求都高
coordinating节点:对网络带宽、CPU要求高
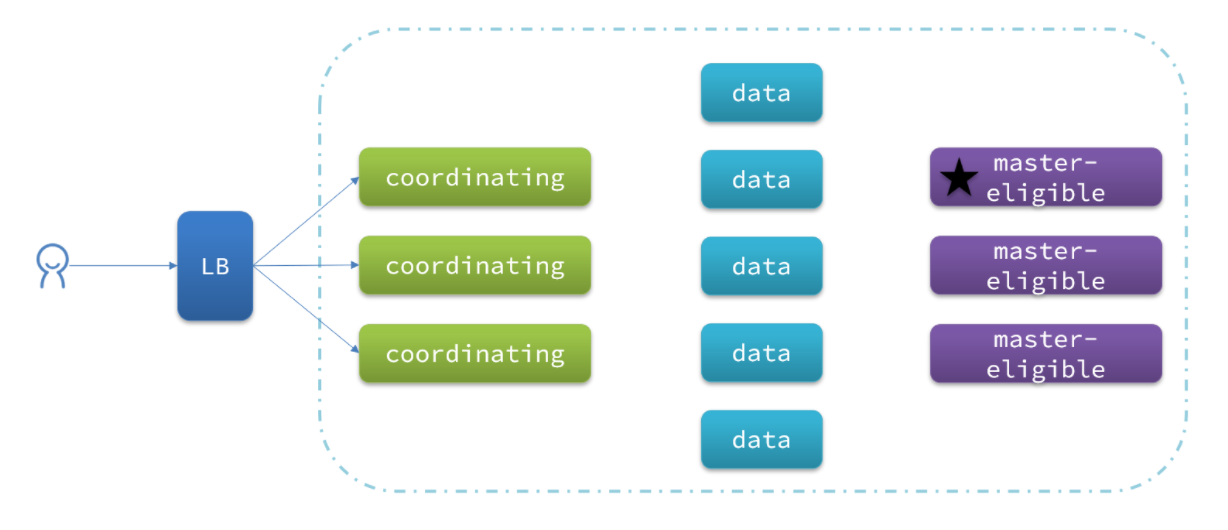
一个典型的es集群职责划分如图:
二、脑裂问题
脑裂是因为集群中的节点失联导致的。
失联导致集群中的master节点在新产生集群中重新选举主节点,当故障或网络等异常情况恢复后,出现同一集群出现多个主节点的现象。
解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
总结:
master eligible节点的作用是什么?
参与集群选主
主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
数据的CRUD
coordinator节点的作用是什么?
路由请求到其它节点
合并查询到的结果,返回给用户
2、集群的分布式存储
一、分片存储的原理
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:
说明:
_routing默认是文档的id
算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
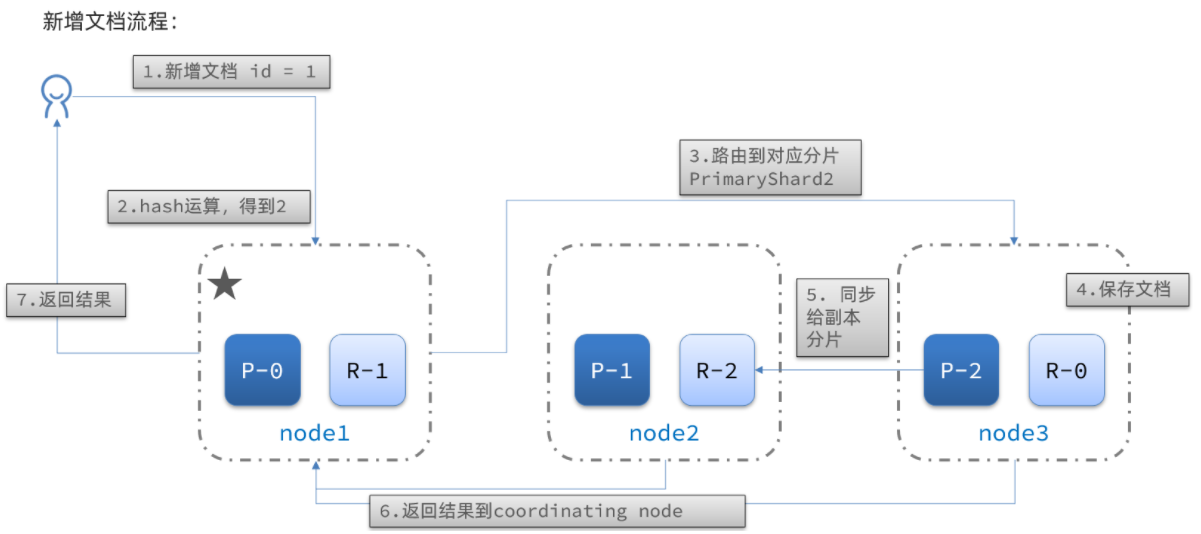
新增文档的流程如下:
解读:
1)新增一个id=1的文档
2)对id做hash运算,假如得到的是2,则应该存储到shard-2
3)shard-2的主分片在node3节点,将数据路由到node3
4)保存文档
5)同步给shard-2的副本replica-2,在node2节点
6)返回结果给coordinating-node节点
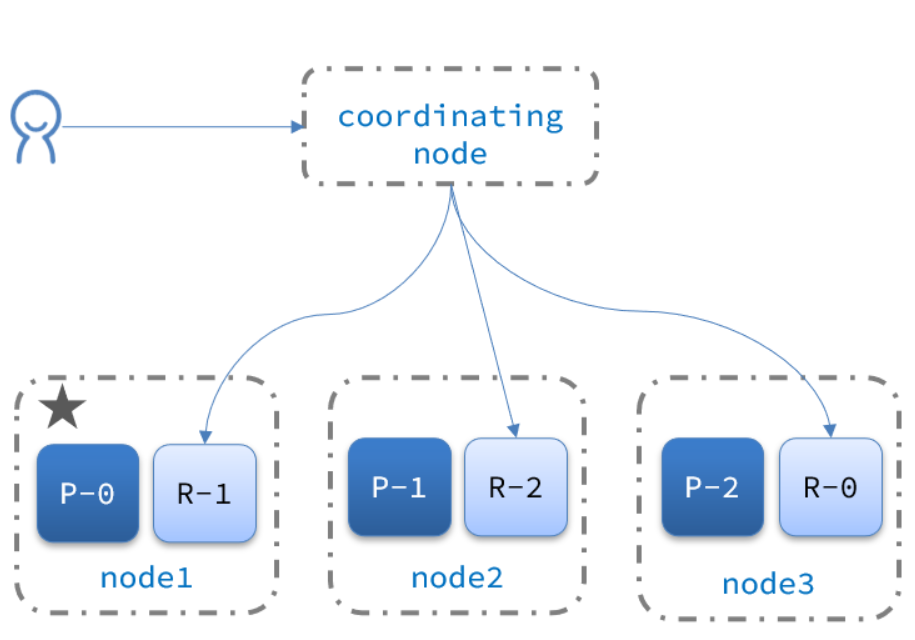
二、集群的分布式查询
elasticsearch的查询分成两个阶段:
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
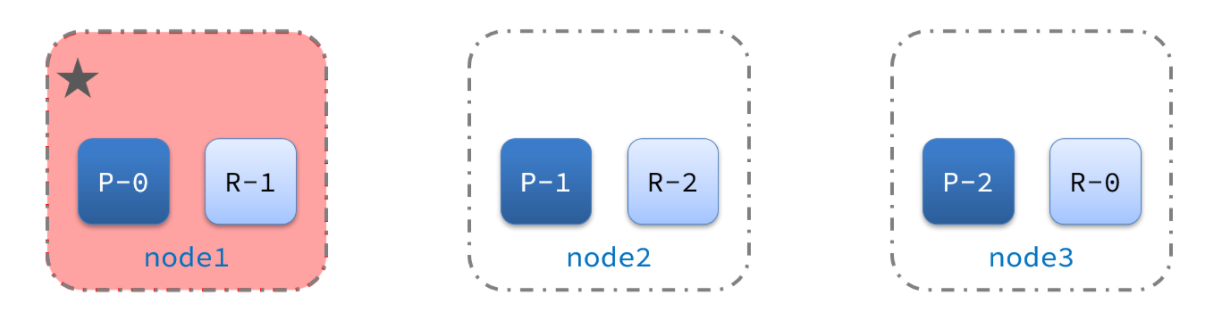
三、集群的故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
1)例如一个集群结构如图:
现在,node1是主节点,其它两个节点是从节点。
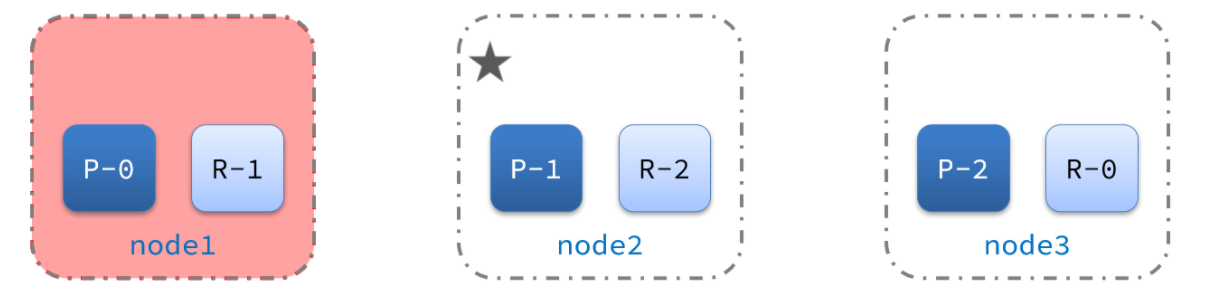
2)突然,node1发生了故障:
宕机后的第一件事,需要重新选主,例如选中了node2:
node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点。因此需要将node1上的数据迁移到node2、node3: