语言模型
由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果。这是改进OCR识别效果的重要方法之一。
转移概率
在我们分析实验结果的过程中,有出现这一案例。由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择。但是语言模型却可以很巧妙地解决这个问题。原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”。
从概率的角度来看,就是对于第一个字的区域的识别结果s1,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率W(s1)分别为0.99996、0.00004;第二个字的区域的识别结果s2,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率W(s2)分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”。
下面考虑它们的迁移概率。所谓迁移概率,其实就是条件概率P(s1|s2),即当s1出现时后面接s2的概率。通过10万微信文本,我们统计出,“电”字出现的次数为145001,而“电柳”、“电视“、”电规“出现的次数为0、12426、7;“宙”字出现的次数为1980次,而“宙柳”、“宙视”、“宙规”出现的次数为0、0、18,因此,可以算出

结果如下图:
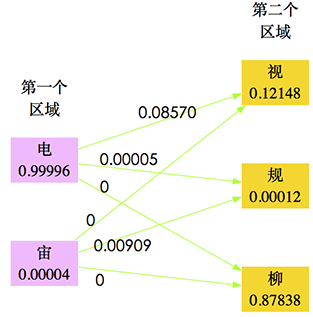
图20 考虑转移概率
从统计的角度来看,最优的s1,s2组合,应该使得式(14)取最大值:
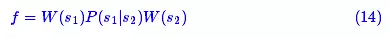
因此,可以算得s1,s2的最佳组合应该是“电视”而不是“电柳”。这时我们成功地通过统计的方法得到了正确结果,从而提高了正确率。
动态规划
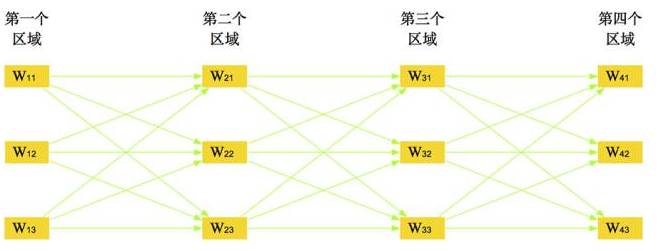
图21 多字图片的规划问题
类似地,如图21,如果一个单行文字图片有n个字 需要确定,那么应当使得
需要确定,那么应当使得
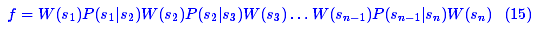
取得最大值,这就是统计语言模型的思想,自然语言处理的很多领域,比如中文分词、语音识别、图像识别等,都用到了同样的方法[6]。这里需要解决两个主要的问题:(1)各个 的估计;(2)给定各个
的估计;(2)给定各个 后如何求解f的最大值。
后如何求解f的最大值。
转移概率矩阵
对于第一个问题,只需要从大的语料库中统计si的出现次数#si,以及si,si+1相接地出现的次数#(si,si+1),然后认为

即可,本质上没有什么困难。本文的识别对象有3062个,理论上来说,应该生成一个3062×3062的矩阵,这是非常庞大的。当然,这个矩阵是非常稀疏的,我们可以只保存那些有价值的元素。
现在要着重考虑当#(si,si+1)=0的情况。在前一节我们就直接当P(si|si+1)=0,但事实上是不合理的。没有出现不能说明不会出现,只能说明概率很小,因此,即便是对于#(si,si+1)=0,也应该赋予一个小概率而不是0。这在统计上称为数据的平滑问题。
一个简单的平滑方法是在所有项的频数(包括频数为0的项)后面都加上一个正的小常数α(比如1),然后重新统计总数并计算频率,这样每个项目都得到了一个正的概率。这种思路有可能降低高频数的项的概率,但由于这里的概率只具有相对意义,因此这个影响是不明显的(一个更合理的思路是当频数小于某个阈值T时才加上常数,其他不加。)。按照这种思路,从数十万微信文章中,我们计算得到了160万的邻接汉字的转移概率矩阵。
Viterbi算法
对于第二个问题,求解最优组合 是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6]。
是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6]。
Viterbi算法是一个简单高效的算法,用Python实现也就十来行的代码。它的核心思想是:如果最终的最优路径经过某个si−1,那么从初始节点到si−1点的路径必然也是一个最优路径——因为每一个节点si只会影响前后两个P(si−1|si)和P(si|si+1)。
根据这个思想,可以通过递推的方法,在考虑每个si时只需要求出所有经过各si−1的候选点的最优路径,然后再与当前的si结合比较。这样每步只需要算不超过 次,就可以逐步找出最优路径。Viterbi算法的效率是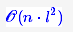 ,l 是候选数目最多的节点si的候选数目,它正比于n,这是非常高效率的。
,l 是候选数目最多的节点si的候选数目,它正比于n,这是非常高效率的。
提升效果
实验表明,结合统计语言模型进行动态规划能够很好地解决部分形近字识别错误的情况。在我们的测试中,它能修正一些错误如下:

通过统计语言模型的动态规划能修正不少识别错误
由于用来生成转移矩阵的语料库不够大,因此修正的效果还有很大的提升空间。不管怎么说,由于Viterbi算法的简单高效,这是一个性价比很高的步骤。
综合评估
1、数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准。在本节中,我们通过自己的模型,与京东的测试数据进行比较验证。
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别。我们采用评分的方法,对每一张图片的识别效果进行评分。评分规则如下:
-
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数。
按照这个规则,每张图片的评分最多是2分,最少是0分。如果评分超过1,说明识别效果比较好了。经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
2、模型综述
在本文中,我们的目标是建立一个完整的OCR系统,经过一系列的工作,我们也基本完成了这一目标。
在设计算法时,我们紧密地结合基本假设,从模拟人肉眼的识别思路出发,希望能够以最少的步骤来实现目标,这种想法在特征提取和文字定位这两部分得到充分体现。
同样地,由于崇尚简洁和模拟人工,在光学字符识别方面,我们选择了卷积神经网络模型,得到了较高的正确率;最后结合语言模型,通过动态规划用较简单的思路提升了效果。
经过测试,我们的系统对印刷文字的识别有着不错的效果,可以作为电商、微信等平台的图片文字识别工具。其中明显的特点是,我们的系统可以将整张文字图片输入,并且在分辨率不高的情况下能够获得较好的效果。
3、结果反思
在本文所涉及到的算法中,一个很大的不足之处就是有很多的“经验参数”,比如聚类时h参数的选择、低密度区定义中密度的阈值、卷积神经网络中的卷积核数据、隐藏层节点数目等。由于并没有足够多的标签样本进行研究,因此,这些参数都只能是凭借着经验和少量的样本推算得出。我们期待会有更多的标签数据来得到这些参数的最优值。
还有,在识别文字区域方面,还有很多值得改进的地方。虽然我们仅仅是经过几个步骤就去掉了大部分的文字区域,但是这些步骤还是欠直观,亟待简化。我们认为,一个良好的模型应该是基于简单的假设和步骤就能得到不错的效果,因此,值得努力的工作之一就是简化假设,缩减流程。
此外,在文本切割方面,事实上不存在一种能够应对任何情况的自动切割算法,因此这一步还有很大的提升空间。据相关文献,可以通过CNN+LSTM模型,直接对单行文本进行识别,但这需要大量的训练样本和高性能的训练机器,估计只有大型企业才能做到这一点。
显然,还有很多工作都需要更深入地研究。