在 Python 尤其是 Python2 中,编码问题是困扰开发者尤其初学者的一大问题。什么 Unicode/UTF-8/str ,又是 decode/encode 的,搞得人头都大了。其实不然,这有点类似 Java 中 java.io 包一样,看似庞大难懂,但是可以非常精细地定制需求。

编码
计算机只可以存储和处理二进制数据,所以从文字到计算机可以识别的二进制之间需要一道对应关系。于是便有了ASCII(American Standard Code for Information Interchange,美国标准信息交换代码),ASCII使用7位二进制数标记了128(2**7)字符(符号、字母、控制符等),由于1byte=8bit,所以干脆最高位补个0,凑够8位以方便计算和处理。
接着,拉丁语系的技术宅们发现,这128个字符的高位空着的,那么干脆用来表示拉丁语系的主要符号吧,还是使用单字节,但是可以表示的字符数量增加了一倍。这套编码叫做latin-1(iso-8859-1)。
这些宅男们没有想到,区区一个字节256个符号,对于东亚国家来讲,简直呵呵了。拿中文为例,仅常用字符就几千个,于是中国国家标准总局制定了一套中文编码——GB2312。GB2312通过两个字节表示一个汉字,且最高位为0的部分兼容ASCII,最高位为1的部分则通过连续的两个字节表示一个中文字。后来又出现了兼容GB2312的GBK编码。
到这里,依然面临了一个问题:GB2312或者GBK编码中,仅可以表示汉字和英文字符,无法做到多语言文字同时表示。这时候,Unicode(又称万国码)出现了。Unicode采用32位二进制(4字节)表示一个字符,这样便可以一套编码对应多种不同语言。Unicode是一种编码,它的作用是指定字符到二进制数之间的对应关系。但是对于存储和传输,Unicode有几种不同的实现,比较常用的是UTF-8、UTF-16、UTF-32。UTF-32中,每个字符固定占4字节,按照Unicode编码完全映射。而UTF-8和UTF-16则属于变长编码,分别使用最少1个(UTF-8)或2个(UTF-16)字节到最多4个字节来编码。
Python源码的编码
Python2中,如果在源码首行(或在指定sha-bang时的第二行)不显式指定编码,则无法在源码中出现非ASCII字符。这是由于Python解释器默认将源码认作ASCII编码格式。PEP263(点击这里查看)中约定,可以通过如下方式之一来声明源码的编码格式:
# coding=<coding name>
# or
# -*- coding: <encoding name> -*-
# or
# vim: set fileencoding=<encoding name> :
Python中的编码
Python中有两个常用的由basestring派生出来的表示字符串的类型:str,unicode。其中,str类似于C中的字符数组或者Java中的byte数组,事实上你可以将它理解为一个存储二进制内容的容器,str不存储编码信息,如果对str类型的字符串迭代的话,则会按照其在内存中的字节序依次迭代,意味着如果这个字符串存储的是多字节字符(Unicode/GBK等),则会截断这个字符,演示如下:
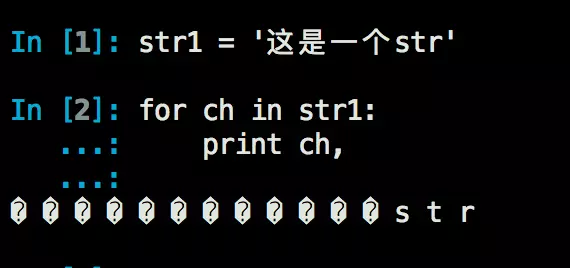
而对于unicode类型,Python在内存中存储和使用的时候是按照UTF-8格式,在代码中的表示为字符串前加u,如:
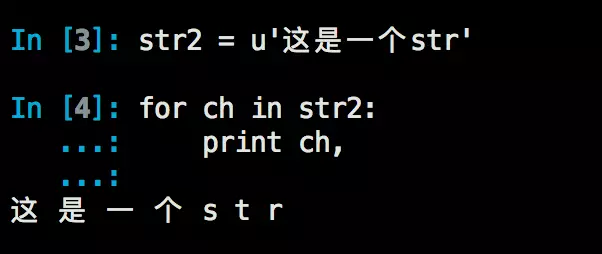
而unicode与str之间的转换,则用到了encode和deocde方法。decode表示将一个(str)字符串按照给定的编码解析为unicode类型,encode则表示将一个unicode字符串按照指定编码解析为字节数组(str):


文件读写
内置的open函数打开文件时,read方法读取的是一个str(私以为叫做字节数组更合适),如果读取的是其它编码的文字,则需要decode之后再做使用。
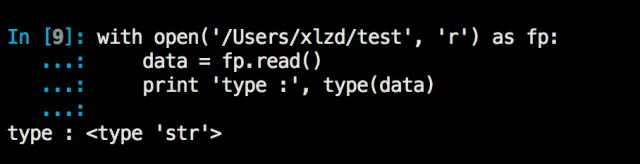
对于使用open函数打开文件之后的写操作(多字节编码的字符串),则需要将需要写入的字符串按照其编码encode为一个str,如果直接写入,则会引发如下错误(如果在代码中加入了encoding声明,则会按照声明的编码格式encode后写入):

除此以外,codecs模块也提供了一个open函数,可以直接指定好编码打开一个文本文件,那么读取到的文件内容则直接是一个unicode字符串。对应的指定编码后的写入文件,则可以直接将unicode写到文件中。通过codecs.open可以避免很多编码问题:

建议
对于Python代码中避免遇到编码问题,有一些小建议:
-
字符编码声明:在代码开头声明编码格式
-
使用codecs的open函数处理文本文件
-
尽可能使用unicode而不是str:在所有字符串的引号前加u