关系型数据库与非关系型数据库的缺点和优点:
关系型数据库优点:
- 数据之间有关系,进行数据的增删改查时非常方便
- 关系型数据库有事务操作,保证数据的完整性。
缺点:
- 大量算法会拉低系统运行速度
- 大量算法会消耗系统资源
- 海量数据的增删改查时会显得无能为力
- 海量数据环境下对数据表进行维护/扩展,也会变得无能为力
总结:适合处理一般量级数据,安全!
因此,为了处理海量数据,需要将关系型数据库的关系去掉。
非关系型数据库(NoSQL):
设计之初是为了替代关系型数据库的。
优点:
-
- 海量数据的增删改查,非常轻松应对
- 海量数据的维护非常轻松
缺点:
-
- 数据与数据之间没有关系,所以不能一目了然
- 非关系型数据库,没有关系,没有强大的事务保证数据的完整和安全。
适合处理海量数据,保证效率,但是不一定保证安全。
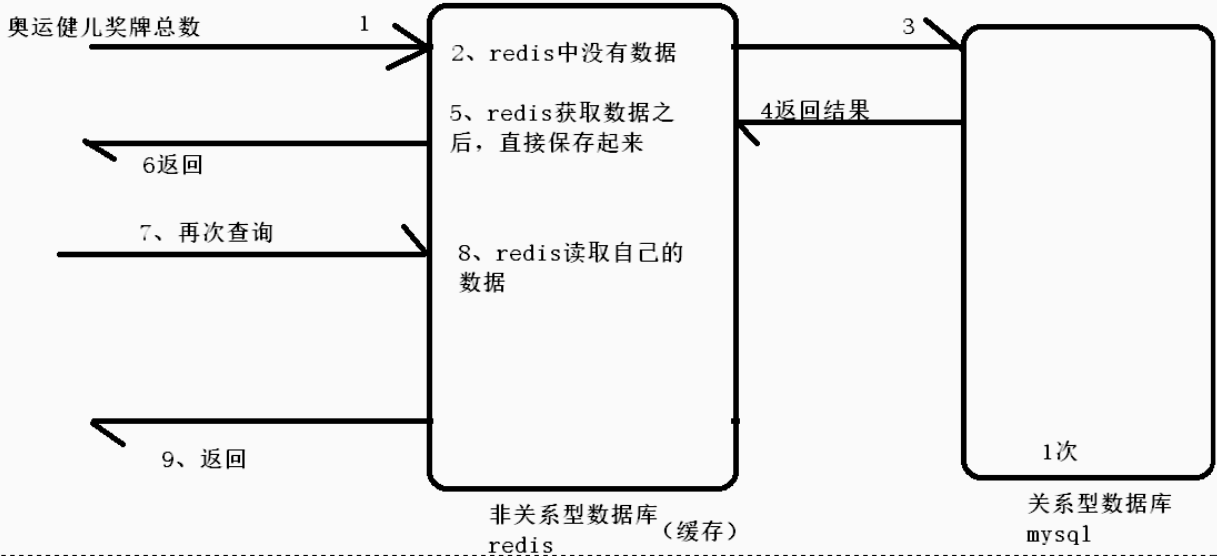
比如运动员奖牌数量。
NoSQL数据分类:
-
- 键值(Key-Value)存储数据库
相关产品: Redis、Voldemort、Berkeley DB
典型应用:内容缓存,主要用于处理大量数据的高访问负载
数据模型:一系列键值对
优势:优秀的快速查询,稳定性强
劣势:存储的数据缺少结构化
-
- 列存储数据库:
相关产品:Cassandra,HBase,Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限,使用极大的内存才可调配。
Redis
应用场景:
-
- 关系型数据库的缓存存在
-
- 可以做任务队列

-
- 大量数据运算
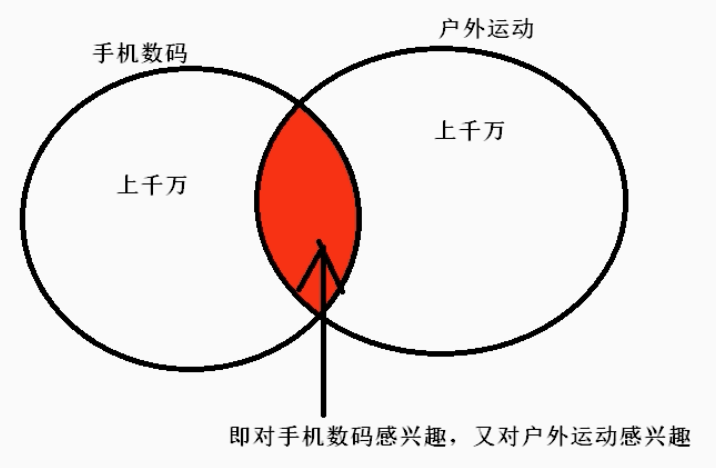
-
- 大量数据的排行榜
Redis String命令:(重点)
关系型数据库频繁编解码缺点:
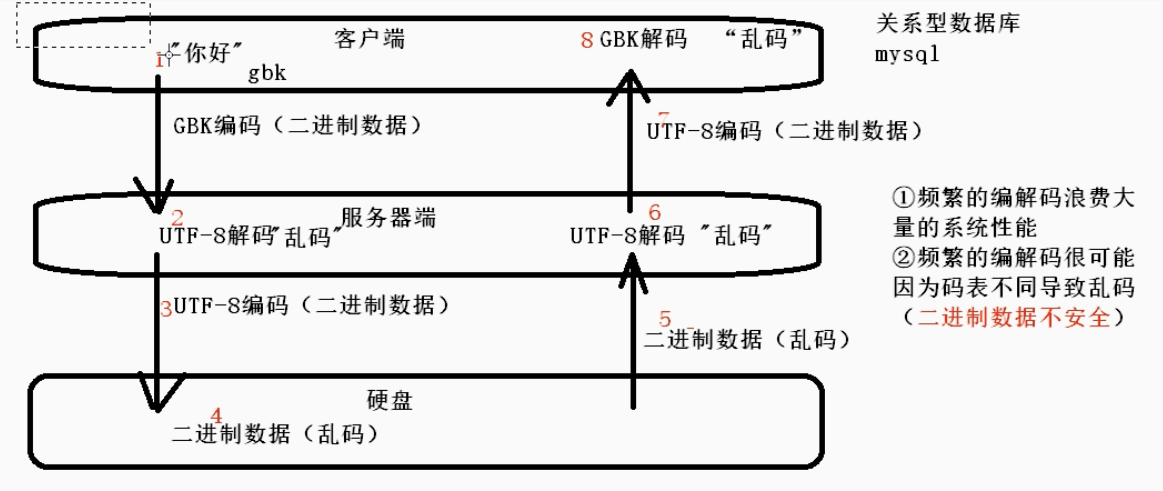
Redis数据库:

赋值命令:
-
-
- set key value:设定key持有指定的字符串value,如果该key存在则进行覆盖操作,会覆盖value值,总是返回“ok”。
-
取值命令:
-
-
- get key:value为空则返回(nil)
-
删除命令:
-
-
- del key:删除指定key,返回Integer
-
扩展:
-
-
- getset key value:先获取该key的值,然后再设置该key的值。
- incr key:将指定的key的value原子性的递增1.如果该key不存在,其初始值为0,在incr之后其值为1,如果value值不能转换为整型,该操作执行失败,并返回相应的错误信息。
- decr key与上面的正好相反。
- append key value:拼凑字符串,如果该key存在,则在原有的value后追加该值;如果该key不存在,则重新创建一个key/value
- incr/decrby key value:增减固定数
-
String使用环境:
主要用于保存json格式的字符串,几乎所有数据都可以这样保存。
Redis hash命令:(了解)
-
-
- Redis中的Hash类型可以看成具有String Key和String Value的map容器。所以该类型非常适合于存储值对象的信息。如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘空间。每一个Hash可以存储4294967295个键值对。
-
Hash -> {username:"张三" , age:"18", sex:"man"} ---- javaBean
Hash特点:占用的磁盘空间极少
命令:flushdb数据库中所有数据被删掉
hset key filed value:为指定的key设定filed/value对
hmset key filed value[filed2 value2 ...]:设置key中的多个filed/value
取值:
-
- hget key field
- hmget key fields:获取多个字段的值
- hgetall key:获取key中所有字段的值
删除:del key:删除整个hash
hdel key field 删除指定key的字段
增加数字:
hincrby key field increment:设置key中filed的值增加increment
hlen key:获取key所包含的所有字段
hkeys key:获得所有的字段
hvals key:获取所有的value