逻辑回归
基本流程
模型开发阶段:数据处理 ——变量筛选和压缩——logit图——模型开发
模型验证:数据处理——误分类矩阵——ROC图——模型比较——模型确认
模型测试:收益矩阵——打分——决策
模型实施:
数据采样:
1、总体已知,反应数据过少,保留所有反应数据,使得反应数据在采样后的数据集占有一定的比例
2、总体未知,知道反应的先验概率 注意对采样数据的概率调整
重点看是否有缺失
data develop; set lg.develop; 将数据目录转移到work下 run;
proc contents data=develop; 展示所有变量名称
run;
%let inputs=ACCTAGE DDA DDABAL DEP DEPAMT CASHBK
CHECKS DIRDEP NSF NSFAMT PHONE TELLER
SAV SAVBAL ATM ATMAMT POS POSAMT CD
CDBAL IRA IRABAL LOC LOCBAL INV
INVBAL ILS ILSBAL MM MMBAL MMCRED MTG
MTGBAL CC CCBAL CCPURC SDB INCOME
HMOWN LORES HMVAL AGE CRSCORE MOVED
INAREA;
%put &inputs;
proc means data = develop n nmiss mean min max; 看变量信息 缺失值个数
var &inputs; 连续变量的处理
run;
分类变量的处理
proc freq data = develop;
tables ins branch res;
run;
数据填缺
在数据填缺后,保留原有变量和缺失向量进入模型

proc print data=develop(obs=30); var ccbal ccpurc income hmown; run; /*创建缺失变量指示器*/ data develop1(drop=i); set develop; /* name the missing indicator variables */ array mi{*} MIAcctAg MIPhone MIPOS MIPOSAmt 缺失变量的 数组 MIInv MIInvBal MICC MICCBal MICCPurc MIIncome MIHMOwn MILORes MIHMVal MIAge MICRScor; /* select variables with missing values */ array x{*} acctage phone pos posamt inv invbal cc ccbal ccpurc income hmown lores hmval age crscore; do i=1 to dim(mi); mi{i}=(x{i}=.);循环如果为空 赋值为1 end; run; /*输入缺失值*/ proc stdize data=develop1 reponly method=median 中位数填缺 out=imputed; var &inputs; run; proc print data=imputed(obs=12); var ccbal miccbal ccpurc miccpurc income miincome hmown mihmown; run;
属性变量压缩
1、变成哑变量:变量水平较少时使用
2、变成连续变量:WOE (银行信用卡)
3、压缩属性值:卡方统计量
WOE:表示某一变量(通常已经离散化)中某一属性的预测力,WOE在变量属性中的变动趋势形成变量的
预测力。变量的预测力用IV(information value)度量;
假设目标变量只有“好”和“坏”两种,则: WOE = LN(好的分布/坏的分布)
其中 好的分布 =好的个数/总好的个数 = pi/p
坏的分布 = 坏的个数/总坏的个数 = (1-pi)/(1-p)

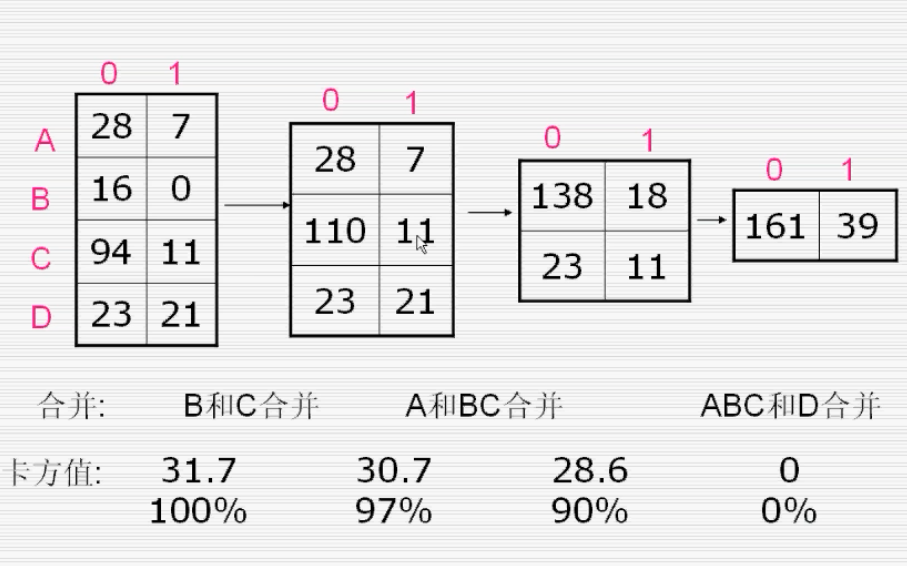
如何压缩
求各分行对响应变量的响应概率
proc means data = imputed noprint nway; class branch; var ins; output out = level mean=prop; run;
proc print data=level;
run; 打印出来
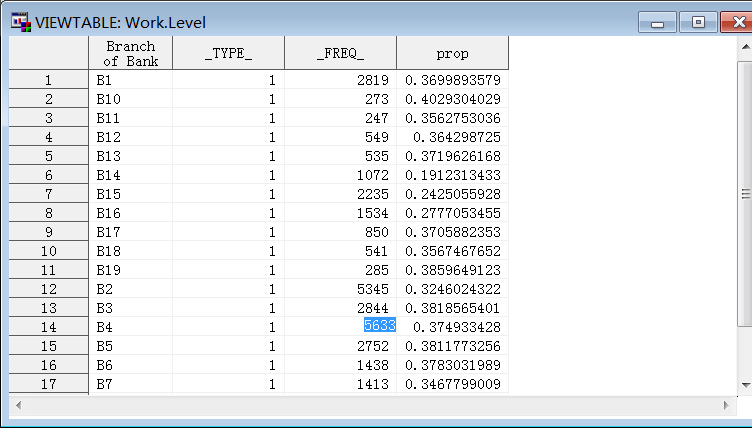
响应概率相近的归为一类
聚类分析
proc cluster data=level method=ward outtree = fortree; freq _freq_; 加上频数权重 var prop; 对prop进行聚类 id branch; run;
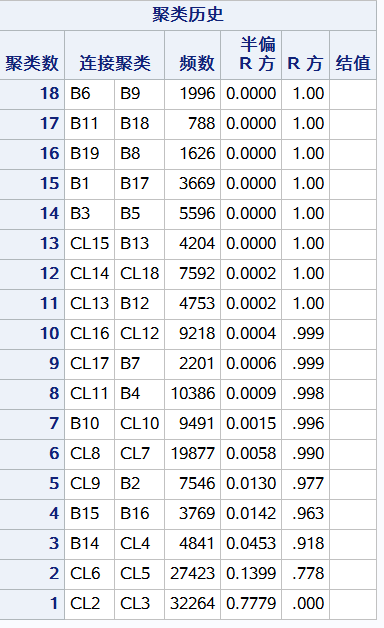
需要把rsquare作为惩罚项加进来
计算branch和ins总的卡方值
proc freq data = imputed noprint; table branch*ins /chisq; 预测变量 *响应变量y output out=chi(keep=_pchi_) chisq; run;
把rsquare作为惩罚项加进来 计算最好的分类
data cutoff; if _n_ = 1 then set chi; set cluster; chisquare=_pchi_*rsquared; 总的卡方*rsquared degfree=numberofclusters-1; logpvalue=logsdf('CHISQ',chisquare,degfree); 加入了一个自由度的惩罚项 run;

画图来判断 取抛物线最低端
proc plot data=cutoff; plot logpvalue*numberofclusters/vpos=30; run; quit;
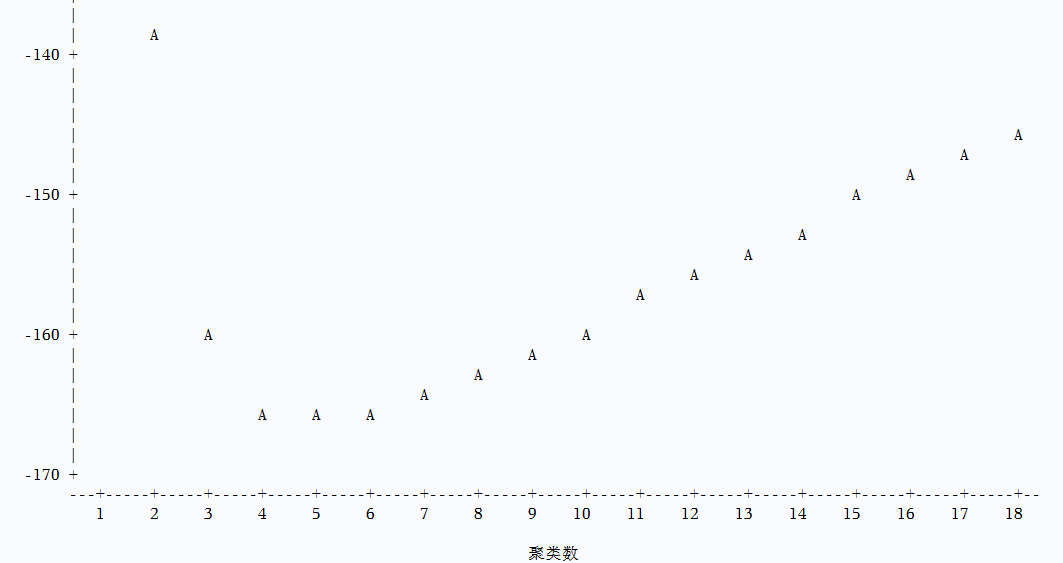
proc cluster和proc tree一般同时使用
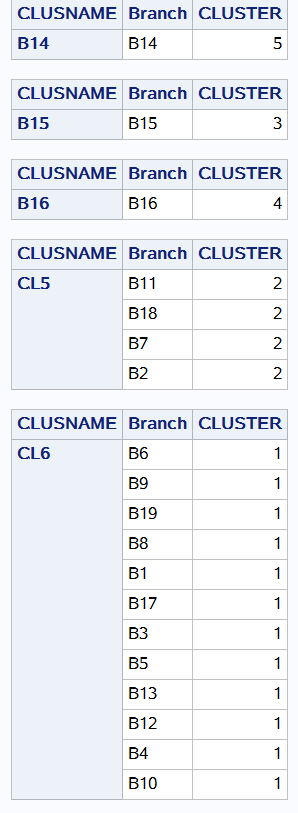
proc tree data=fortree h=rsq nclusters=&ncl out=clus; id branch; run;