摘要:
- F查询
- Q查询
- 事务
一、F查询
- 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个我们自己设定的常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
示例:
建表:from django.db import models class Goods(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=8, decimal_places=2) remain = models.BigIntegerField() sold_out = models.BigIntegerField()
插入模块
from django.db.models import F,Q
例子:查询卖出数量大于库存数的商品名称
res = models.Goods.objects.filter(sold_out__gt=F('remain')).values_list('name', 'sold_out', 'remain') print(res) # <QuerySet [('袜子', 600, 100), ('夹克', 20, 10)]>
F可以帮我们取到表中某个字段对应的值来当作我的筛选条件,而不是我认为自定义常量的条件了,实现了动态比较的效果
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。基于此可以对表中的数值类型进行数学运算
例子:将每个商品的价格提高50块res1 = models.Goods.objects.update(price=F('price')+100)
引申:如何修改char字段,比如将上面的表中商品名称全部尾部加上‘清仓’两个字,如何操作?
这里需要使用2个模块:Concat 和 Valuefrom django.db.models.functions import Concat from django.db.models import Value res = models.Goods.objects.update(name=Concat(F('name'), Value('清仓')))
Concat表示进行字符串的拼接操作,参数位置决定了拼接是在头部拼接还是尾部拼接,Value里面是要新增的拼接值
二、 Q查询
- filter()方法汇总的逗号get的条件是与的关系,如果要执行更复杂的查询,比如or的语句,就会用到Q对象
例子:
查询卖出数量大于100或者价格小于300的商品名from django.db.models import F,Q res = models.Goods.objects.filter(Q(sold_out__gt=100)|Q(price__lt=300)).values_list('name', 'sold_out', 'price') print(res) <QuerySet [('袜子清仓', 600, Decimal('129.90')), ('寸衫清仓', 10, Decimal('229.90'))]>
对条件包裹一层Q时候,filter即可支持交叉并的比较符
# 查询库存数是小于等于20,且卖出数不是10的产品 res = models.Goods.objects.filter(Q(remain__lte=20)&~Q(sold_out=12)).values_list('name')
我们可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。
同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。
# 查询产品名包含新款或者爆款,且库存大于60的产品 res = models.Goods.objects.filter(Q(name__contains='新款')|Q(name__contains='爆款'), remain__gt=60).values_list('name')
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面
- 重点使用方法补充:
实例化Q对象:q = Q() q.connector = 'or' # 默认q之间的条件都是与关系,这里改成or关系 q.children.append(('name','sgt')) # 插入第一个条件,注意这里传的是一个元祖 q.children.append(('password','123')) # 可以继续插入条件 # q对象支持直接放入filter括号内,它们之间默认是and关系,可以通过上面的q.connect = 'or'来修改成或关系 models.User.objects.filter(q) # 这里面就是查询的条件们,它们之间默认是与关系,可以修改成or关系
三、事务
- 定义:将多个sql语句操作变成原子性操作,要么同时成功,有一个失败在里面就回滚到原来的状态,保证数据的完整性和一致性(NoSQL数据库对事务则是部分支持)
# 事务 # 购买商品 # 产品表中修改数据:卖出数+1,库存-1 from django.db.models import F from django.db import transaction try : with transaction.atomic(): models.Goods.objects.filter(id=1).update(remain=F('remain')-1, sold_out=F('sold_out')+1) except Exception as e: print(e)
四、补充的一些常用的操作
-
update()与save()的区别
两者都是对数据的修改保存操作,但是save()函数是将数据列的全部数据项全部重新写一遍,而update()则是针对修改的项进行针对的更新效率高耗时少
所以以后对数据的修改保存用update()
- 让我们通过orm对数据库操作时候,让终端显示内部查询操作sql语句:
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上
补充:
除了配置外,还可以通过一点query即可查看查询语句,具体操作如下: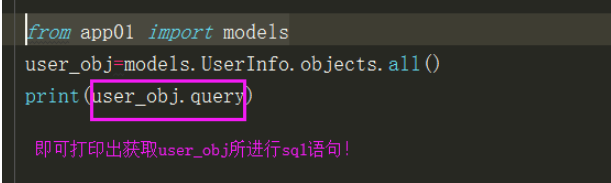
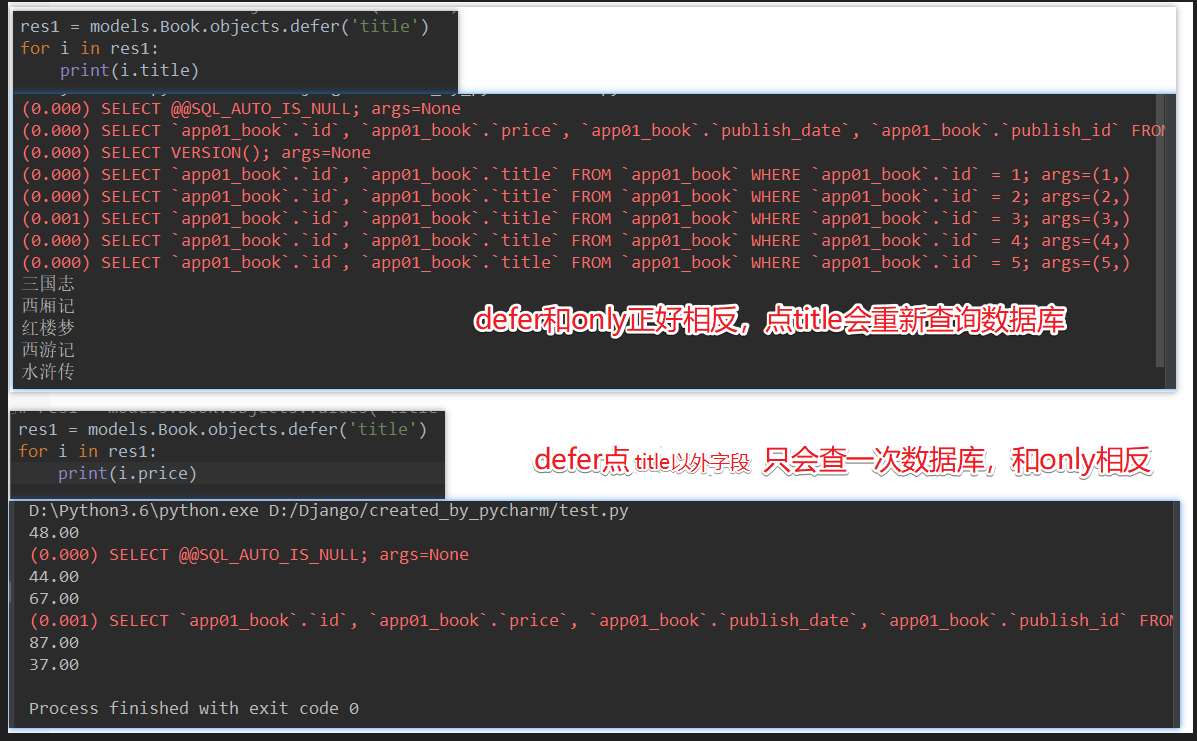
- only 与 defer
拿到的是一个对象 两者是相反的
(前提设置:设置每次操作数据库时候都会有sql语句现实在pycharm终端,上面已说明步骤)
先看看only: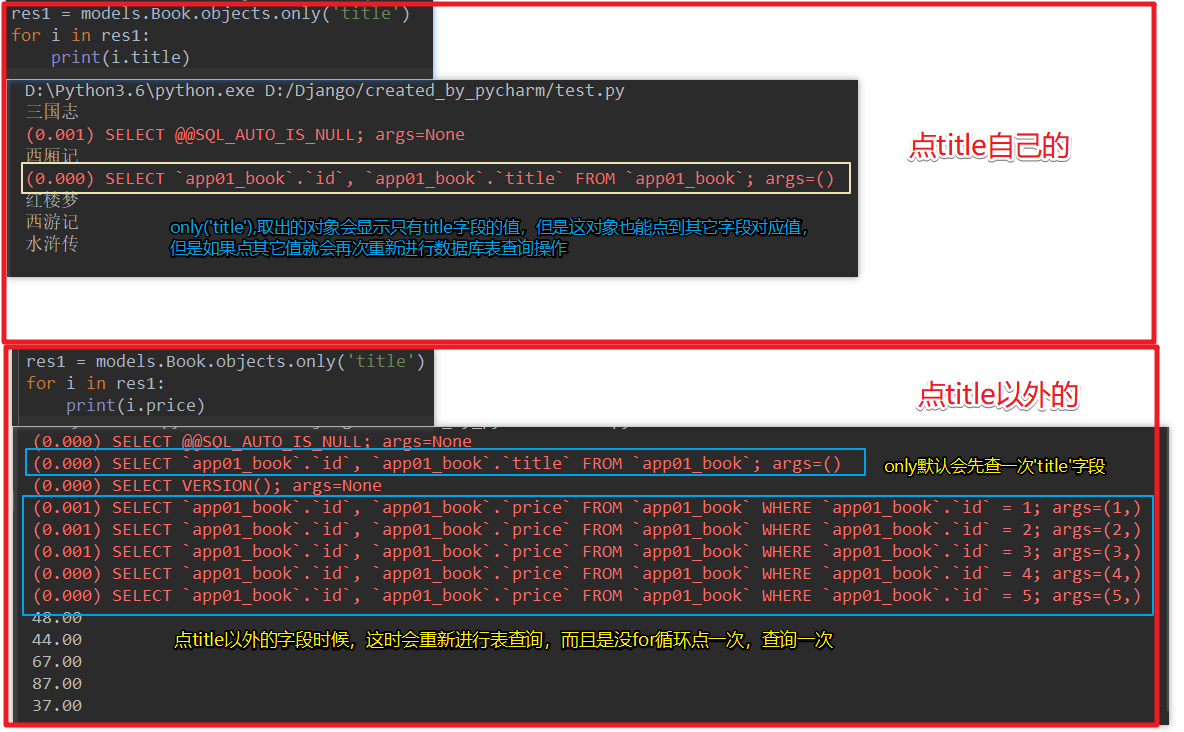
看看defer
- choice属性
choice这个属性,用来限制用户做出选择的范围。比如说性别的选择(男或女)
class MyUser(models.Model): name = models.CharField(max_length=32) password = models.CharField(max_length=32) choices = ((1, '男'), (2, '女'), (3, '其它')) gender = models.CharField(choices=choices, default=1, max_length=5)
choice接收一个元组(保证值不可变),同理每一个选项也是由一个元组(value,display_name)构成。显而易见,display_name就是要在页面中展示的。
如何取到value和displayname?
比如说实例一个User对象user_obj,
user_obj.gender = value (通过属性取value)
user_obj.get_gender_display() = display_name (通过 get_属性_display()方法取display_name)
在模板中可以通过模板语言{{ user_obj.gender }}很简单地显示value,但不能直接调用get属性_display方法(模板毕竟是模板语言),要解决这个问题,可以用自定义过滤器来搞定:
来回顾一下如何自定义过滤器:
1,在应用名下新建一个名为templatetags文件夹
2,在该文件夹内新建一个py文件,名字随意
3,在该py文件内添加固定代码和自定义过滤器代码from django import template register = template.Library() @register.filter(name='displayName') def displayName(obj): res = obj.get_gender_display return res() # 视图层: from django.shortcuts import render, HttpResponse,reverse # Create your views here. from app01 import models def index(request): obj = models.MyUser.objects.filter(pk=1).first() return render(request, 'index.html', locals()) # 前端(html页面): {% load my_file %} {{ obj|displayName}}
- bulk_create批量插入数据
当我们使用orm来一次性新增很多表记录的时候,等待结果的时间会非常的慢,如果一次性需要批量插入很多数据的时候就需要使用bulk_create来批量插入数据
import random user_list = ['用户[{}]'.format(i) for i in range(100)] data = [] for j in user_list: data.append(models.MyUser(name=j, password='123', gender=str(random.choice([1, 2, 3])))) models.MyUser.objects.bulk_create(data)
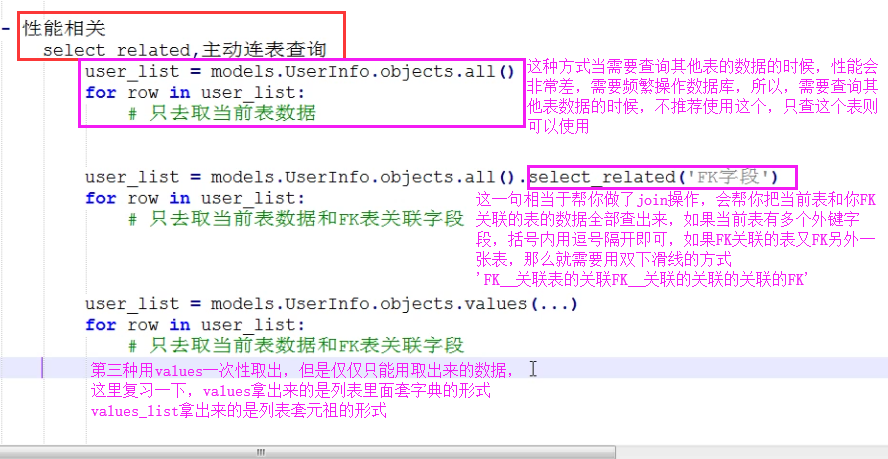
- select_related和prefetch_related
def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结: 1. select_related主要针一对一和多对一关系进行优化。 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结: 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。