一、博弈论与进化
- 策略式博弈模型组成部分
- 博弈人
- 策略空间:行动
- 支付函数:收益
- 进化博弈论和传统博弈论的区别:进化博弈论把博弈人行为演化过程看作一个时间演化系统, 重点研究博弈人行为的调整过程.
传统博弈论是以博弈人行动所传递的信息为依据, 重点研究博弈人在预期信息下的决策结果。
个人理解:进化博弈论研究的是人怎么去选择策略,调整策略的过程,而传统博弈研究的是人选择策略后,在预期的条件下会获得的结果。
二、强化学习
- 强化学习结构:

- Q-learning:

个人理解:Q值得更新取决于旧的Q值以及在当前状态下,选择某一行动获得的奖励和最大的Q(s,t)值,γ值表示折扣因子,γ越小,说明
系统只考虑即时奖励,比较短视,γ越大,说明系统同时考虑了未来的奖励。
三、模型设计
根据代理人的不同可以将强化学习分为单代理人强化学习和多代理人强化学习。单代理人强化学习把其他代理人当作环境的一部分。
- 模型思想
将博弈过程中博弈人所处的状态看成是两人的历史行动组合。两个博弈人独立选择自己的行动,并分别得到一个顺势回报r1 r2,若
r1+r2=0,则为零和博弈。两人确定动作a1 a2后确定了一个新的行动组合,转移到新状态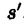 ,转移概率记为
,转移概率记为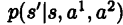 。
。 - 转移概率的确定

在进化博弈中,状态的不断改变会使得博弈人的策略不断更新。λ刻画的是代理人决策的随机性,λ越大,随机性越大。
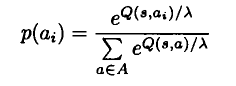

- 策略迭代算法
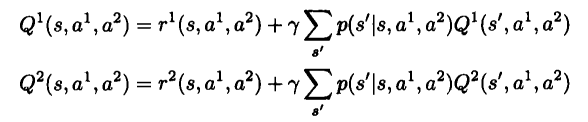
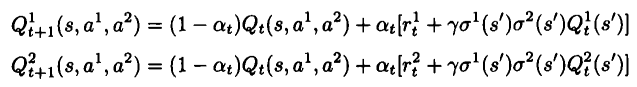

两人进化博弈中强化学习模型 的策略迭代算法流程为:

理解:令初始Q值为0,随机生成一个状态s,由t时刻的双博弈矩阵计算出Nash解,通过解1可以观察到瞬时报酬r1r2,以及对手的行动a2,还有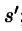 。
。
然后计算出t+1时刻的双博弈矩阵的Nash解,并更新Q1 Q2.令t=t+1,直到搜索完为止。
五、仿真实验
- 背景:一次的囚徒困境中,对于个体而言,背叛是纳什均衡解,但是同时选择合作总体收益却是更高。重复多次的囚徒困境
可以给博弈双方建立信任的机会,从而可能可以破解不合作的困境。 - 博弈过程中的转移概率及瞬时回报

图中给出了博弈一方在各个状态下根据不同策略的状态转移概率的不同,如状态<C,C>,在选择决策C时,转移到状态S1的概率是0.375,
转移到状态S2的概率是0.625,瞬时报酬为3。 - 多种模式下的Q值迭代
取γ值为0.7,分别使用单代理人模式和多代理人模式进行重复博弈。
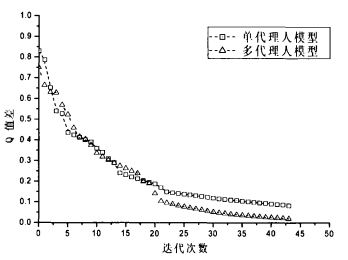
如图所示,Q值误差随着迭代逐渐收敛为0,经过比较,多代理人学习模型比单代理人学习模型具有更快的收敛速度。

如表所示,随机决策的效率最低,表明单代理人强化学习模型和多代理人强化学习模型是有效的。多代理人决策模型选择策略C
的次数和联合得益都是最高的, 由此可见: 多代理人决策模型更能有效的实现合作的Pareto最优均衡。