多智能体博弈强化学习研究综述笔记2
标准博弈
- 共同利益博弈: 常见的有团队博弈、势博弈和 Dec-POMDP
- 团队博弈:对于构建分布式 AI (DAI)至关重要。
- 存在的问题:若博弈存在多个纳什均衡,即使每个智能体之间的学习目标幵不冲突,也会导致智能体最终不会学到最优策略的问题。
- Sandholm:利用有偏好的动作选择和不完整的历史采样提出了最优自适应学习算法(optimal adaptive learning,OAL) ,并证明该方法对于存在多个纳什均衡
的团队博弈中都会收敛至最优纳什均衡,但是该方法在一般的随机博弈中收敛性并不能得到保证。 - Arslan:提出了随机博弈的去中心化 Q-learning 算法,并借助双时间尺度分析以团队博弈问题为例,证明了算法在大量的随机博弈中都会稳定收敛到最优纳什均衡。
- 获得最优解的关键:是如何解决智能体之间的合作关系。
- Mao:提出 ATT-MADDPG 算法,算法通过一个集中的 ctitic 来收集其它玩家的信息和策略,并在集中 critic 中嵌入注意力机制以自适应的方式对其它玩家的动态
联合策略建模,当玩家的策略发生改变时,相关的注意权重就会自适应的改变,智能体就会快速的调整自己的策略。(收集信息,嵌入注意力机制进行联合策略建模,玩家
策略改变,权重改变,智能体调整自身策略) - Liu:利用完全图对智能体的关系迚行建模,提出基于两阶段注意力网络的博弈抽象机制(G2ANet)[9],幵在 Traffic Junction 和 Predator-Prey 场景下证明
该方法可以简化学习过程。 - Zhu:为解决智能体之间通信问题,提出Partaker-Sharer 框架,通过在每个时间步彼此共享智能体的最大 Q 值来加速学习过程,幵在 Predator-Prey场景下验证了
算法的有效性。 - Yang:借用了平均场论(Mean Field Theory,MFT)的思想,其对多智能体系统给出了一个近似假设:对某个智能体,其他所有智能体对其产生的作用可以用一个均值
替代,提出了平均场多智能体强化学习算法(Mean Field),将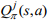 转化为只包含相邻智能体相互作用的形式:
转化为只包含相邻智能体相互作用的形式:

其中N(j) 表示智能体 j 邻居智能体的标签集, 表示邻居节点的个数。(对于一个智能体,用一个均值来代替其他智能体对它产生的作用)
表示邻居节点的个数。(对于一个智能体,用一个均值来代替其他智能体对它产生的作用) - Anahtarci:对智能体之间的交互作用进行近似,降低智能体交互的复杂度,并且在理论上给出了收敛性证明,能够收敛到纳什均衡点。
- Elie:针对智能体的数量接近无限的情况,在仅依赖平均场博弈的基本动力学假设的条件下,根据每个学习迭代步骤中出现的累积误差来量化近似纳什均衡的质量,首次
展示了无模型学习算法向非平稳MFG均衡的收敛。(量化近似纳什均衡的质量) - Vlassis:将多智能体系统视为一个大型马尔可夫决策过程(MDP),基于动态贝叶斯网络和协调图(coordination graphs)使用因式分解将线性值函数作为联合值函数
的近似值,值函数的这种分解允许智能体在行动时协调其动作,有效解决状态和动作空间中的指数爆炸问题,最终可以找到全局最优联合动作。(线性值函数代替联合值函数) - 让智能体从任务中自动学习值函数分解的经典算法:VDN、QMIX、QTRAN、Qatten 和 QPD 等。
- VDN:在值函数可分解的假设下要求联合值函数是每个智能体值函数的线性和,即:
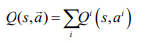 。
。 - QMIX:QMIX 利用集中式训练的优势,使用全局状态进行训练但 QMIX 为了保证独立全局最大化操作,假设联合值函数对个体值函数是单调的,用公式来表示为:
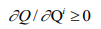 。 (联合值函数对于个体值函数单调。)
。 (联合值函数对于个体值函数单调。) - QTRAN: 算法结合了上述 VDN 和 QMIX 的优点,认为直接用神经网络去逼近联合 Q 函数相对困难,因而将整个逼近过程分为两步:首先采用 VDN 的方式得到加和的联合
值函数,作为联合值函数的近似,接着去拟合加和的联合值函数与联合值函数的差值。 - Qatten:在不引入附加假设和约束条件的情冴下,首次从理论上推导出任意数量的智能体的联合值函数和各智能体的值函数的广义形式,提出基于多头注意力机制的值函
数混合网络来近似联合值函数和分解单个值函数。 - QPD:另外一种值函数的分解方法,使用积分梯度的方法,沿轨迹路径直接分解联合值函数,为智能体分配信度。
- VDN:在值函数可分解的假设下要求联合值函数是每个智能体值函数的线性和,即:
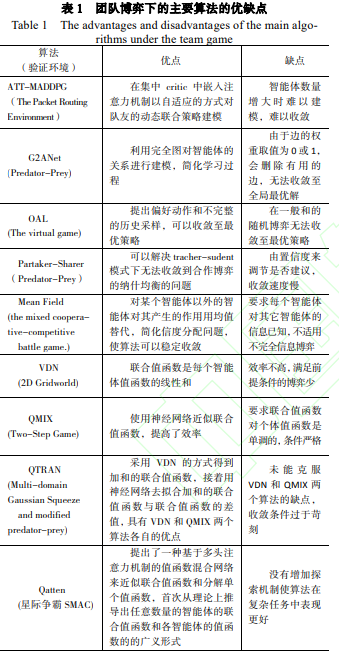
- 团队博弈下的主要算法优缺点如表 1 所示。
- 随机势博弈
- 势函数的定义:博弈中,如果每个玩家对于自身目标改变或策略选取,都可以映射到某个全局函数中去,这个函数就叫做势函数(potential function),这个博弈称为势博弈
(potential game)。势博弈可以被看作多智能体博弈的“单智能体成分”,因为所有智能体在SPG 中的利益都被描述为一个单一的势函数。 - Mazumdar:针对势博弈提出了基于策略的动态更新算法,并应用在 Morse-Smale 游戏中,证明了该算法可以收敛到局部纳什均衡。在复杂的多智能体系统中,有效的学习需要
所有参与的智能体之间高度协调,但是智能体之间的协调和通信彽彽是低效的。 - Gang:提出了集中训练和探索,并通过 policy distillation 来分散执行来促进智能体之间的协调和有效的学习。
- Dec-POMDP
- 标准的 MDP和oMDP的区别:在标准的 MDP 中,智能体的学习目标是最优状态动作值函数,而 oMDP 中的智能体的学习目标是占用状态和联合行动的最优值函数,这些最优值函数
往往都是分段线性的,最重要的是这些限制会使得智能体最终会收敛至全局最优而不是局部最优。 - 存在的问题:在多智能体强化学习的研究很少考虑训练后的策略对新仸务的迁移能力,这使得训练好的策略很难应用至更复杂的多智能体任务。
- 解决办法:Ryu 提出基于多层图注意网络和多智能体 AC 算法的模型,并证明了所提出的模型在多个混合协同和竞争任务下的性能优于现有方法。蒙特卡罗策略迭代法
,以及一种通过维护智能体之间的共享内存来分散POMDP 的方法[。
- 不同利益博弈: 指玩家的学习目标不同,根据所有玩家收益之和是否为零分为有限零和、一般和博弈。
- 有限零和博弈
- 定义:有限零和博弈是指参与博弈的玩家个数有限,并且是严栺的竞争关系,所有玩家的总体收益和支出的总和为零。
- Adler:证明了两人零和博弈和线性优化的等价性,即两人零和博弈可以构建为一个线性优化问题,任意一个线性优化问题也可以简化为一个零和博弈问题。
- 方法:在解决两人零和博弈问题中最典型的方法是最小最大值定理(The Minimax Theorem),其可以表示为如下公式:

然而,该定理幵不适用于回报函数为非凸非凹的博弈。 - 离散动作空间下的零和博弈:
- Shapley:y 给出了第一个值迭代的斱法[30],证明了
 在两人零和博弈中是压缩映射,且可以收敛至纳什均衡。
在两人零和博弈中是压缩映射,且可以收敛至纳什均衡。 - Littman:针对两人零和博弈提出了无模型的 Minimax-Q 算法。Minimax-Q 中的 Minimax 指的是使用最小最大值定理构建线性规划来求解每个特定状态的纳什均衡策略,
Q指的是借用 Q-learning 中的 TD方法来迭代状态值函数或动作-状态值函数。 - Goodfellow在 2014 年提出了生成对抗网络(GANs)利用神经网络使得求解这类问题变为可能[34],在 GANs 中,两个神经网络参数化模型(生成器 G 和鉴别器 D)进行零
和博弈。生成器接收随机变量并生成“假”样本,鉴别器则用于判断输入的样本是真实的还是虚假的。两者通过相互对抗来获得彼此性能的提升。 - Li提出 M3DDPG 算法,核心是在训练过程中使得每个智能体都表现良好,即使对手以最坏的方式反应。
- Shapley:y 给出了第一个值迭代的斱法[30],证明了
- 有限零和博弈下主要算法的优缺点

- 有限一般和博弈 :解决一般和的随机博弈问题的难度比零和的随机博弈要困难很多。
- 解决一般和随机博弈的基于值的算法:这些斱法大多采用经典 Q-learning 作为中心控制器,不同之处在于中心控制器运用何种均衡来引导智能体在迭代中逐渐收敛。
例如,Nash-Q 算法采用的就是纳什均衡,而correlated-Q 算法采用的则是相关均衡(correlated equilibrium)。 - FFQ 算法:将除该智能体以外的所有智能体分为两组,一组称为 friend 的智能体帮助其一起最大化其奖励回报,另一组称为 foe的智能体对抗它幵降低它的奖励回报,这样多智能体
的一般和博弈就转化为了两个智能体的零和博弈。但是此类算法所共有的缺陷是算法的假设条件过于苛刻,运用至现实场景中,收敛性往往无法保证。
- 解决一般和随机博弈的基于值的算法:这些斱法大多采用经典 Q-learning 作为中心控制器,不同之处在于中心控制器运用何种均衡来引导智能体在迭代中逐渐收敛。