1.人工智能
小米:小爱
百度:AI云平台
科大讯飞AI平台
2.百度语音合成
# Author: studybrother sun from aip import AipSpeech #从文本到声音 """ 你的 APPID AK SK """ APP_ID = '你的ID' API_KEY = '你的ID' SECRET_KEY = '你的ID' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('曾经有一份真挚的爱情放在我的面前,我没有珍惜', 'zh', 1, { 'vol': 5, #音量 "spd":4, #语速 "pit":7, #语调 "per":4 #度丫丫的声音 }) print(result) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result)

3.百度语音识别
采样率指的是,每秒监听麦克风的采样频率
# Author: studybrother sun from aip import AipSpeech #从声音到文本 """ 你的 APPID AK SK """ APP_ID = '你的ID' API_KEY = '你的ID' SECRET_KEY = '你的ID' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 res=client.asr(get_file_content('audio.pcm'), 'pcm', 16000, { 'dev_pid': 1536, }) # buffer指的是流,还有上边的client那一行不区分大小写.
win7的录音机是微软的,win10的是第三方的录音机
下面我们打开"录音机",开始录音,录入"床前明月光,1234567"
上图是录制录音的位置
录完上边的两段录音,我们发现文件格式不对,这就需要一种文件的转换格式,进行处理
也就是上图中的ffmpeg工具,进行数据的格式转换.
上图是解压后的三个方式
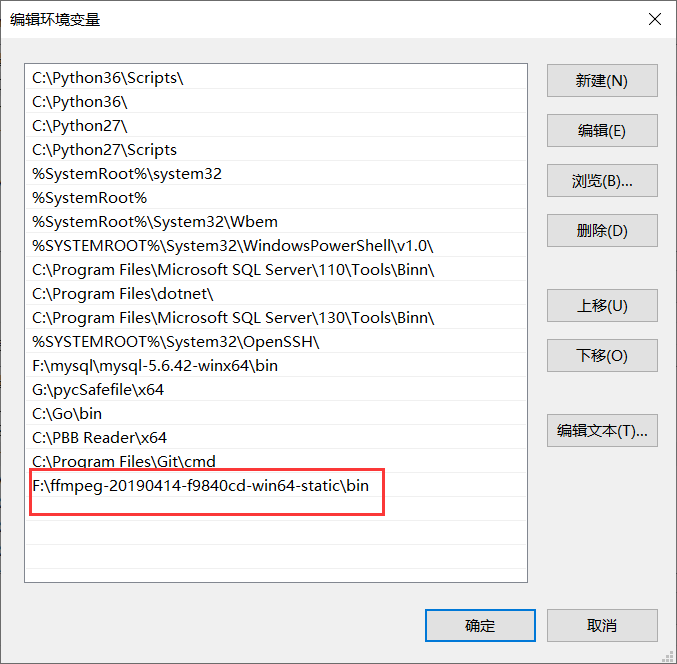
我们只需要将上边的路径,添加到环境变量里边即可
我们将m4a转换成pcm格式,采样率找不到,看一下怎么处理?
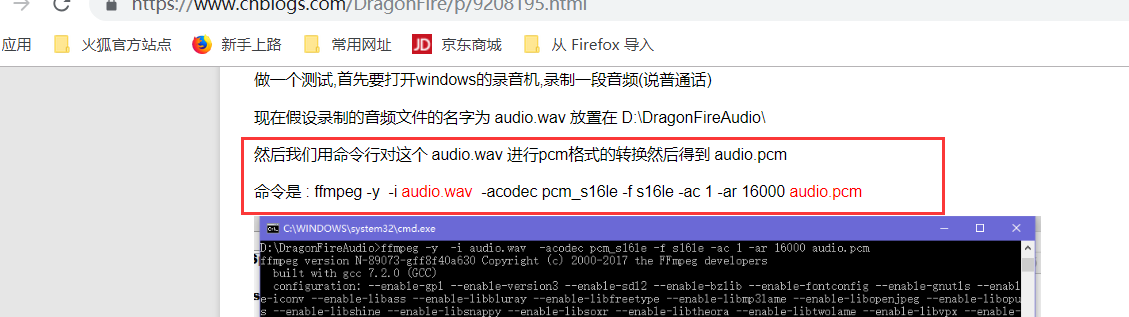
下面是转换的命令:
下图是百度的
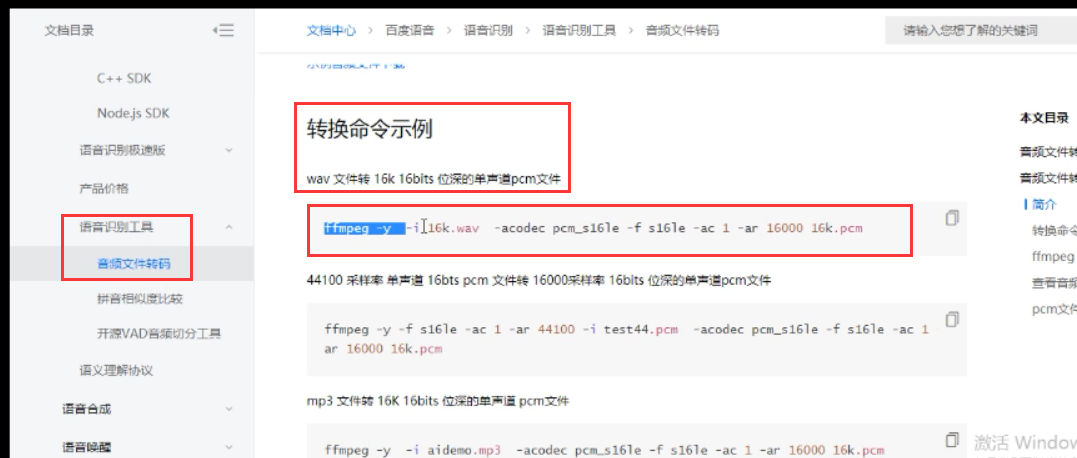
以及下面的拼音相似度比较都有
在powershell可以进行切换目录:
下面我们进行处理:
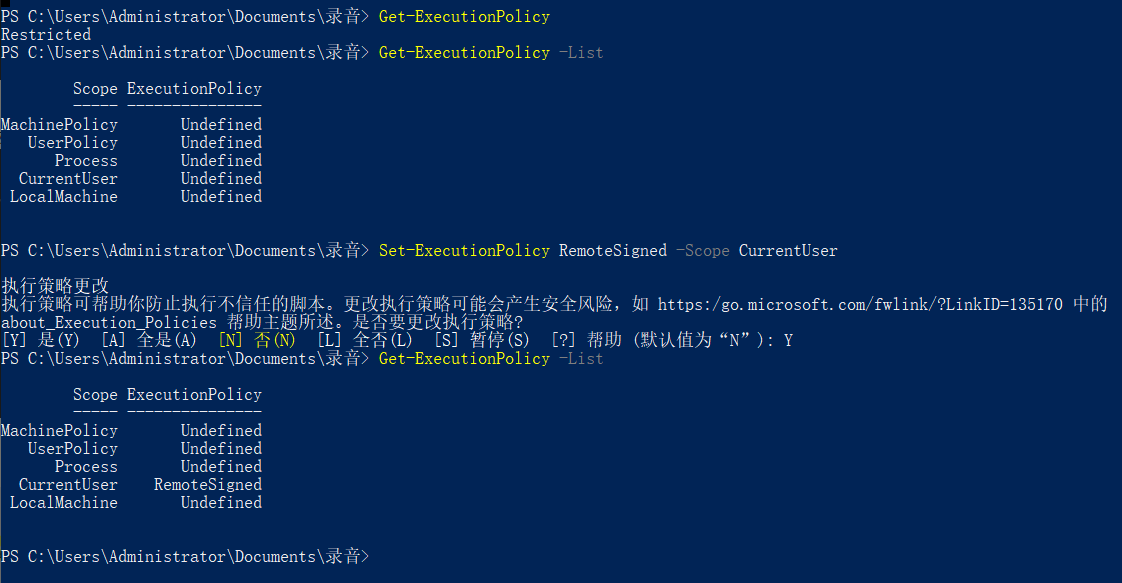
上边依然没有执行成功,下面我们将解压后的ffmpeg放到没有中文的目录下,环境变量也修改下
下边是两条命令:
cd C:UsersAdministratorDocuments录音
ffmpeg -y -i wyn.m4a -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
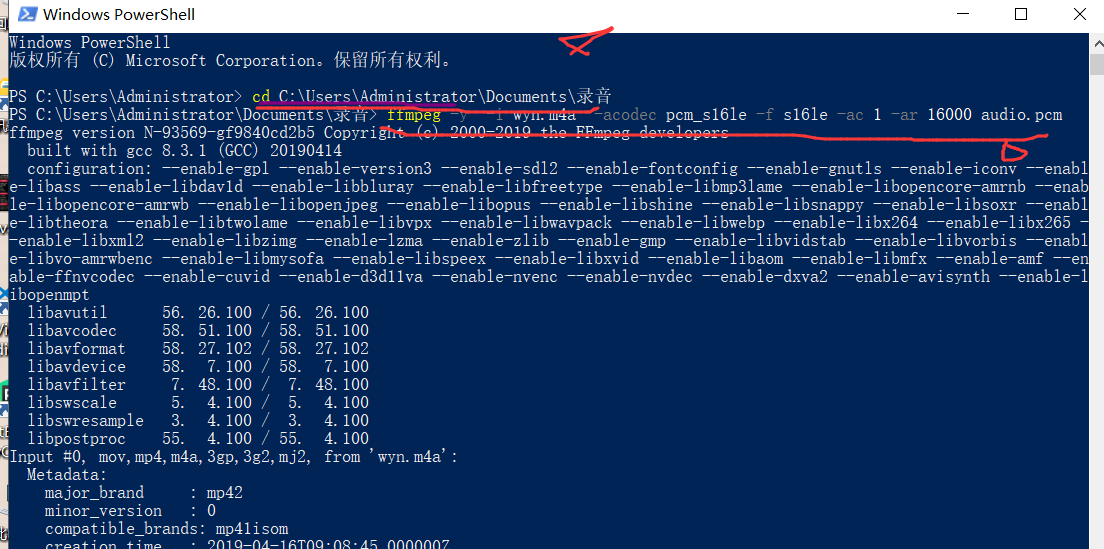
这个时候,可以成功运行了,上边报错的原因可能就是含有中文的原因:

上图中,我们可以看到转换成pcm文件了
这个时候,我们将转换成功的文件audio.pcm放入创建好的项目中

运行之后,报下面错误:

修改下面的打印代码,得到下面的内容:
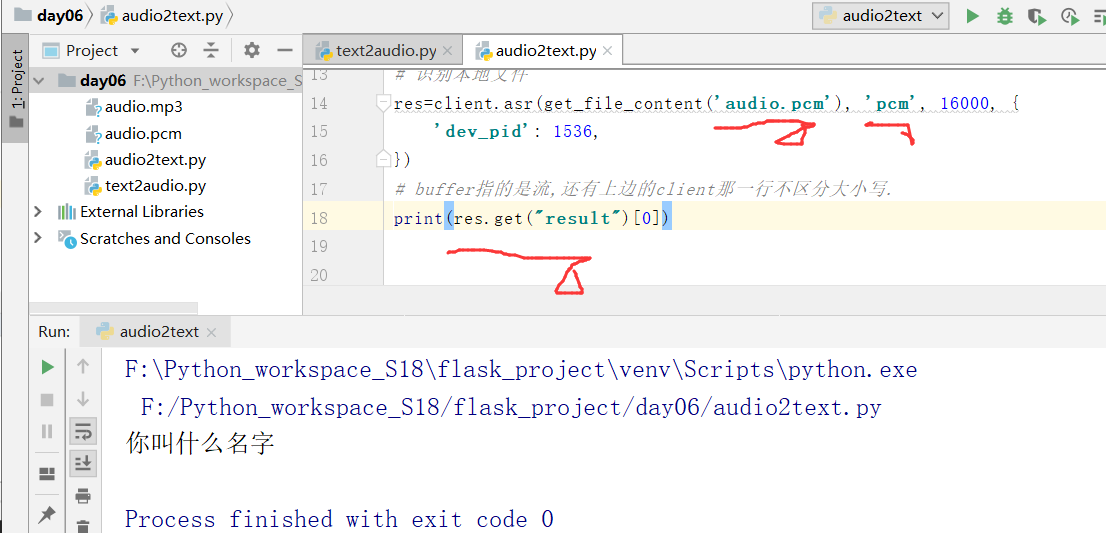
上边是第一种错误,
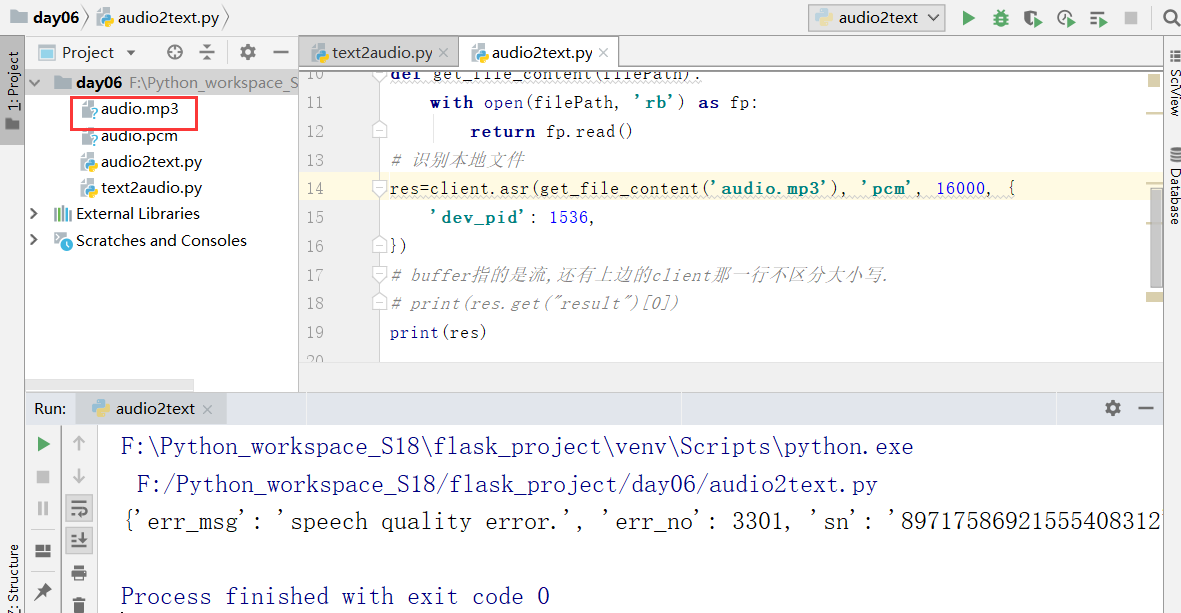
上边的3301错误是"我听不清",音频质量太差,因为是我们用文本合成的语音
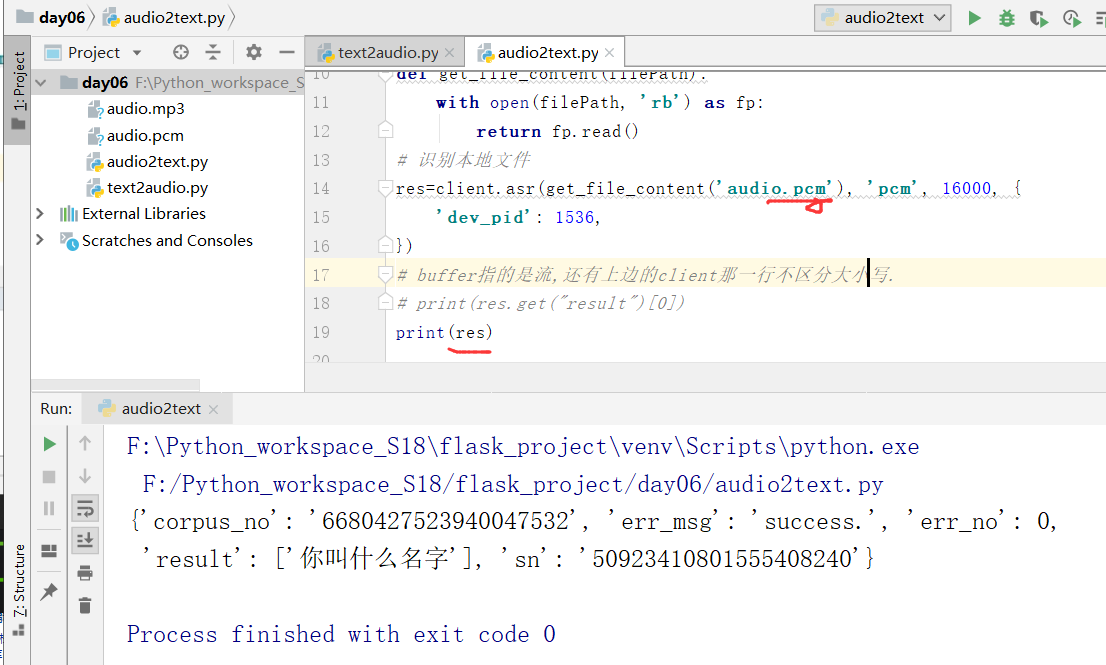
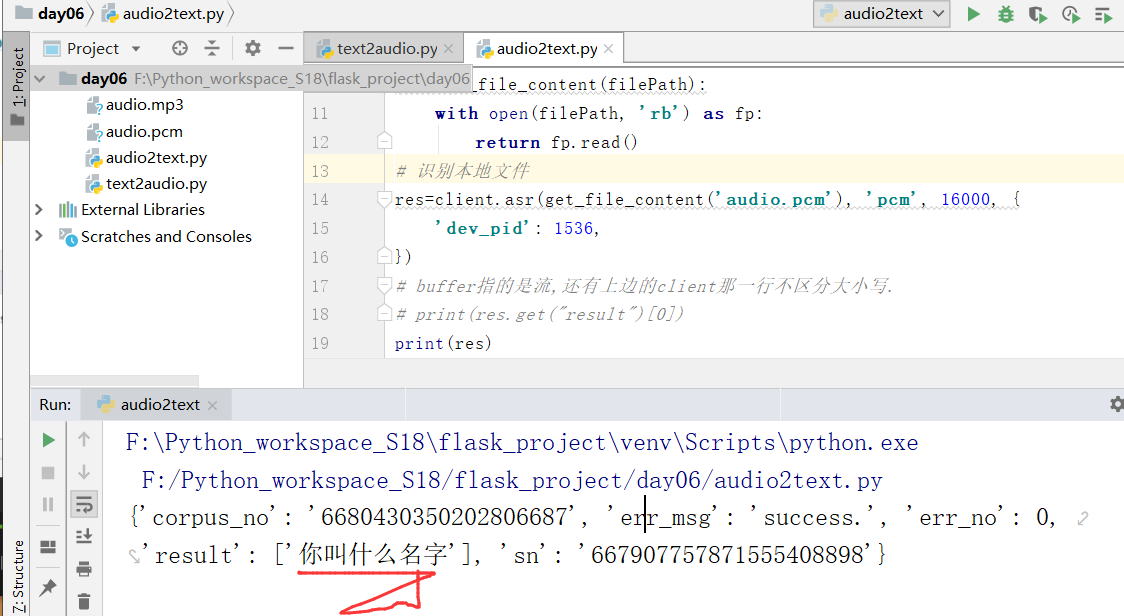
因此,下图中,我们尽量不要用合成的语音进行处理,下面我们使用的文件是audio.pcm

现在,我们的需求是自动进行转换?
下面,我们将两个音频文件都拷贝到文件内:
具体处理方式,见下图:

运行之后,出现上图的错误,错误的原因是,我们配置的环境在pycharm里边还没有生效,我们需要先关上这个pycharm,等一会儿,再次打开,才会生效,

这个时候打开再次打开,我们看到出来结果了,但是还有飘红,是因为看到的ffmpeg里边运行的信息,当然是没有问题了
这个时候,成功出现结果了.
下面是重要的四条内容:

4.百度NLP自然语言处理-simnet短文本相似度
下面写一个常见问题的问答:
最低版本
# Author: studybrother sun import os from aip import AipSpeech #从文本到声音 """ 你的 APPID AK SK """ APP_ID = '16027612' API_KEY = 'B4Pi3KnxI7Gh2xyrafvygQL6' SECRET_KEY = 'tcl4ZkM7Mkla3ygzFXanrgRjHOTXoWvt' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) #上边是语音客户端 #定义一个语音合成: def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 5, # 音量 "spd": 4, # 语速 "pit": 7, # 语调 "per": 4 # 度丫丫的声音 }) print(result) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) return "audio.mp3" #注意,这个地方需要写一个返回文件!!!!!!! def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) # buffer指的是流,还有上边的client那一行不区分大小写. # print(res.get("result")[0]) #注意,出错的位置没有返回,下一行进行处理 return res.get("result")[0] #注意,出错的位置没有返回,这行进行处理!!!!!! # print(res) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() text=audio2text("wyn.m4a") #首先是语音识别 #自然语言处理 LowB 这是最low版的 if text=="你叫什么名字": filename=text2audio("我的名字叫做无极剑圣") os.system(f"ffplay {filename}") #播放方式1 # os.system(filename) #直接,播放方式2
下图中是,需要修改的内容

这个时候,运行,但是报错,并没有报
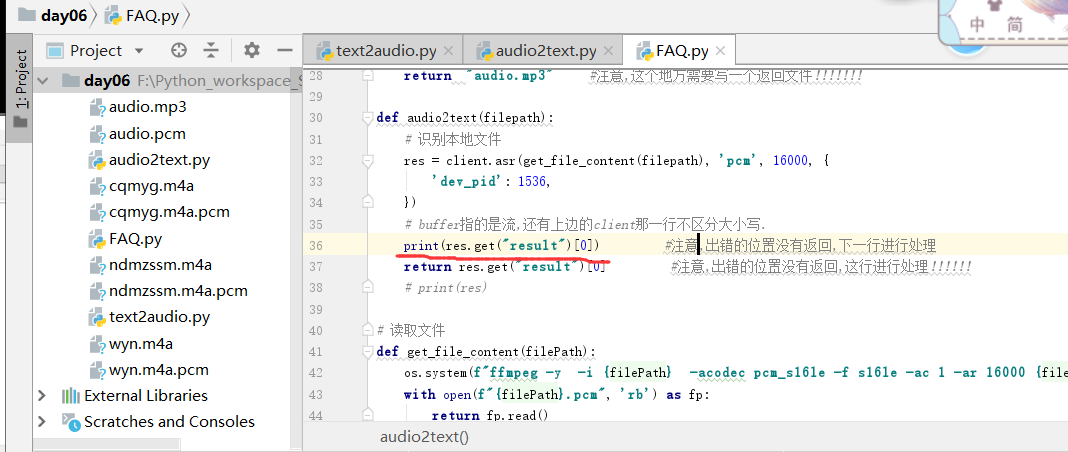
上图是我们打印一下语音文件里边的内容

服务端, 结果显示的内容是见上图
下面,我们需要处理"自然处理基础技术"

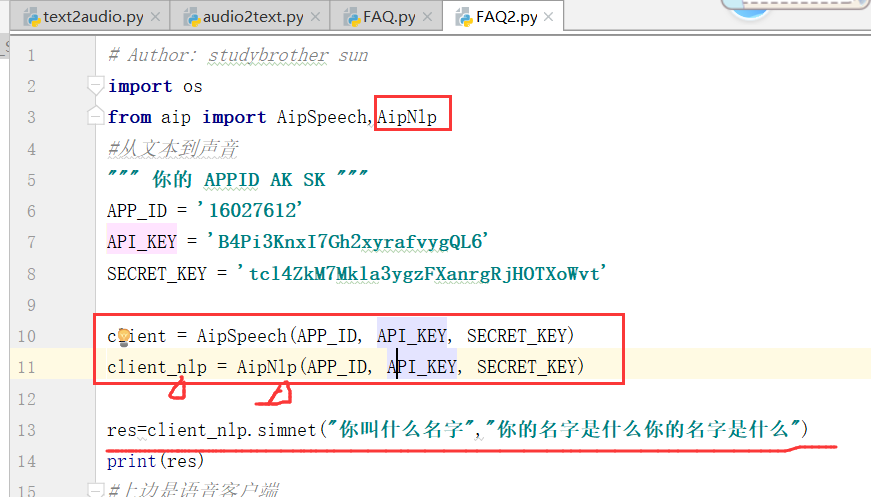
知道"短文本相似度" 58%就意味着相等.

下图指的是,相似度得分

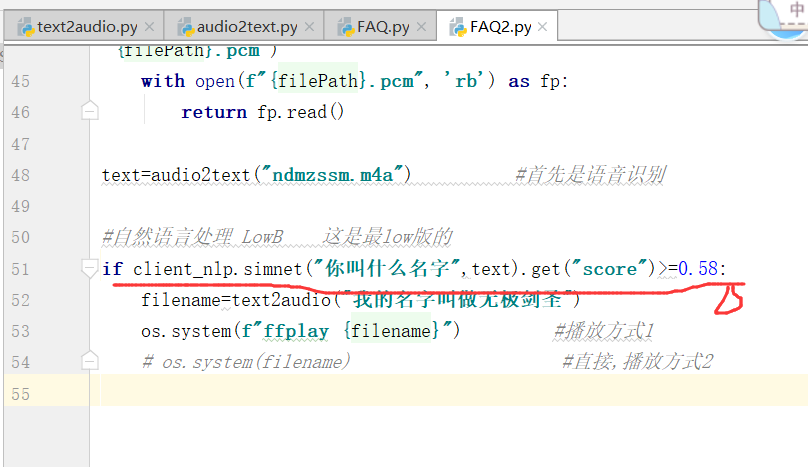
运行的结果,见下图:

现在我们注释,上图中的第13和14行

修改完成之后,再次运行,会播放"我的名字叫做无极剑圣"
具体代码:FAQ2.py
# Author: studybrother sun import os from aip import AipSpeech,AipNlp #从文本到声音 """ 你的 APPID AK SK """ APP_ID = '16027612' API_KEY = 'B4Pi3KnxI7Gh2xyrafvygQL6' SECRET_KEY = 'tcl4ZkM7Mkla3ygzFXanrgRjHOTXoWvt' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) # res=client_nlp.simnet("你叫什么名字","你的名字是什么你的名字是什么") # print(res) #上边是语音客户端 #定义一个语音合成: def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 5, # 音量 "spd": 4, # 语速 "pit": 7, # 语调 "per": 4 # 度丫丫的声音 }) print(result) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) return "audio.mp3" #注意,这个地方需要写一个返回文件!!!!!!! def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) # buffer指的是流,还有上边的client那一行不区分大小写. print(res.get("result")[0]) #注意,出错的位置没有返回,下一行进行处理 return res.get("result")[0] #注意,出错的位置没有返回,这行进行处理!!!!!! # print(res) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() text=audio2text("ndmzssm.m4a") #首先是语音识别 #自然语言处理 LowB 这是最low版的 if client_nlp.simnet("你叫什么名字",text).get("score")>=0.58: filename=text2audio("我的名字叫做无极剑圣") os.system(f"ffplay {filename}") #播放方式1 # os.system(filename) #直接,播放方式2

再次升级:
# Author: studybrother sun import os from aip import AipSpeech,AipNlp #从文本到声音 """ 你的 APPID AK SK """ APP_ID = '16027612' API_KEY = 'B4Pi3KnxI7Gh2xyrafvygQL6' SECRET_KEY = 'tcl4ZkM7Mkla3ygzFXanrgRjHOTXoWvt' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) # res=client_nlp.simnet("你叫什么名字","你的名字是什么你的名字是什么") # print(res) #上边是语音客户端 #定义一个语音合成: def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 5, # 音量 "spd": 4, # 语速 "pit": 7, # 语调 "per": 4 # 度丫丫的声音 }) # print(result) #注释这个,显示的更清晰一些 # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) return "audio.mp3" #注意,这个地方需要写一个返回文件!!!!!!! def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) # buffer指的是流,还有上边的client那一行不区分大小写. print(res.get("result")[0]) #注意,出错的位置没有返回,下一行进行处理 return res.get("result")[0] #注意,出错的位置没有返回,这行进行处理!!!!!! # print(res) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() text=audio2text("zx.m4a") #首先是语音识别 #自然语言处理 LowB 这是最low版的 score=client_nlp.simnet("你叫什么名字",text).get("score") print(score) if score>=0.58: filename=text2audio("我的名字叫做无极剑圣") os.system(f"ffplay {filename}") #播放方式1 # os.system(filename) #直接,播放方式2
提出问题,提出新的问题怎么办?有没有人回答这个问题
5.图灵机器人

注册登录:
首次登录:
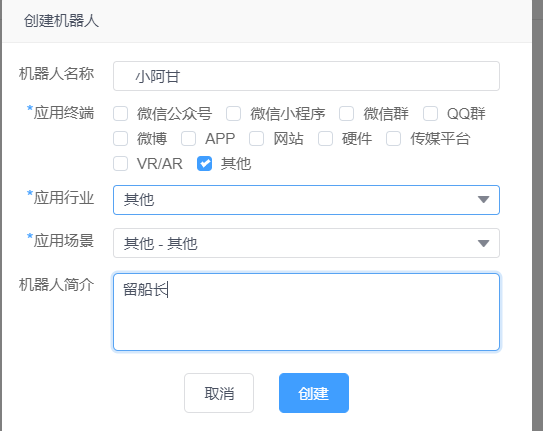
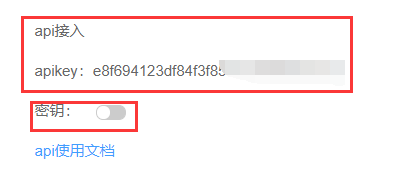
上边的是api接入接口,秘钥很重要,不要轻易打开.
我们先看一下,下面的任务设置:

我们可以看到聊天记录:

我们可以下图中的"API使用文档来进行使用"
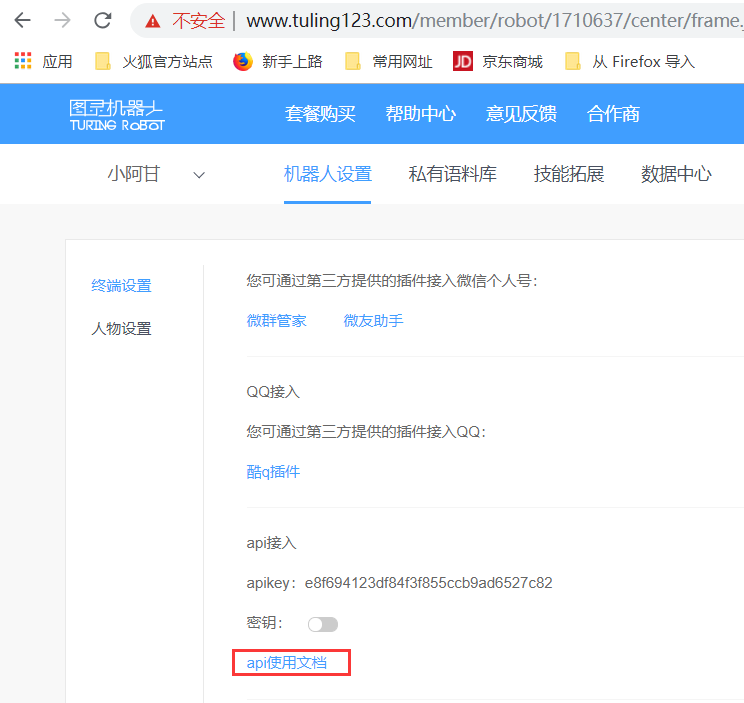
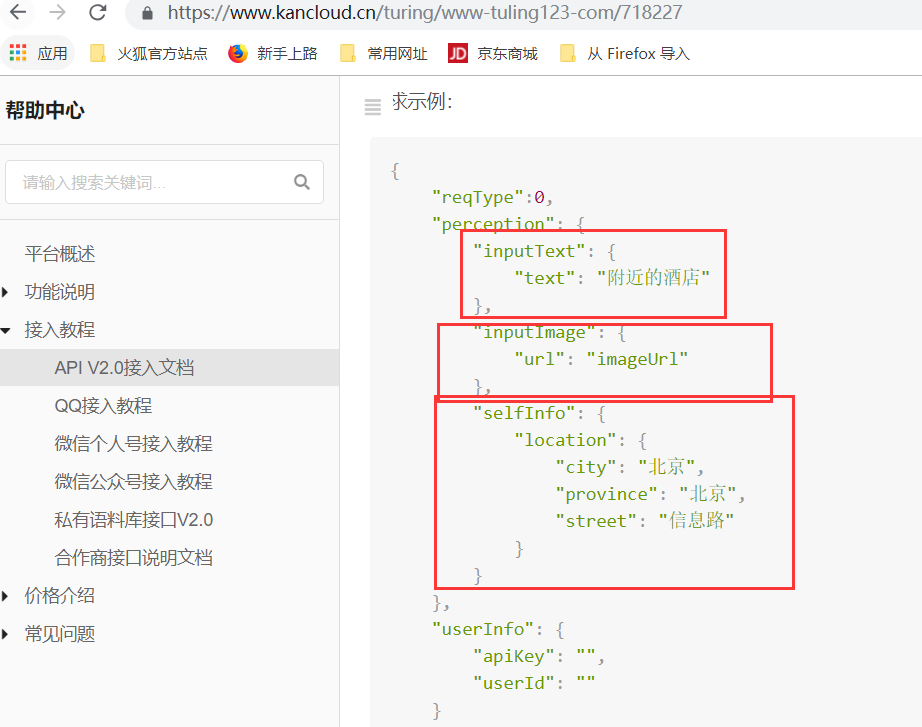
下图中,我们可以看到可以接入的是"文本","图像","位置"
接口地址:

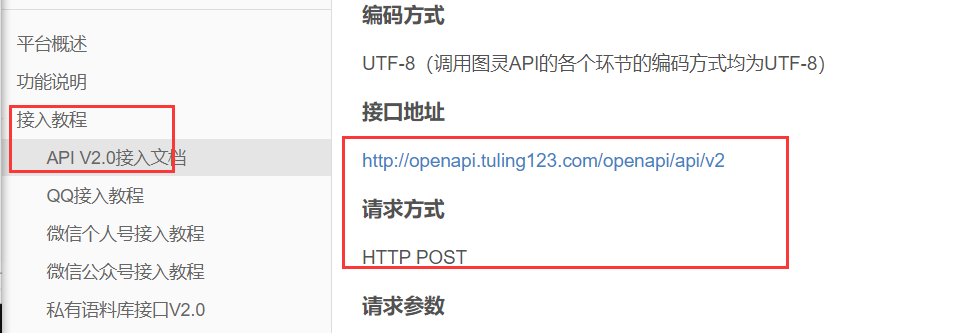
URL="http://openapi.tuling123.com/openapi/api/v2" import requests res=requests.post("http://openapi.tuling123.com/openapi/api/v2") print(res.content) #结果是bytes类型的 print(res.text) #结果是文本类型的 print(res.json()) #这个结果是json类型的,这个是字典类型的

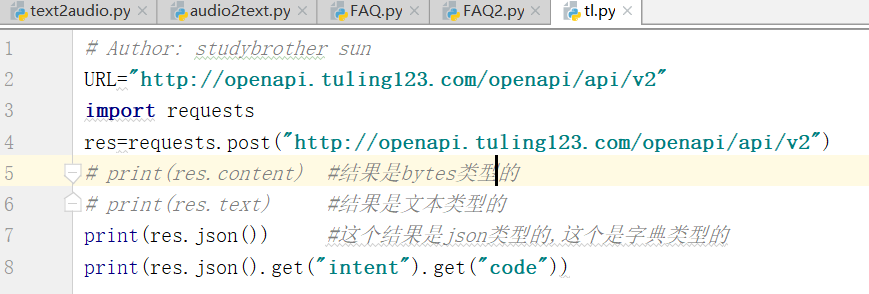
运行:得到下面的结果

很明显json是错误的.
tl.py
# Author: studybrother sun URL="http://openapi.tuling123.com/openapi/api/v2" import requests data={ "reqType":0, "perception": { "inputText": { "text": "今天天气不错"#可以修改的位置,向机器人问的问题. }, "inputImage": { "url": "imageUrl" }, "selfInfo": { "location": { "city": "北京", "province": "北京", "street": "信息路" } } }, "userInfo": { "apiKey": "e8f694123df84f3f855ccb9ad6527c82", "userId": "12666" } } res=requests.post("http://openapi.tuling123.com/openapi/api/v2" ,json=data) # print(res.content) #结果是bytes类型的 # print(res.text) #结果是文本类型的 print(res.json()) #这个结果是json类型的,这个是字典类型的 # print(res.json().get("intent").get("code"))
下面是一种回答:
再次运行,又得到另一种回答

这个时候,我们再次升级,将1.语音识别,2.语音合成,3.短文本相似度,4.图灵机器人融合:处理成4个函数
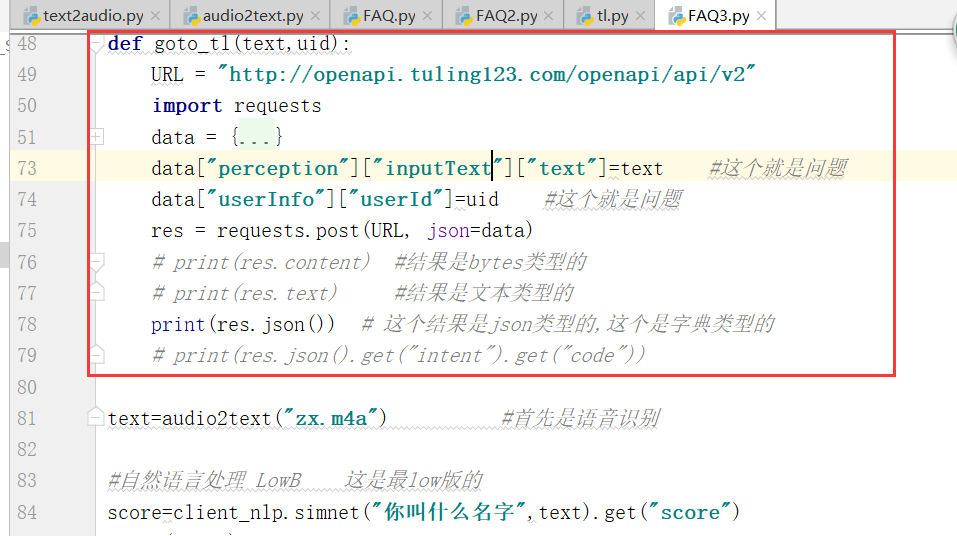
上边还没有写完,需要一个返回值

综合版本:
# Author: studybrother sun import os from aip import AipSpeech,AipNlp #从文本到声音 """ 你的 APPID AK SK """ APP_ID = '16027612' API_KEY = 'B4Pi3KnxI7Gh2xyrafvygQL6' SECRET_KEY = 'tcl4ZkM7Mkla3ygzFXanrgRjHOTXoWvt' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) # res=client_nlp.simnet("你叫什么名字","你的名字是什么你的名字是什么") # print(res) #上边是语音客户端 #定义一个语音合成: def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 5, # 音量 "spd": 4, # 语速 "pit": 7, # 语调 "per": 4 # 度丫丫的声音 }) # print(result) #注释这个,显示的更清晰一些 # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) return "audio.mp3" #注意,这个地方需要写一个返回文件!!!!!!! def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) # buffer指的是流,还有上边的client那一行不区分大小写. print(res.get("result")[0]) #注意,出错的位置没有返回,下一行进行处理 return res.get("result")[0] #注意,出错的位置没有返回,这行进行处理!!!!!! # print(res) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def goto_tl(text,uid): URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "reqType": 0, "perception": { "inputText": { "text": "今天天气不错" # 可以修改的位置 }, "inputImage": { "url": "imageUrl" }, "selfInfo": { "location": { "city": "北京", "province": "北京", "street": "信息路" } } }, "userInfo": { "apiKey": "e8f694123df84f3f855ccb9ad6527c82", "userId": "12666" } } data["perception"]["inputText"]["text"]=text #这个就是问题 data["userInfo"]["userId"]=uid #这个就是问题 res = requests.post(URL, json=data) # print(res.content) #结果是bytes类型的 # print(res.text) #结果是文本类型的 print(res.json()) # 这个结果是json类型的,这个是字典类型的 # print(res.json().get("intent").get("code")) return res.json().get("results")[0].get("values").get("text") text=audio2text("jttqbc.m4a") #首先是语音识别 #自然语言处理 LowB 这是最low版的 score=client_nlp.simnet("你叫什么名字",text).get("score") print(score) if score>=0.58: filename=text2audio("我的名字叫做无极剑圣") os.system(f"ffplay {filename}") #播放方式1 # os.system(filename) #直接,播放方式2 answer=goto_tl(text,"xiaoagan") filename = text2audio(answer) os.system(f"ffplay {filename}")
也是研究其他百度的接口:
6.百度AI介绍
下图中只是其中一页,不过这个是做的比较全面的平台.
