垃圾回收
对象存活算法:
1、引用计数器
引用计数算法:给对象中添加一个引用计数器,每当有一个地方引用它时,计数器就加1;当引用失效时,计数器值就减1;任何时刻计数器都为0的对象就是不可能再被使用的。
2、可达性分析算法
从GC Root开始搜索,且搜索不到的对象
跟搜索算法:以一系列名为 GC Root的对象作为起点,从这些节点开始往下搜索,搜索走过的路径称为引用链,当一个对象到GC Roots没有任何引用链的时候,则就证明此对象是不可用的。
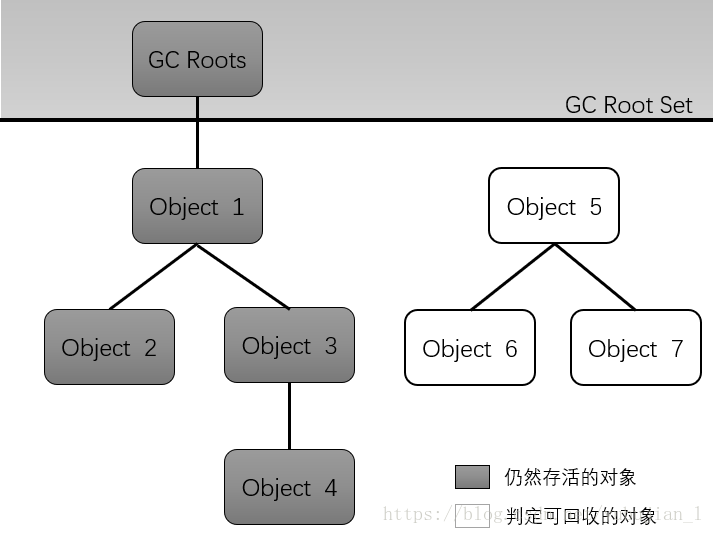
java GCRoot有哪些
①虚拟机栈(栈帧中的本地变量表)中引用的对象。(可以理解为:引用栈帧中的本地变量表的所有对象)
②方法区中静态属性引用的对象(可以理解为:引用方法区该静态属性的所有对象)
③方法区中常量引用的对象(可以理解为:引用方法区中常量的所有对象)
④本地方法栈中(Native方法)引用的对象(可以理解为:引用Native方法的所有对象)
垃圾收集算法:
可达性分析只是找到需要回收的对象。而之后的操作及算法接下来分析。
垃圾收集器,回收对象时,大部分朝生夕灭,少部分难以消亡,因此把他们集中在一起,虚拟机便可以使用 较低频率来回收这个区域,这样兼顾来及手机的时间开销和内存空间效率。
因而有了分带回收算法(minor GC, Major GC,Full GC)
minorGC:新生代收集
mijorGC:老年代收集(cms只针对老年代收集)
mixedGC:混合收集,收集新生代部分老年代,(G1)
FullGC:整个堆收集
回收类型的划分,与之匹配的垃圾收集算法:标记-复制算法,标记-清除算法,标记-整理算法。等针对性的垃圾收集算法。此批算法出现始于分代收集理论。
标记-清除:缺点,执行效率不确定,回收数据多是,执行时间增加,产生内存碎片。大对象过早触发垃圾回收
标记-复制:其介于标记-清除效率低,解决这一问题而产生,演进半分区复制分带策略,HotSpot虚拟机Serial、ParNew等新生代收集器均采用了这个策略进行内存布局。
标记-整理:标记-复制对于对象存活率高的进行较多复制操作效率太低,而且需要额外空间进行分配担保。老年代则不选用复制算法。因而提出了标记整理算法,其标记过程与标记-清除一致,但后续步骤不是直接回收,而是让所有存活的对象都向内存空间一端移动,然后清理掉边界以外的内存。
标记整理:STW耗时更长,但是对于整理后内存空闲成区域,访问内存效率更高。
HotSpot虚拟机高吞吐量收集器Parallel Scavenge就是基于标记整理算法。而关注低延时的CMS收集器则基于标记清除算法。
垃圾收集算法只是理论部分,其细节还有很多理论,如可达性分析从GC Roots入手枚举势必停顿时间过长,因此引出安全区域,记忆集合卡表,写屏障,并发可达性分析(三色标记,增量更新和原始快照解决黑色错误标记为白色问题)来优化缩短GC Roots枚举停顿的时间。
垃圾收集器则是理论的具体实践。
垃圾回收器内容请参加:【GC收集器】和【内存分配与回收的策略】