一、zookeeper介绍:
ZooKeeper是一个分布式且开源的分布式应用程序协调服务。
zookeeper集群特性:整个集群种只要有超过集群数量一半的zookeeper工作只正常的,那么整个集群对外就是可用的,假如有2台服务器做了一个zookeeper集群,只要有任何一台故障或宕机,那么这个zookeeper集群就不可用了,因为剩下的一台没有超过集群一半的数量,但是假如有三台zookeeper组成一个集群,那么损坏一台就还剩两台,大于3台的一半,所以损坏一台还是可以正常运行的,但是再损坏一台就只剩一台集群就不可用了。那么要是4台组成一个zookeeper集群,损坏一台集群肯定是正常的,那么损坏两台就还剩两台,那么2台不大于集群数量的一半,所以3台的zookeeper集群和4台的zookeeper集群损坏两台的结果都是集群不可用,一次类推5台和6台以及7台和8台都是同理,所以这也就是为什么集群一般都是奇数的原因。
1、安装JDK环境
1、将下载的JDK包解压(有几个集群主机,就配置几个)
[root@web1 src]# tar xvf jdk-8u212-linux-x64.tar.gz [root@web1 src]# ln -s /usr/local/src/jdk1.8.0_212/ /usr/local/jdk [root@web1 src]# ln -s /usr/local/jdk/bin/java /usr/bin
2、配置JDK环境
[root@web1 src]# vim /etc/profile.d/jdk.sh export HISTTIMEFORMAT="%F %T `whoami`" export export LANG="en_US.utf-8" export JAVA_HOME=/usr/local/jdk export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin [root@web1 src]# . /etc/profile.d/jdk.sh
2、zookeeper安装
zookeeper 下载地址:http://zookeeper.apache.org/releases.html
不要下载最新和太旧的版本,尽量使用较新的版本。
1、将下载下来的zookeeper包进行解压,并创建软链接。(有几个集群主机,配置几个)
[root@web1 src]# tar xvf zookeeper-3.4.14.tar.gz [root@web1 src]# ln -s /usr/local/src/zookeeper-3.4.14 /usr/local/zookeeper
2、修改zookeeper配置文件,实现zookeeper集群功能
[root@web1 conf]# pwd /usr/local/src/zookeeper-3.4.14/conf [root@web1 conf]# cp zoo_sample.cfg zoo.cfg # 复制zookeeper配置文件 [root@web1 conf]# mkdir /usr/local/zookeeper/data # 有几个zookeeper集群就创建一个目录,存放zookeeper数据的位置 [root@web1 conf]# vim zoo.cfg # 修改zookeeper配置文件 dataDir=/usr/local/zookeeper/data # 自定义zookeeper保存数据目录 clientPort=2181 # 客户端端口号 maxClientCnxns=4096 #客户端最大连接数 autopurge.snapRetainCount=512 # 设置zookeeper保存多少次的客户端数据 autopurge.purgeInterval=1 # 设置zookeeper间隔多少小时清理一次保存的客户端数据 server.1=192.168.7.104:2888:3888 # 如果有三个集群,就写三个对应的IP地址。 server.2=192.168.7.105:2888:3888
3、对每个zookeeper集群设置一个myid,必须与上面的zoo.cfg配置文件下面的server.xxx的ID对应,有几个集群就需要设置几个ID。
[root@web1 conf]# echo 1 > /usr/local/zookeeper/data/myid [root@tomcat-web2]# echo 2 > /usr/local/zookeeper/data/myid
4、启动zookeeper服务
[root@web1 ~]# /usr/local/zookeeper/bin/zkServer.sh start #启动zookeeper服务器 [root@web1 ~]# /usr/local/zookeeper/bin/zkServer.sh status # 查看启动的状态,如果不是以下的状态,说明集群失败 ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: follower # 从服务器 [root@tomcat-web2 bin]# /usr/local/zookeeper/bin/zkServer.sh start [root@tomcat-web2 bin]# /usr/local/zookeeper/bin/zkServer.sh status #查看zookeeper启动状态 ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: leader # 主服务器
5、将zookeeper设置为开机启动
[root@tomcat-web2 src]# vim /etc/rc.d/rc.local /usr/local/zookeeper/bin/zkServer.sh start # 设置为开机启动 [root@tomcat-web2 src]# chmod +x /etc/rc.d/rc.local #加上执行权限
二、kafka简介:
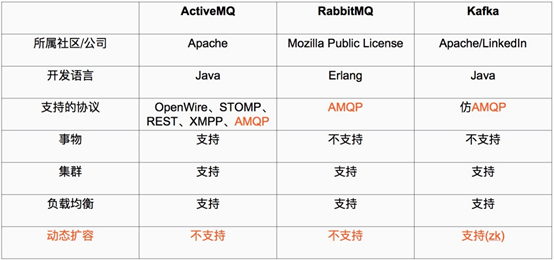
Kafka 被称为下一代分布式消息系统,是非营利性组织ASF(Apache Software Foundation,简称为ASF)基金会中的一个开源项目,比如HTTP Server、Hadoop、ActiveMQ、Tomcat等开源软件都属于Apache基金会的开源软件,类似的消息系统还有RbbitMQ、ActiveMQ、ZeroMQ,最主要的优势是其具备分布式功能、并且结合zookeeper可以实现动态扩容。
kafka要想正常运行,必须配置zookeeper,否则无论是kafka集群还是客户端的生存者和消费者都无法正常的工作的;所以需要配置启动zookeeper服务。
官方文档:http://www.infoq.com/cn/articles/apache-kafka
kafka术语解释
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)
Partition
parition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
Producer
负责发布消息到Kafka broker
Consumer
消费消息。每个consumer属于一个特定的consuer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
1、下载并安装kafka
kafka下载地址:http://kafka.apache.org/downloads.html
1、将下载的kafka包进行解压,并创建软链接(有几个集群主机就配置几个)
[root@tomcat-web2 src]# tar xvf kafka_2.12-2.1.0.tgz #解压kafka包 [root@web1 src]# ln -s /usr/local/src/kafka_2.12-2.1.0 /usr/local/kafka # 设置软链接
2、修改kafka配置文件(有几个集群主机,就配置几个)
[root@tomcat-web2 kafka_2.12-2.1.0]# pwd /usr/local/src/kafka_2.12-2.1.0 [root@tomcat-web2 kafka_2.12-2.1.0]# vim config/server.properties # 修改kafka配置文件 broker.id=1 # 与zookeeper的ID一致,有几个kafka主机,就在每个kafka写入对应的zookeeper主机ID listeners=PLAINTEXT://192.168.7.104:9092 # 写成本地的服务器地址,针对不同的集群,在不同的kafka主机写对应的IP地址 log.dirs=/usr/local/kafka/kafka-logs # 日志存放目录 log.retention.hours=24 # 保留日志的时间,以小时为单位 zookeeper.connect=192.168.7.104:2181,192.168.7.105:2181 # 设置与zookeeper主机的连接地址,有几个集群,就配置几个IP地址。
3、启动kafka服务,以守护进程的方式启动
# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
查看此时kafka启动状态,第一台kafka已经启动

查看第二台kafka主机状态,也已经启动

4、将kafka设置为开机启动(经测试暂时未能成功,但是可以在开机启动时候使用kafka的service命令将kafka启动)
(1)配置kafka的环境变量
[root@web1 init.d]# vim /etc/profile.d/kafka.sh
export KAFKA_HOME="/usr/local/kafka"
export PATH="${KAFKA_HOME}/bin:$PATH"
[root@web1 init.d]# . /etc/profile.d/kafka.sh
(2)在/etc/init.d/目录下编辑一个启动脚,并加上执行权限chmod +x kafka
#!/bin/sh
#
# chkconfig: 345 99 01
# description: Kafka
#
# File : Kafka
#
# Description: Starts and stops the Kafka server
#
source /etc/rc.d/init.d/functions
KAFKA_HOME=/usr/local/kafka # 修改kafka的存放路径
KAFKA_USER=root # 使用root启动
export LOG_DIR=/usr/local/kafka/kafka-logs # 定义kafka的log存放位置,与前面的kafka配置文件有关
[ -e /etc/sysconfig/kafka ] && . /etc/sysconfig/kafka
# See how we were called.
case "$1" in
start)
echo -n "Starting Kafka:"
/sbin/runuser -s /bin/sh $KAFKA_USER -c "nohup $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties > $LOG_DIR/server.out 2> $LOG_DIR/server.err &"
echo " done."
exit 0
;;
stop)
echo -n "Stopping Kafka: "
/sbin/runuser -s /bin/sh $KAFKA_USER -c "ps -ef | grep kafka.Kafka | grep -v grep | awk '{print $2}' | xargs kill"
echo " done."
exit 0
;;
hardstop)
echo -n "Stopping (hard) Kafka: "
/sbin/runuser -s /bin/sh $KAFKA_USER -c "ps -ef | grep kafka.Kafka | grep -v grep | awk '{print $2}' | xargs kill -9"
echo " done."
exit 0
;;
status)
c_pid=`ps -ef | grep kafka.Kafka | grep -v grep | awk '{print $2}'`
if [ "$c_pid" = "" ] ; then
echo "Stopped"
exit 3
else
echo "Running $c_pid"
exit 0
fi
;;
restart)
stop
start
;;
*)
echo "Usage: kafka {start|stop|hardstop|status|restart}"
exit 1
;;
esac
重新加载配置文件
# systemctl daemon-reload # service kafka start # 启动kafka
(3)将kafka添加到服务上,然后设置为开机启动
# chkconfig --add kafka # 添加到服务上 # chkconfig kafka on #设置为开机启动
2、基于logstash测试kafka和zookeeper
1、在logstash服务器的/etc/logstash/conf.d目录下创建一个测试kafka的标准输出、标准输入文件
input {
stdin {}
}
output {
kafka {
topic_id => "hello"
bootstrap_servers => "192.168.7.104:9092" # IP地址为kafka的地址以及监听的端口号,测试其他集群的kafka主机,需要修改IP地址即可。
batch_size => 5
}
stdout {
codec => rubydebug
}
}
2、开始测是kafka的日志文件是否可以传到logstash服务器上
[root@logstash conf.d]# logstash -f log-to-kafka.conf # 测试配置文件
{
"host" => "logstash",
"message" => "hello world", # 输入的hello world已经可以在logstash显示
"@version" => "1",
"@timestamp" => 2020-03-15T03:30:03.426Z
}
nihao
{
"host" => "logstash",
"message" => "nihao", # 输入的nihao也已经可以在logstash服务上显示
"@version" => "1",
"@timestamp" => 2020-03-15T03:30:12.118Z
}