网络并发
进程的基础
1.程序
一堆静态的代码文件
2.进程
一个正在运行的程序
由操作系统操控调用交由cpu运行 ,被cpu运行
2.操作系统
1。管理控制协调计算机中硬件与软件的关系
2。操作系统的作用?
2.没有操作系统:你们在开发软件
第一层。对硬件(cpu,内存,磁盘)协调,调用
第二层 如何调用接口去编程
第一个作用:将一些对硬件操作的复杂丑陋的接口, 变成简单美丽的接口,open函数
第二个作用:多个进程抢占一个(cpu)资源时,操 作系统会将你的执行变得合理有序,雨露均沾(比较 快感受不到)
阻塞:input read write sleep recv accept sendto recvfrom 。。。
操作系统的发展史
百万级代码 写的系统
多道技术
最早出现的计算机:算盘
电子类的计算机发展史
第一代计算机1940~1955(手工操作----穿孔卡片)
在大学里出现了机房,想使用计算机必须预约
先连接调配各个硬件,1.5小时,真空管,然后在插上程序调试,效率低
优点:个人独享整个计算机资源
缺点;1.硬件条件插线,耗时
2.所有人串行执行
第二代 1955~1965 磁带存储--批处理系统
优点程序员不用亲自对硬件进行插线操控,效率提高
可以进行批量处理代码
缺点:
1.程序员不能肚子使用计算机
2.你的所有程序还是串行
第三代集成电路,多道程序系统(1955~1965)
1.集成电路:把所用的硬件变小,线路板
2.将两套不同的生产线合并成一个生产线
技术上的更新:多道技术,操作系统的理念
空间上的复用
将一个内存可以同时加载多个进程
时间上的复用
实现将cpu在多个进程之间来回切换,并且保留状态,在切回来还能保持原样
几乎所有的程序都会有io阻塞
同时加载到内存 3个任务,3个进程,每个进程都有阻塞情况,只要cpu运行一个进程时,遇到阻塞立马会切换,长时间占用cpu也会切换
提升效率,最大限度的使用cpu
如果是一个IO(阻塞)密集型进程,来回切换提升效率
如果在一个计算密集型,耗时来会切换降低效率
第三代计算机 广泛采用必须的保护硬件(程序之间的内存彼此隔离)之后,推动第三代计算机应用而生
每个人占用计算机的时间有限的
多人(少于10个)共同使用一个计算机主机
第四代计算机:至今
面向字:大型的科学计算机
面向字符:商用计算机
进程的理论(重点)
2.操作系统
1。管理控制协调计算机中硬件与软件的关系
2。操作系统的作用?
2.没有操作系统:你们在开发软件
第一层。对硬件(cpu,内存,磁盘)协调,调用
第二层 如何调用接口去编程
第一个作用:将一些对硬件操作的复杂丑陋的接口, 变成简单美丽的接口,open函数
第二个作用:多个进程抢占一个(cpu)资源时,操 作系统会将你的执行变得合理有序,雨露均沾(比较 快感受不到)
多道技术
空间上的复用
将一个内存可以同时加载多个进程
时间上的复用
实现将cpu在多个进程之间来回切换,并且保留状态,在切回来还能保持原样
当进程遇到IO阻塞,或者长时间运行,操作系统会将此进程刮起,保留状态,会将cpu强行切换到另一个进程
进程之间的通信方式
串行:所有的任务(进程)一个一个完成
并发:一个cpu完成多个任务,在不同的任务中来回切换,看起来是同时完成的
并行:多个cpu执行多个任务,真正的同时完成
阻塞:cpu遇到io就是阻塞
非阻塞:没有IO叫非阻塞
程序:一堆静态文件
一个正在执行的程序任务,一个进程
一个程序能否同时开启多个进程?可以
进程的创建(进程之间不允许通信)
一个子进程必须基于主进程
主进程是启动子进程的
一个主进程可以开启多个子进程。
unix:fork创建子进程
uninx(linux,mac):创建一个子进程会完完全全复制一个主进程所有的资源,初始资源不变。
windows:操作系统调用CreateProcess处理进程的创建
windows:创建一个子进程,会copy主进程所有的资源,但是会改变一些资源
系统是最主进程
进程的状态
运行程序运行到io进行阻塞 程序进入阻塞状态
阻塞结束进入就绪态 需要在就绪态等待开始运行 等程序遇到io阻塞再进行运行
并发编程:多进程
某特破赛肾multiprocesssing模块 用来开启子进程
进程创建的两种方式()开辟需要的时间长
创建子进程需要时间 有时间停滞 会调用
p.start 是一个创建声明copy一份,一个cpu是并发
这个信号操作系统接收到之后,会从内存中开辟一个子进程空间,然后·在将主进程所有数据进行深copy加载到子进程 然后运行子进程
Process类的介绍
强调:
参数介绍
1.需要使用关键字的方式来指定参数
2.target是指定子进程要执行的任务(函数名),
3.args是函数的位置参数(实参以元组的形式)
4.name是(函数)子进程的名称
5.group参数未使用,值始终未None
方法
1.p.star()启动进程,并调用该子进程的p.run()
2.p.run():进程启动运行的方法,是它去调用target指定的函数,我们自定义类的类
3.p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
4.p.is_alive():如果p仍然运行,返回True
5.p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
进程的属性介绍:
1.p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
2.p.name:进程的名称
3.p.pid:进程的pid
4.p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
5.p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
第一个方式
from multiprocessing import Process
import time
def ppt(name):
print(f'{name}is running')
time.sleep(2)
print(f'{name}is gone')
if __name__ == '__main__':
ppt()pp2()pp3()#串行运行
p=Process(target=ppt,args=('长鑫',))#对应一个target 是对应一个方法 args==是传入的值
p.start()#启动进程
print('===煮开水')
time.sleep(3)
第二种方式
第二种#默认的用类run
from multiprocessing import Process
import time
class MYprocess(Process):#process是父类
def __init__(self):#必须调用父类的init实现
super().__init__()#执行父类的init
self.name=name
def run(self):#必须是run要不会继承父类的run
print(f'{self.name}is running')
print(f'{self.name}is gone')
if __name__ == '__main__':
p=MYprocess()#创建一个进程对象(子程序)
p2=MYprocess()#创建一个进程对象(子程序)
p.start()#时间会有时间延迟#声明开辟一个子进程的空间会把主进程的初始值深copy下来
p.start()#因为会有时间延迟
print('===主')#先走这、、
会引用父类的init 要运行本地的init 要使用父类的super.init()
子类没有用父类的 必须有run
tasklist命令行查看所有进程的pid
进程的pid是进程的唯一标识 运行一次开辟一次
import os
print(os.getpid())#每次获取的id都不同的(子进程)
如何在子进程获得主进程的pid
import os
print(os.getppid())#每次获取的id都不同的(父进程)
子进程的名字会改变子进程深copy过来的主进程的名字 不会改变原有的名字
空间隔离
进程与进程之间是由物理隔离:不能共享内存数据(lsook 队列)
#空间隔离
from multiprocessing import Process
import time
name=[1,2]
def ppt():
name.append(1)
print(name)
if __name__ == '__main__':
# ppt()pp2()pp3()串行运行
p=Process(target=ppt)
#对应一个target 是对应一个方法 args==是传入的值
p.start()
time.sleep(3)
print(f'主{name}')#子程序深copy 会有空间隔离
import是模块后面的属性
进程对象join方法
join让主进程等待子进程运行结束之后在运行主程序
join就是阻塞 主程序有join就会阻塞等待对应子进程运行完
同时开启 前面执行后面也在执行读秒 join是结束 会阻塞
join
from multiprocessing import Process
import time
def task(sec):
print('is,running')
time.sleep(sec)
print('is gone')
if __name__ == '__main__':
start_time=time.time()
p1=Process(target=task,args=(6,))
p2=Process(target=task,args=(7,))
p3=Process(target=task,args=(8,))
p1.start()#同时执行
p2.start()#同时执行
p3.start()#同时执行
p1.join()#遇到阻塞 等待执行完
end_name = time.time() - start_time
print(end_name)###
p2.join()
end_name = time.time() - start_time
print(end_name)
p3.join()
end_name=time.time()-start_time
print(end_name)
进程对象其他属性
from multiprocessing import Process
import time
import os
def task(n):
time.sleep(3)
print('%s is running' %n,os.getpid(),os.getppid())
if __name__ == '__main__':
p1 = Process(target=task,args=(1,),name = '任务1')
p1.start()
# p1.terminate()
# time.sleep(2) # 睡一会,他就将我的子进程杀死了#没有直接杀死。
# print(p1.is_alive()) # False#判断子程序是否是活着的
-------------------------------------
#改名字
# print(p1.name) # 给子进程起名字
# for i in range(3):
# p = Process(target=task, args=(1,))
# print(p.name) # 给子进程起名字
代码示例
守护进程
daemon
版本一
from multiprocessing import Process
import time
class MYprocess(Process):
# def __init__(self,name):#必须调用父类的init实现
# super().__init__()#
# self.name=name
def run(self):#必须是run要不会继承父类的run
print(f'{self.name}is running')
print(f'{self.name}is gone')
if __name__ == '__main__':
p=MYprocess()
p,daemon=True#要在设置执行子进程之前设置成守护进程
p1.start()#时间会有时间延迟
p.start()#因为会有时间延迟
print('===主')#先走这、、
#主进程结束子进程也结束
子进程守护着守护主进程,只要主进程结束
版本二
#主进程代码运行完毕,守护进程就会结束
from multiprocessing import Process
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
if __name__ == '__main__':#必须要有--main
p1=Process(target=foo)
p2=Process(target=bar)
p1.daemon=True
p1.start()
p2.start()
# p1.join()
# p2.join()
print("main-------") #打印该行则主进程代码结束,则守护进程p1应该被终止,可能会有p1任务执行的打印信息123,因为主进程打印main----时,p1也执行了,但是随即被终止
#随着守护的主进程的结束而结束了
僵尸进程
僵尸进程与孤儿进程
-
主进程需要等待子进程结束之后,主进程才结束
-
主程序时刻监测子进程的运行状态,当子进程结束之后,一段时间,将子进程回收
为什么主程序不在子进程结束后对其回收
1.主进程与子进程是异步关系,主进程无法马上捕获子进程什么时候结束
2.如果子进程结束之后马上再内存释放资源,主进程就没有办法检测子进程的状态
unix针对于上面的问题提供一个机制
所有的字节内存结束之后,会立马释放掉文件的操作连接,内存的大部分数据,但是会保留一些内容:进程号,结束时间,运行状态,等待主进程检测,回收
僵尸进程:
当子进程结束之后,在被主进程回收之前,都会进入僵尸进程状态
不是全部子进程结束
僵尸进程有无危害?
如果父进程不对僵尸进程进行回收(wait/waitpid),会产生大量的僵尸进程,这样就会占用内存,占用进程pid
孤儿进程:
父进程由于某种原因,结束了,但是你的子进程还在运行中,这样你的这些子进程就成了孤儿进程,你的父进程如果结束,你的所有的孤儿进程就会被init进程回收,init就变成了他们的主进程
出现僵尸进程如何解决?
父进程产生了大量子进程,子程序结束但是不回收,这样就会形成大量的僵尸进程,解决方式僵尸直接杀死父进程,将所有的僵尸进程变成孤儿进程,由init进行回收
互斥锁(lock)
并发是效率优先,需求是顺序优先,
多个进程共抢一个资源,要保证顺序优先,并发是效率优先,需求是顺序优先,串行,是一个一个来
强制顺序优先用join串行强制性排序不合理,为保证公平,应该是先到先得
什么时候用互斥锁
多个任务共抢同一个资源(数据),如果你想要顺序优先(数据安全),一定要让其串行
互斥锁的作用
牺牲效率保证数据安全
把子程序变成串行
可以把串行变得合理有序,保证公平,先到先得 可以把部分变成串行
一把互斥锁锁不能连续锁 只能锁一次
互斥锁必须成对出现
from multiprocess import Lock
lock.acquire()
lock.release()
acquire上锁,release开锁
# 三个同事 同时用一个打印机打印内容. # 三个进程模拟三个同事, 输出平台模拟打印机.
# 版本一:
# from multiprocessing import Process
# import time
# import random
# import os
# # def task1():
# print(f'{os.getpid()}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{os.getpid()}打印结束了')
# # def task2():
# print(f'{os.getpid()}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{os.getpid()}打印结束了')
# # def task3():
# print(f'{os.getpid()}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{os.getpid()}打印结束了')
#
# if __name__ == '__main__':
#
# p1 = Process(target=task1)
# p2 = Process(target=task2)
# p3 = Process(target=task3) #
# p1.start()
# p2.start()
# p3.start()
# 现在是所有的进程都并发的抢占打印机,
# 并发是以效率优先的,但是目前我们的需求: 顺序优 先.
# 多个进程共强一个资源时, 要保证顺序优先: 串行,一 个一个来.
# 版本二:
# from multiprocessing import Process
# import time
# import random
# import os
# # def task1(p):
# print(f'{p}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{p}打印结束了')
# # def task2(p):
# print(f'{p}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{p}打印结束了') # # def task3(p):
# print(f'{p}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{p}打印结束了')
# # if __name__ == '__main__':
# # p1 = Process(target=task1,args= ('p1',))
# p2 = Process(target=task2,args= ('p2',))
# p3 = Process(target=task3,args= ('p3',))
# # p2.start()
# p2.join()
# p1.start()
# p1.join()
# p3.start()
# p3.join()
# 我们利用join 解决串行的问题,保证了顺序优先,但是 这个谁先谁后是固定的. # 这样不合理. 你在争抢同一个资源的时候,应该是先到 先得,保证公平.
# 版本3:
from multiprocessing
import Process from multiprocessing
import Lock
import time
import random
import os
def task1(p,lock):
''' 一把锁不能连续锁两次
lock.acquire()
lock.acquire()
lock.release()
lock.release()
'''
lock.acquire()
print(f'{p}开始打印了') time.sleep(random.randint(1,3))
print(f'{p}打印结束了')
lock.release()
def task2(p,lock):
lock.acquire()
print(f'{p}开始打印了') time.sleep(random.randint(1,3))
print(f'{p}打印结束了')
lock.release()
def task3(p,lock):
lock.acquire()
print(f'{p}开始打印了') time.sleep(random.randint(1,3))
print(f'{p}打印结束了')
lock.release()
if __name__ == '__main__':
mutex = Lock()
p1 = Process(target=task1,args= ('p1',mutex))
lock与join的区别. 共同点: 都可以把并发变成串行, 保证了顺序. 不同点: join人为设定顺序,lock让其争抢顺序,保证了公 平性.
3. 进程之间的通信: 进程在内存级别是隔离的,但是文件在磁盘上,
1. 基于文件通信. 利用抢票系统讲解.
p2 = Process(target=task2,args= ('p2',mutex)) p3 = Process(target=task3,args= ('p3',mutex))
p2.start()
p1.start()
p3.start()
锁总结,
当很多进程共抢一个资源(数据)时,你要保证顺序(数据的安全一定要串行),
join和锁的区别
join
我们利用join 解决串行的问题,保证了顺序优先
锁
会合理的对子进程进程排序根据运行的速度和操作系统的阻塞进行排队 保证公平不强制固定
举例查票
# 版本二:
# from multiprocessing import Process
# import time
# import random
# import os
# # def task1(p):
# print(f'{p}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{p}打印结束了')
# # def task2(p):
# print(f'{p}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{p}打印结束了') # # def task3(p):
# print(f'{p}开始打印了')
# time.sleep(random.randint(1,3))
# print(f'{p}打印结束了')
# # if __name__ == '__main__':
# # p1 = Process(target=task1,args= ('p1',))
# p2 = Process(target=task2,args= ('p2',))
# p3 = Process(target=task3,args= ('p3',))
# # p2.start()
# p2.join()
# p1.start()
# p1.join()
# p3.start()
# p3.join()
# 我们利用join 解决串行的问题,保证了顺序优先,但是 这个谁先谁后是固定的.
# 这样不合理. 你在争抢同一个资源的时候,应该是先到 先得,保证公平.
队列(相当于一个容器)
队列和管道都是将数据存放于内存中
我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
from multiprocessing import Process,Queue
import random
import time
import os
lis=[]
def search(mete):
time.sleep(random.randint(1,5))
s=mete.get()
mete.put(s)
print(f'手机尾号{os.getpid()}的用户查看了,还剩余名额{s}')
# print(lis)
def paid(mete,mete1):
time.sleep(random.randint(1,3))
s=mete.get()
if int(s)>0:
s-=1
mete.put(s)
phone=os.getpid()
print(f'手机尾号{phone}获得了手机名额剩余{s}')
mete1.put(phone)
else:
# mete1.get()
# lis.append(mete1.get())
# print(f'{lis}恭喜以上获得名额')
print(f'手机尾号{os.getpid()}没有得到名额')
mete.put(s)
def task(mete,lis):
search(mete)
paid(mete,lis)
if __name__ == '__main__':
mete=Queue()
mete1=Queue(10)
mete.put(10)
lst =[]
for i in range(30):
p=Process(target=task,args=(mete,mete1))#传入了两个管道
p.start()
lst.append(p)
for i in lst:
i.join()
while 1:
try:
print(mete1.get(block=False))
except Exception:
break
队列是串行,谁先拿到谁在前面
put往队列里面放值 get把值取出删除**
先进先出
消费者和生产者模型
编程思想,模型,设计模式,理论都是给你一种编程的方法,以后类似的情况,套用即可
模型三要素
生产者:产生数据的
消费者:接受数据做进一步处理的
容器:盆(队列)
队列起到什么作用
容器耦合性过强没有,起到缓冲的作用,平衡生产力与消费力,解耦
from multiprocessing import Process
from multiprocessing import Queue
import time
import random
def producer(q,name):#利用for循环 传入
for i in range(1,6):#生成6个
time.sleep(random.randint(1,2))
res=f'{i}号包子'
q.put(res)#把6传进去
print(f'生产者{name}生产了{res}')
def consumer(q,name):
while 1:
try:
food=q.get(timeout=3)
time.sleep(random.randrange(1,4))
print(f'�33[31;0m消费者{name}吃了{food}�33[0m')
except Exception:
return
if __name__ == '__main__':
q=Queue()
p1=Process(target=producer,args=(q,'孙宇'))
p2=Process(target=consumer,args=(q,'海狗'))
p1.start()
p2.start()
具有阻塞的几个方法
线程
什么是线程
一条流水线的工作流程。
进程:在内存中开启一个进程空间,然后将主进程的所有数据复制一份
然后调用线程去执行代码
执行角度(线程)
运行过程本身叫做线程
同一个线程资源共用 执行是进程的代码
资源角度(进程)
是cpu最小的执行单位
资源单位,一个进程存在至少存在主线程
进程是一个资源单位 是一个独立的资源 有空间隔离
如果想要通信 需要利用queue
在内存中申请一块空间把代码放进去cpu调用内存空间的代码的过程
运行的过程还会使用进程中的资源
描述具体开启一个进程
开启一个进程:进程会在内存中开辟一个进程空间,将主进程的资料数据全部复制一份,线程会执行里面的代码
线程vs进程
进程
子进程是先运行主进程所有程序
线程
线程先加载主进程里面的代码
线程速度快 并发同时执行两个任务 共用资源
不会复制
- 开启进程的开销非常大,比开启线程的开销大很多
- 开启线程的速度非常快,要快几十倍到上百倍
- 线程和线程之间可以共享数据,进程与进程之前需借助队列等方法实现通信(线程数据共享,进程数据不共享)
线程的应用
涩乳癌的thread
同一进程内的资源数据对于多个线程来说是共享的
线程里面pid就是一个主进程的pid
from threading import Thread
def task(name):
print(os.getpid())#主进程的pid
if __name__ == '__main__':
t1=Thread(target=task,args=('海狗',))
t1.start()
print('===主线程')
线程没有pid 主进程开辟子进程比较耗时
并发:一个cpu执行多个任务,看起来像是同时执行多个任务
单个进程开启三个线程,并发的执行任务
开启三个进程并发的执行任务
主进程需要等待线程结束
主线程子线程没有地位之分,但是,一个进程谁在干活?一个主线程在干活,当干完活了。等待其他线程干完活之后,才能结束本进程
3.开启线程的两种方式
线程没有主次之分 两种方式函数和类
不需要main 写了好区分 nnnnnn
'''
基于函数的
'''
from threading import Thread
import time
def task(name):
print(f'{name}is running')
time.sleep(1)
print(f'{name}is gone')
if __name__ == '__main__':
t1=Thread(target=task,args=('海狗',))
t1.start()
print('===主线程')
#基于类
from threading import Thread
import time
class func(Thread):
def __init__(self,name):
super().__init__()
self.name=name
print(1)
def run(self):
print(self.name)
if __name__ == '__main__':#这句话可以不写 因为线程没有主次之分只是多开一个线程
t1=Thread(target=func,args=('立业',))
t1.start()
print('主线程')
进程vs线程代码
1.速度对比(主进程一定在子进程之前)(线程速度快 先执行子线程,在执行主进程)
2.线程里面pid就是一个主进程的pid,线程里面没有pid
3.同一进程内的资源数据对于多个线程来说是共享的
线程的其他方法(了解)
也可以使用进程里面的方法
join是一样 的 都是等待子线程(进程)结束
daemon 守护进程 主线程执行完就结束了
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。
threading模块提供的一些方法:
# threading.currentThread()同等与current_thread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from mulitprocessing import Process
from threading import Thread
# from threading import Thread
# from threading import currentThread
# from threading import enumerate
# from threading import activeCount
# import os
# import time
#
# x = 3
# def task():
# # print(currentThread())
# time.sleep(1)
# print('666')
# print(123)
# if __name__ == '__main__':
#
# t1 = Thread(target=task,name='线程1')
# t2 = Thread(target=task,name='线程2')
# # name 设置线程名
# t1.start()
# t2.start()
# # time.sleep(2)
# # print(t1.isAlive()) # 判断线程是否活着
# # print(t1.getName()) # 获取线程名
# # t1.setName('子线程-1')
# # print(t1.name) # 获取线程名 ***
#
# # threading方法
# print(current_thread().name)
# # print(currentThread()) # 获取当前线程的对象
# # print(enumerate()) # 返回一个列表,包含所有的线程对象
# print(activeCount()) # ***
# print(f'===主线程{os.getpid()}')
守护线程
t.daemon#t.setDaemon(true)
守护线程:如果守护线程的生命周期小于其他线程,则他肯定结束
线程速度快 所以主线程结束之前会先执行线程 最后和主线程一起结束,
主线程结束条件是 所有子线程结束 因为资源共用 主进程不能结束
from threading import Thread
import time
def sayhi(name):
print('你滚!')
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t = Thread(target=sayhi,args=('egon',))
# t.setDaemon(True) #必须在t.start()之前设置
t.daemon = True
t.start() # 线程的开启速度要跟进程开很多
print('主线程')
线程互斥锁
为什么数据不会持续更新
线程比较快 线程同时操作一个数据 所有开启的一个子线程都会先拿到初始值 进行操作
不加锁
from threading import Thread
import time
x = 100
def task():
global x
temp = x
time.sleep(0.1)
temp -= 1
x = temp
if __name__ == '__main__':
t_l1 = []
for i in range(100):
t = Thread(target=task)
t_l1.append(t)
t.start()
for i in t_l1:
i.join()
print(f'主{x}')
不加锁抢占同一个资源的问题
加锁
from threading import Thread
from threading import Lock
import time
x = 100
lock = Lock()
def task():
global x
lock.acquire()
temp = x
time.sleep(0.1)
temp -= 1
x = temp
lock.release()
if __name__ == '__main__':
t_l1 = []
for i in range(100):
t = Thread(target=task)
t_l1.append(t)
t.start()
for i in t_l1:
i.join()
print(f'主{x}')
同步锁保证数据安全
死锁现象
锁套锁现象
递归锁(RLOCK)
解决死锁现象 会有一个计数器,可以连续加锁加一次计数器加一,计数器变为别人才能抢
from threading import Thread,Lock
import time
from threading import RLock
lock_A=lock_B=RLock()
lock_A1=Lock()
lock_B1=Lock()
class func(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_B.release()
lock_B.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t=func()
t.start()
信号量(Semaphore)三破
Semaphore信号量
允许多个线程 使用信号量 控制并发次数
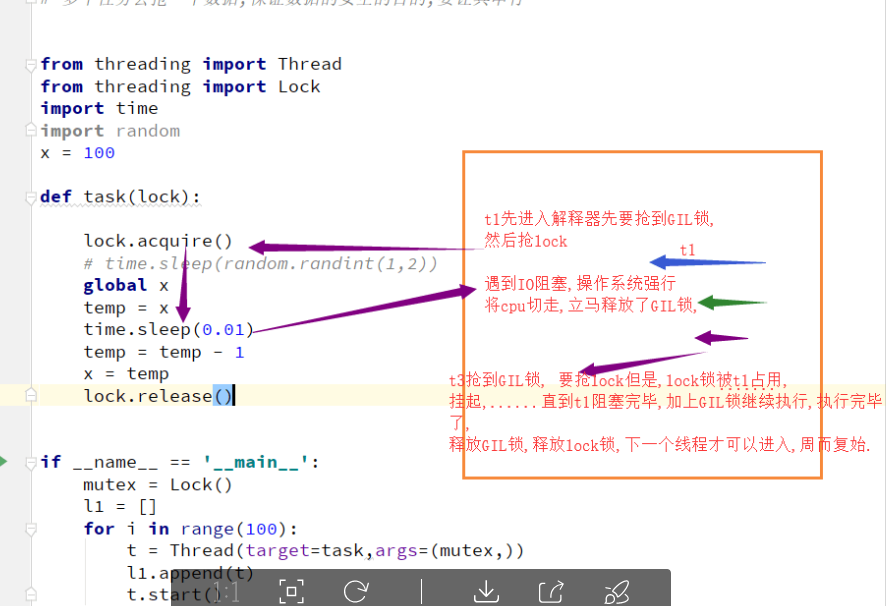
GIL锁全局解释器锁
创py 空间,开启一个进程
py解释器,py文件都会加载进去
Cpython自带GIL锁
单个进程多线程是并发执行,执行的时候会加锁,执行到io阻塞会挂起,把锁打开,
cpu切换到后面的线程会继续执行,
cpyhon为什么加锁?
1.当时都是单核时代,而且cpu价格非常贵
2.如果不加全局锁解释器锁,开发Cpython解释器的程序源就会在源码内部各种主动加锁,解锁,非常麻烦,各种死锁现象等待,他为了省事儿,直接进入解释器时给线程加一个锁
优点:
保证解释器Cpython的解释器的数据资源的安全。
缺点:
单个进程的多线程不能利用多核
Jpython没有锁
pypy没有GIL锁
多核时代,我将Cpython的GIL锁去掉行么?
因为Cpython解释器所有业务逻辑都是围绕单个线程实现的,去掉这个GIL锁,几乎不可能
单个进程的多线程可以并发,但是不能利用多核,不能并行
多个进程可以并发,并行
io密集型:
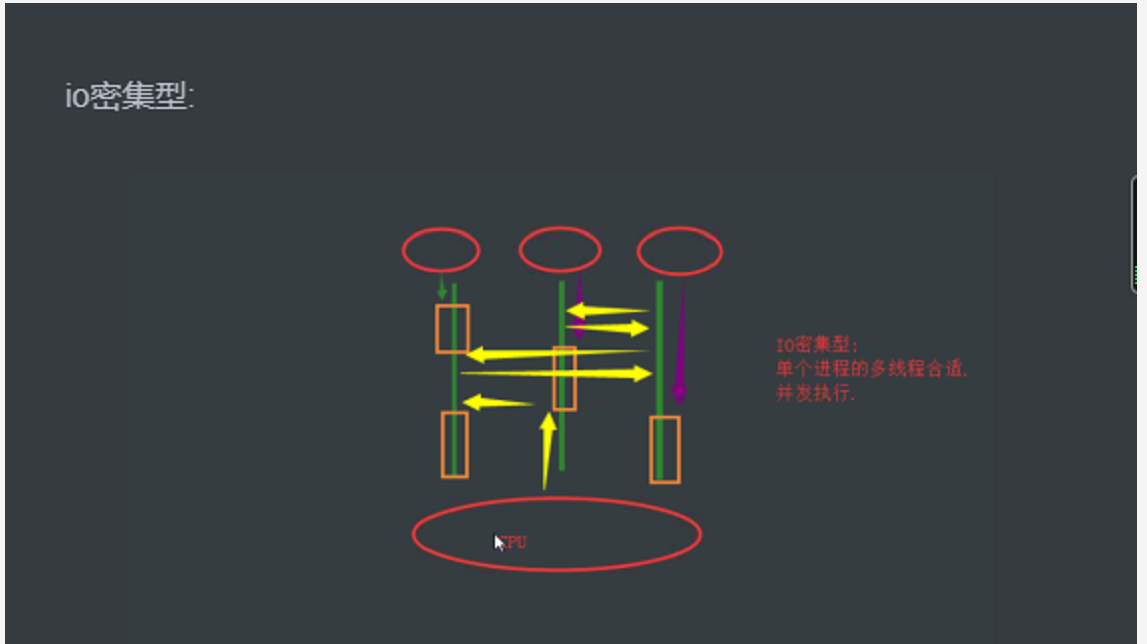
遇到io阻塞cpu就会切换 空间复用 阻塞结束 GIL锁加上继续执行,执行完释放GIL锁
单个进程的多线程合适,并发
计算密集型:
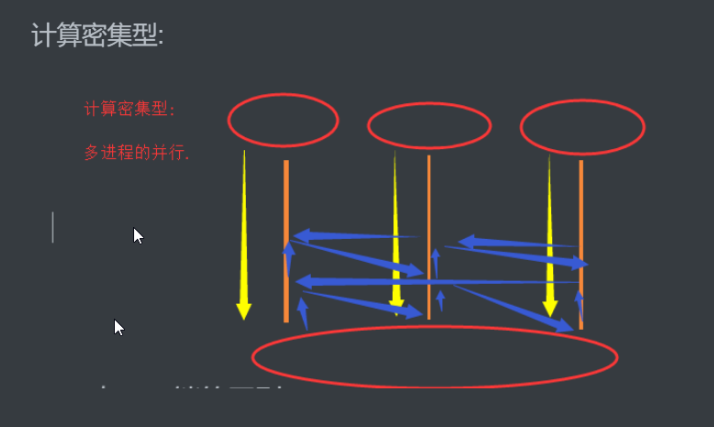
因为并发效果 线程运行一段时间 cpu会进行强行切换
多进程是可以并行(调用多个cpu)的
GlL与lock锁的区别
相同点:都是同种锁,互斥锁
不同点:
GIL锁全局解释器锁,保护解释器内部的资源数据的安全。
GlL锁上锁,释放锁无需手动操作
自己代码中的互斥锁保护进程中资源的安全
自己定义的互斥锁必须自己手动上锁释放锁
验证计算密集型,IO密集型的效率
代码验证:
计算密集型
开启多进程合适 多进程(并发,并行)比单进程多线程(并发)快效率高
io密集型
单个进程的多线程的并发
多线程实现socket通信
线程不用mian里创建
无论是多线程还剩多进程,如果按照上面的写法
来一个人客户端请求,我就开一个线程(进程),来一个请求开一个线程(进程)请求
应该是这样的:你的计算机允许范围内,开启的线程进程数量越多越好