前言:
基于密度聚类的经典算法 DBSCAN(Density-Based Spatial Clustering of Application with Noise, 具有噪声的基于密度的空间聚类应用)是一种基于高密度连接区域的密度聚类算法。
DBSCAN的基本算法流程如下:从任意对象P 开始根据阈值和参数通过广度优先搜索提取从P 密度可达的所有对象,得到一个聚类。若P 是核心对象,则可以一次标记相应对象为当前 类并以此为基础进行扩展。得到一个完整的聚类后,再选择一个新的对象重复上述过程。 若P是边界对象,则将其标记为噪声并舍弃
缺陷:
如聚类的结果与参数关系较大,导致阈值过大容易将同一聚类分割, 或阈值过小容易将不同聚类合并
固定的阈值参数对于稀疏程度不同的数据不具适应性,导致密度小的区域同一聚类易被分割, 或密度大的区域不同聚类易被合并
DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 一个比较有代表性的基于密度的聚类算法。与层次聚类方法不同,它将簇定义为密度相 连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的空间数 据库中发现任意形状的聚类。
基于密度的聚类方法是以数据集在空间分布上的稠密度为依据进行聚类,无需预先设定 簇的数量,因此特别适合对于未知内容的数据集进行聚类。而代表性算法有:DBSCAN,OPTICS。 以DBSCAN算法举例,DBSCAN目的是找到密度相连对象的最大集合。
1.DBSCAN算法
首先名词解释:
ε(Eps)邻域:以给定对象为圆心,半径为ε的邻域为该对象的ε邻域
核心对象:若ε邻域至少包含MinPts个对象,则称该对象为核心对象
直接密度可达:如果p在q的ε邻域内,而q是一个核心对象,则说对象p从对象q出发是直接密度可达的
密度可达:如果存在一个对象链p1 , p2 , … , pn , p1=q, pn=p, 对于pi ∈D(1<= i <=n), pi+1 是从 pi 关于ε和MinPts直接密度可达的, 则对象p是从对象q关于ε和MinPts密度可达的
密度相连:对象p和q都是从o关于ε和MinPts密度可达的,那么对象p和q是关于ε和MinPts密度相连的
噪声: 一个基于密度的簇是基于密度可达性的最大的密度相 连对象的集合。不包含在任何簇中的对象被认为是“噪声”
边界点:边界点不是核心点,但落在某个核心点的邻域内。
DBSCAN 算法根据以上的定义在数据库中发现簇和噪声。簇可等价于集合D中, 这个簇核心对象密度可达的所有对象的集合。
DBSCAN算法描述:
输入:包含n个对象的数据库,半径ε,最少数目MinPts。
输出:所有生成的簇,达到密度要求。
1.REPEAT
2.从数据库中抽取一个未处理过的点;
3.IF 抽出的点是核心点 THEN找出所有从该点密度可达的对象,形成一个簇
4.ELSE 抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一点;
5.UNTIL 所有点都被处理;
DBSCAN算法步骤 :
输入:数据集D,参数MinPts, ε 输出:簇集合
(1) 首先将数据集D中的所有对象标记unvisited ;
(2) do
(3) 从D中随机选取一个unvisited对象p,并将p标记为visited ;
(4) if p的 ε 邻域 包含的对象数至少为MinPts个
(5) 创建新簇C ,并把p添加到c中;
(6) 令N为 p的 ε 邻域 中对象的集合;
(7) for N 中每个点pi
(8) if pi 是unvisited
(9) 标记pi 为visited;
(10) if pi 的ε 邻域 至少有MinPts个 对象,把这些对象添加到N ;
(11) if pi 还不是任何簇的对象。将 pi 添加到 簇C中 ;
(12) end for
(13) 输出C
(14) Else 标记p 为噪声
(15) Untill 没有标记为unvisited 的对象
下面给出一个样本事务数据库(见下表),对它实施DBSCAN算法。
根据所给的数据通过对其进行DBSCAN算法,以下为算法的步骤(设n=12,用户输入ε=1,MinPts=4)
| 序列 | 属性1 | 属性2 |
| 1 | 2 | 1 |
| 2 | 5 | 1 |
| 3 | 1 | 2 |
| 4 | 2 | 2 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 5 | 2 |
| 8 | 6 | 2 |
| 9 | 1 | 3 |
| 10 | 2 | 3 |
| 11 | 5 | 3 |
| 12 | 2 | 4 |

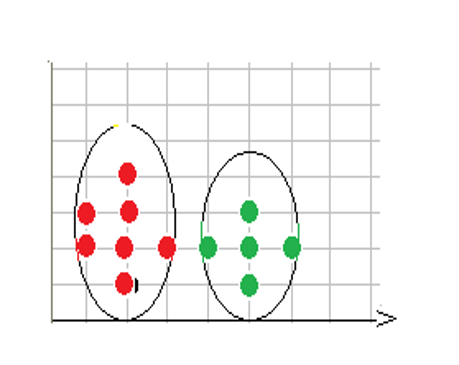
DBSCAN聚类过程
第1步,在数据库中选择一点1,由于在以它为圆心的 以1为半径的圆内包含2个点(小于4),因此它不是核心点,选择下一个点。
第2步,在数据库中选择一点2,由于在以它为圆心的,以1为半径的圆内包含2个点, 因此它不是核心点,选择下一个点。
第3步,在数据库中选择一点3,由于在以它为圆心的,以1为半径的圆内包含3个点, 因此它不是核心点,选择下一个点。
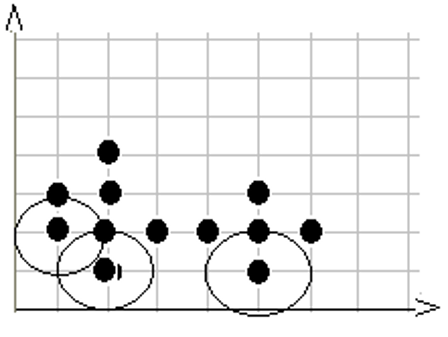
第4步,在数据库中选择一点4,由于在以它为圆心的,以1为半径的圆内包含5个点, 因此它是核心点,寻找从它出发可达的点(直接可达4个,间接可达3个), 聚出的新类{1,3,4,5,9,10,12},选择下一个点。
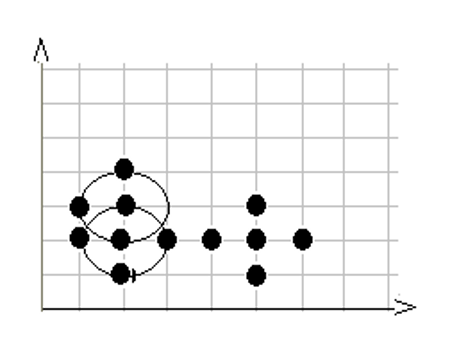
第5步,在数据库中选择一点5,已经在簇1中,选择下一个点。
第6步,在数据库中选择一点6,由于在以它为圆心的,以1为半径的圆内包含3个点, 因此它不是核心点,选择下一个点。
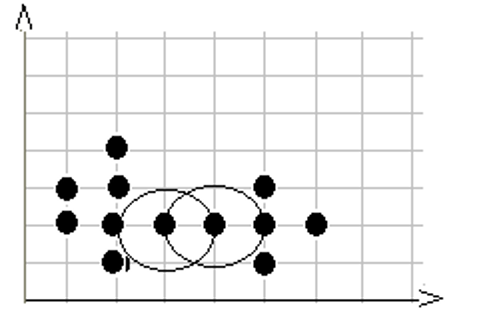
第7步,在数据库中选择一点7,由于在以它为圆心的,以1为半径的圆内包含5个点, 因此它是核心点,寻找从它出发可达的点,聚出的新类{2,6,7,8,11},选择下一个点。
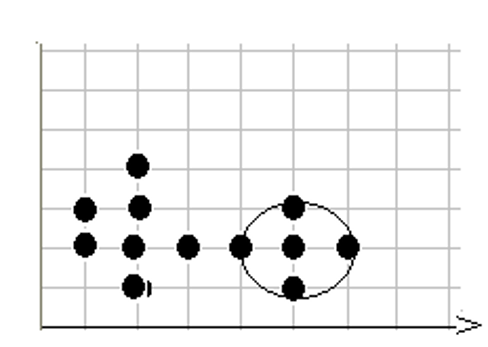
第8步,在数据库中选择一点8,已经在簇2中,选择下一个点。
第9步,在数据库中选择一点9,已经在簇1中,选择下一个点。
第10步,在数据库中选择一点10,已经在簇1中,选择下一个点。
第11步,在数据库中选择一点11,已经在簇2中,选择下一个点。
第12步,选择12点,已经在簇1中,由于这已经是最后一点所有点都以处理,程序终止。
算法执行过程
| 步骤 | 选择的点 | 在ε中点的个数 | 通过计算可达到而找到新的簇 |
| 1 | 1 | 2 | 无 |
| 2 | 2 | 2 | 无 |
| 3 | 3 | 3 | 无 |
| 4 | 4 | 5 | 簇C1:{1,3,4,5,9,10,12} |
| 5 | 5 | 3 | 已在一个簇C1中 |
| 6 | 6 | 3 | 无 |
| 7 | 7 | 5 | 簇C2:{2,6,7,8,11} |
| 8 | 8 | 2 | 已在一个簇C2中 |
| 9 | 9 | 3 | 已在一个簇C1中 |
| 10 | 10 | 4 | 已在一个簇C1中 |
| 11 | 11 | 2 | 已在一个簇C2中 |
| 12 | 12 | 2 | 已在一个簇C1中 |
DBSCAN的时间复杂性:
DBSCAN算法要对每个数据对象进行邻域检查时间性能较低。
~DBSCAN的基本时间复杂度是 O(N*找出Eps领域中的点所需要的时间), N是点的个数。 最坏情况下时间复杂度是O(N2)
~在低维空间数据中,有一些数据结构如KD树,使得可以有效的检索特定点给定距离内的所有点, 时间复杂度可以降低到O(NlogN)
DBSCAM的空间复杂性:
在聚类过程中,DBSCAN一旦找到一个核心对象,即以该核心对象为中心向外扩展. 此过程中核心对象将不断增多,未处理的对象被保留在内存中.若数据库中存在庞大的聚类, 将需要很大的存来存储核心对象信息,其需求难以预料.
当数据量增大时,要求较大的内存支持 I/0 消耗也很大;低维或高维数据中,其空间都是O(N)