简介
在微服务架构中,项目中前端发起一个请求,后端可能跨几个服务调用才能完成这个请求。如果系统越来越庞大,服务之间的调用与被调用关系就会变得很复杂,那么这时候我们需要分析具体哪一个服务出问题了就会显得很困难。Spring Cloud Sleuth服务链路跟踪功能就可以帮助我们快速的发现错误根源以及监控分析每条请求链路上的性能等。Spring Cloud Sleuth主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了Zipkin。
相关术语
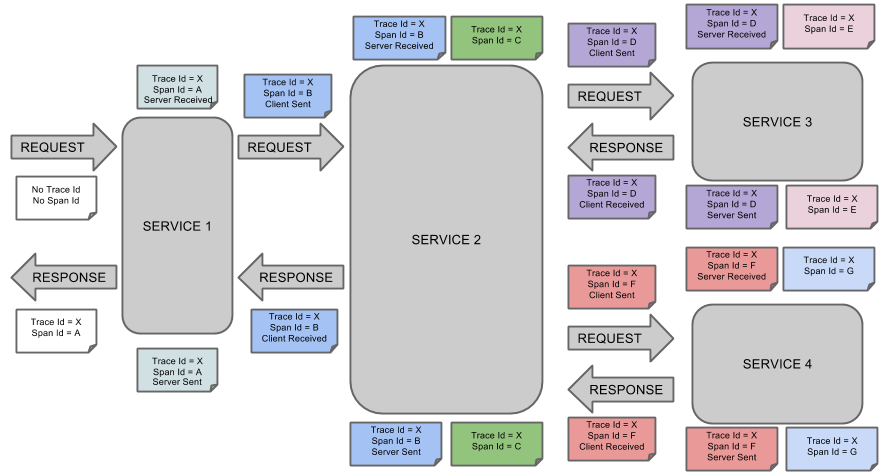
(1)Span: 基本的工作单元。Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-value 注解(tags),span处理者的ID(通常为IP)。
(2)Trace: 包含一系列的工作单元span,它们组成了一个树型结构。
(3)Annotation 用于及时记录存在的事件。常用的Annotation如下:
cs:客户端发送(client send) 客户端发起一个请求,表示span开始
sr:服务器接收(server received) 服务器接收到客户端的请求并开始处理,sr - cs 的时间为网络延迟
ss:服务器发送(server send) 服务器处理完请求准备返回数据给客户端。ss - sr 的时间表示服务器端处理请求花费的时间
cr:客户端接收(client received) 客户端接收到处理结果,表示span结束。 cr - cs 的时间表示客户端接收服务端数据的时间
Zipkin服务端构建
Zipkin服务端并非不能自己代码构建,但官方目前建议用已经提供好的server。构建方法也可以查看官网(https://zipkin.io/pages/quickstart.html)。这里不再赘述。
我们最终会得到一个jar包,启动即可。
nohup java -Xms128m -Xmx512m -jar zipkin-server-*exec.jar > /dev/null 2>&1 &
启动后访问http://<hostname>:9411/zipkin/即可。
所有可以配置的参数都可以通过https://github.com/openzipkin/zipkin/blob/master/zipkin-server/src/main/resources/zipkin-server-shared.yml查看。
Zipkin客户端构建
pom.xml相关依赖中需要引入spring-cloud-starter-zipkin
<!-- Spring cloud starter: zipkin --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
application.yml中,spring.zipkin.base-url指定server端的地址,spring.sleuth.sampler.probalility指定采样百分比,默认0.1,改成1.0表示所有数据都采用。
spring: # Zipkin info zipkin: baseUrl: http://<hostname>:9411 # Zipkin sleuth: enable it exportable to zipkin sleuth: sampler: probability: 1.0
访问url,我们可以看到一个完整的调用路径。
