1.深度神经网络对于任何领域都是适用的
深度神经网络(Deep Neural Networks,DNN)在过去的数年已经在图像分类、语音识别、自然语言处理中取得了突破性的进展。在实践中的应用已经证明了它可以作为对于一种十分有效的技术手段应用在大数据相关领域中。深度神经网络通过众多的简单线性变换层次性的进行非线性变换对于数据中的复杂关系能够很好的进行拟合,即对数据特征进行的深层次的挖掘。因此作为一种技术手段,深度神经网络对于任何领域都是适用的。
2.推荐系统简介
推荐系统的功能是帮助用户主动的找到满足偏好的个性化物品并推荐给用户。在本质上可以当做一个个性化的搜索引擎,输入的数据为用户行为信息、偏好信息等,返回的结果为最符合查询条件的物品列表。数学化的表示:
物品列表=f(用户偏好)−−−−−−−−−−−公式(1)
我们的推荐引擎就扮演者这里的函数的角色,它主要需要完成两部分的工作:
A > 针对查询条件对物品的相关性进行估计。
B > 晒选出topN个最相关的物品。
因此,推荐系统的关键就是对上面函数的一种求解。
实际应用中的物品数量很大,因此在满足业务需要的前提下,对于所有物品使用评估函数进行评估是不实际的。因此为了实现性能与效果的平衡,大多的推荐系统将以上的计算过程分为两个部分:
☆推荐召回
☆推荐排序
推荐召回指在所有物品集合中检索到符合用户兴趣的候选集,大约筛选出几百个候选的列表。排序的目的是要利用展示、点击(或转化)数据,然后加入更多的用户、物品特征,对推荐候选进行更精细的修正、打分。这种模式另一个好处是能够利用多种候选集。
因此,推荐系统需要完成两步计算:候选集生成和排序,这两阶段的估计函数分别表示为g和h,即有:
f=g(h(x))−−−−−−−−−−−−−−−−−−−−−−−−−公式(2)
3.使用神经网络近似求解函数参考1
对于函数的求解大多分为以下几种途径:
确定性求解:通过对数据的规律进行建模直接求解。
确定性近似求解:通过变分推断的相关方法进行求解,EM。
随机性近似求解: 通过采样的方法对函数进行求解,蒙特卡洛方法。
非结构化求解
不管这个函数是什么样的,总会有一个神经网络能够对任何可能的输入 x网络可以得到对应的值 f(x)(或者某个足够准确的近似)
即使函数有很多输入或者多个输出,这个结果都是成立的,f=f(x1,...,xm) 。例如,这里有一个输入为 m=3和输出为 n=2的网络:

综上,神经网络作为一种近似化求解方法可以用来对于公式(2)两个函数g, h进行近似。
4.推荐召回
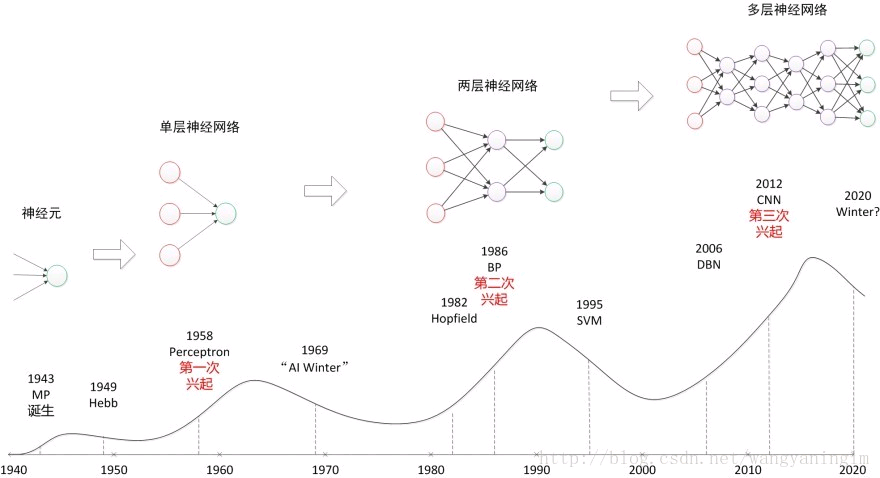
Google利用DNN来做YouTube的视频推荐其模型图如下图所示。通过对用户观看的视频,搜索的关键字做embedding,然后在串联上用户的side
information等信息,作为DNN的输入,利用一个多层的DNN学习出用户的隐向量,然后在其上面加上一层softmax学习出Item的隐向量,进而即可为用户做Top-N的推荐。

Autoencoder(AE)是一个无监督学习模型(类似矩阵分解),它利用反向传播算法,让模型的输出等于输入。利用AE来预测用户对物品missing的评分值,该模型的输入为评分矩阵中的一行(User-based)或者一列(Item-based),其目标函数通过计算输入与输出的损失来优化模型,而评分矩阵中missing的评分值通过模型的输出来预测,进而为用户做推荐,其模型如下图所示。后续,Denoising Autoencoder(DAE)是在AE的基础之上,对输入的训练数据加入噪声。所以DAE必须学习去除这些噪声而获得真正的没有被噪声污染过的输入数据。因此,这就迫使编码器去学习输入数据的更加鲁棒的表达,通常DAE的泛化能力比一般的AE强。Stacked
Denoising
Autoencoder(SDAE)是一个多层的AE组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。还有Bayesian
SDAE等等众多方法均同源于此。

5.推荐排序
Wide & Deep 模型,Google利用DNN和传统广义线性模型结合的方式实现对于Google Play
中的应用进行推荐。
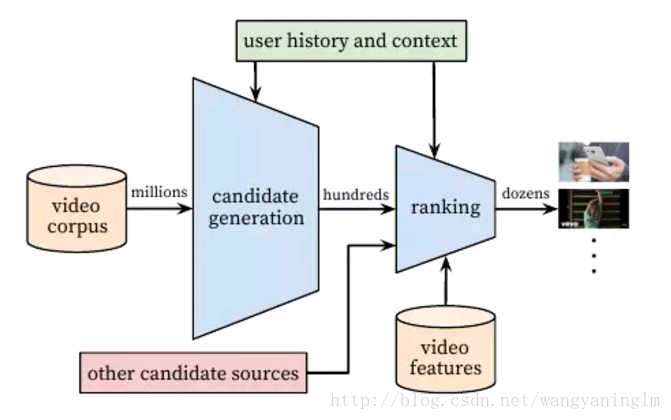
DNN具有很好的泛化性而广义的线性模型具有很好的记忆性,通过将二者结合,在实现很好的泛化性基础上对于不相干的物品规则进行了抑制。在输入层将类别特征通过embedding和连续值进行连接形成输入的嵌入向量并通过三层的网络形成输入的隐向量,并在输入层将app相关的特征进行交叉相乘,连同隐向量输入一个逻辑输出单元中,最终输出对于特定app的评分。
6.神经网络其他应用
词向量表示,使用浅层神经网络方法进行学习。利用序列数据中蕴含的信息,将物品的表示由高维稀疏表示映射到低维密集表示。典型的模型方法有:word2vec
[无监督]和GloVe[无监督] (Global Vectors for Word Representation)。
——————————————————————————————————–
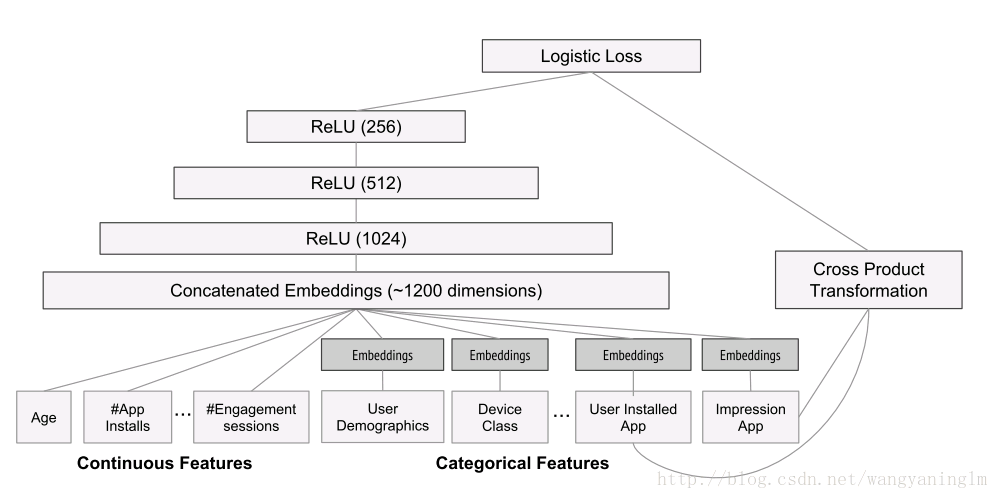
下图展示的是基于CBOW层次网络结构的word2vec,输入层是若干个词的词向量,通过映射层进行累加,输出层中黄色节点是非叶子节点代表一个类别,而叶子节点代表一个词向量,整个输出层是一个霍夫曼树。假设对于特定的上下文,特定的中间词的预测概率最大,进行训练得到词的低维密集表示。
——————————————————————————————————–
例如:语句“直接修改此文件”,分词后有“直接”,“修改”,“此文件”。那么对于词“修改”进行训练,那么输入的上下文就是“直接”、“此文件”,我们期望“修改”的概率最大。通过使用大量样本训练后,可以在叶子节点训练得到对应词的向量表示。之后,可以计算词向量之间的相似性来代表词之间的相似性,诸如此类对进一步的分析提供方便。
——————————————————————————————————–
7.神经网络的难点
由于神经网络用多层结构拟合复杂的非线性关系,具有庞大的参数,并且随着网络的深入进行训练愈发困难。因此对于实际中的应用具有以下难点:
1.需要大量的训练数据
2.调参不存在合理的选择方法
3.对于具体应用不存在标准的网络结构
8.当前数据应用深度模型面临的挑战
1.用户行为稀疏,因此数据中存在大量的噪音
2.媒体库数据可用字段较少
3.用户画像杂乱,用户属性信息采集不明确
总结
以前,计算资源宝贵,并且计算能力偏弱,因此为了实现智能化功能,需要研发人员将功能规则通过人为的方式间接的融入进算法当中,以此来减少计算量。但是由于用户的应用场景繁杂,因此往往存在着众多研发人员无法预估的情况。而且由于很多的近似求解方法需要得到精确地结果需要大量的计算而迫使多数应用场景无法实现和采用,因此在过去的数年间,应用层面的智能化发展停滞不前。而随着计算能力的迅速发展,利用大量计算实现智能化的功能已经成为可行策略。而深层神经网络算法以其强大的拟合能力就是适应了这种发展趋势,迅速的在图像、语音、自然语言等领域取得了巨大的成就。
个性化推荐作为众多智能场景中的一员,已经吸引了众多的研发人员投入其中,不同于图像、语音等具有丰富的特征且算法结果和真实样本不会产生互相影响,由于推荐中特征数据的繁杂,且推荐的结果影响着采集到的数据,目前推荐当中并不存在一种通用型的结构和方法。也有很多人将神经网络的方法应用在整体推荐的子领域当中已经取得了不错的效果。可以预见随着更多的人员参与进来,个性化推荐必将被神经网络的方法所侵占。
在工业中,在有限的资源投入的情况下,紧跟技术前沿的发展,将先进的方法在系统当中进行验证。或者对于行业取得稳定效果的方法进行验证并进行系统集成,产品将会获得巨大的收益。
附:
Word2vec 效果【节目vec之间的相似度】:
碟中谍5:神秘国度 【 # 危机13小时,# 碟中谍4,# 死亡飞车,# 极限特工2,# 虎胆龙威5,# 星际穿越,# 丛林奇兵, # 刺客联盟, # 谍影重重2, # 非常人贩】 86版西游记 【# 西游记动画片,# 西游记之锁妖封魔塔,# 西游记之大闹天宫(3D),# 西游记之大闹天宫,# 西游记之孙悟空三打白骨精, # 嘻游记, # 西游记之大圣归来, # 西洋镜, # 电哪咤, # 孙悟空七打九尾狐 】 射雕英雄传 【# 射雕英雄传 第3集,# 射雕英雄传 李亚鹏版,# 神雕侠侣,# 神雕侠侣[粤语版],# 天龙八部, # 方世玉与胡惠乾, # 倚天屠龙记大结局, # 新神雕侠侣, # 神雕侠侣黄晓明版, # 天涯明月刀】