作业格式
-
课程名称: 软件工程1916|W(福州大学)
-
作业要求: 结对第二次—文献摘要热词统计及进阶需求
-
GitHub项目地址:项目地址
-
项目签入记录:
-
基础需求
-
进阶需求

-
-
作业目标:学习如何结对共同完成编程任务。熟悉github的使用。
-
分工:
- 周杨富:负责主要代码的编写,对需求的实现。以及附加题的实现。
- 熊宁畅:负责一些功能代码的编写,博客文档的编写。
作业正文
1.PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 120 |
| • Design Spec | • 生成设计文档 | 30 | 15 |
| • Design Review | • 设计复审 | 30 | 15 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 60 | 80 |
| • Coding | • 具体编码 | 240 | 210 |
| • Code Review | • 代码复审 | 30 | 15 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 80 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 585 | 745 |
2.解题思路描述
- 思考过程
- 看到这个题目时,一开始只是粗略地大概看了一下需求是什么,所以一开始并没有感受到太大的难度。因为接触Java语言比较多,所以也选择用Java语言开发。但是在仔细研究过题目的需求后,发现细节问题很多。
- 初步思路是用Java中的文件处理相关类来实现,然后使用ArrayList和Map等数据结构对字符数、单词数等进行统计排序和输出。
-
- 在阅读到进阶需求时,因为之前有使用Python语言完成过一个原生爬虫,所以对爬虫有一定的了解。但是进阶需求中的一些需求比较懵,所以也在微信群里交流了一下大家对需求的理解。
- 资料查找
- 对于接触得比较偏少的知识点,主要还是通过向同学请教,或者上百度、也有到GitHub上搜索相应功能的demo,寻找相关的解决方法。
3.设计实现过程
-
基本需求
- 项目结构:
- 221600308&221600340
- -src
- -Main.java
- -WordCount.class
- -src
- 221600308&221600340
- 关系与流程
- 基本功能较为简单,有一个WordCount类,通过类内主函数调用writeFile方法和 getCount方法完成整个的功能。
- 类图

- 项目结构:
-
进阶需求
-
项目结构
- -src
- -Main.java
- -Main.class
- -BaseFunction.class
- -FileOperate.class
- -scr
- -result.txt(爬虫结果)
- -Main.java(爬虫程序,可以爬取CVPR2018论文列表)
- -Main,class(编译生成的可运行程序)
- -src
-
爬虫工具:Java Html解析器——Jsoup
-
爬虫思路
- 通过Http请求得到CVPR2018官网的html文档,经分析得到,论文的标题在div.class=“ptitle”中,通过getElementsByClass(“ptitle”)->ptitle.getElementsByTag(“a”).attr(“href”),并基础地址“http//openaccess.thecvf.com/”拼接,得到每一篇论文的访问地址。
- 进入论文页面后,根据Html文档通过选择器doc.select(“div#papertitle”).first().text()和doc.select(“div#abstract”).first().text()获取到论文的Title和Abstract并按格式输出到指定文件中。
-
关系与流程
- 分为三个类Main、BaseFunction和FileOperate。通过Main函数获取参数,调用BaseFunction中的方法计算。最后通过FileOperate中的方法进行文件读写操作。
-
类图
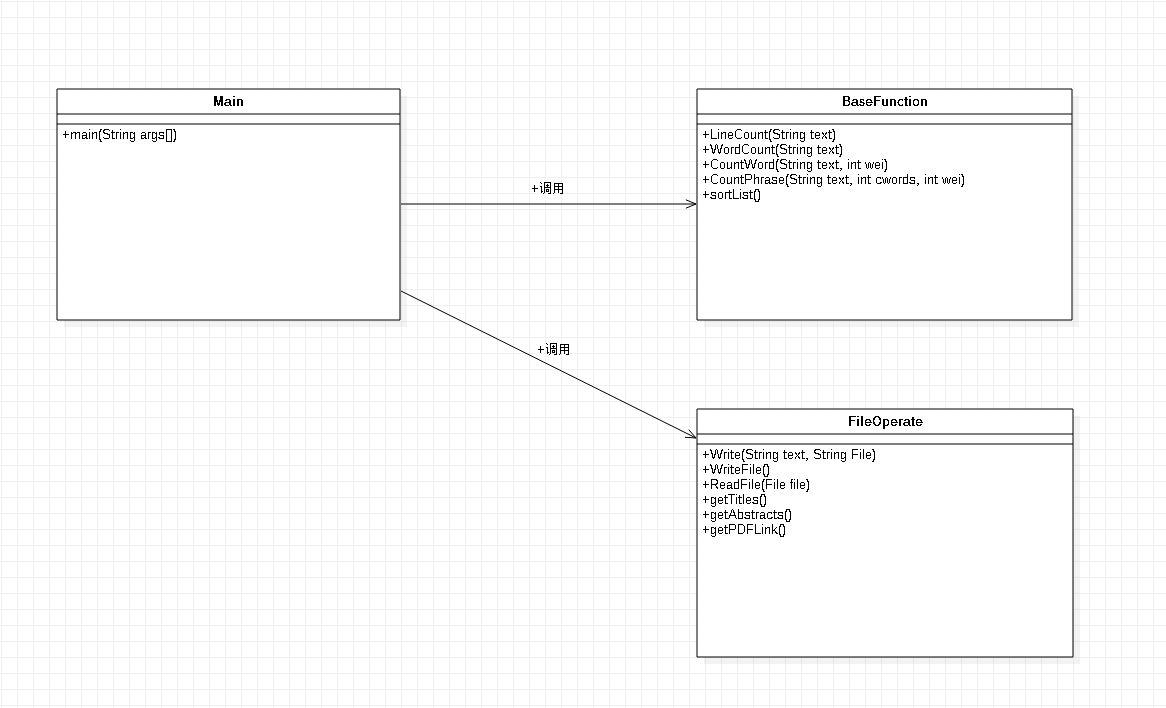
-
-
关键函数流程图
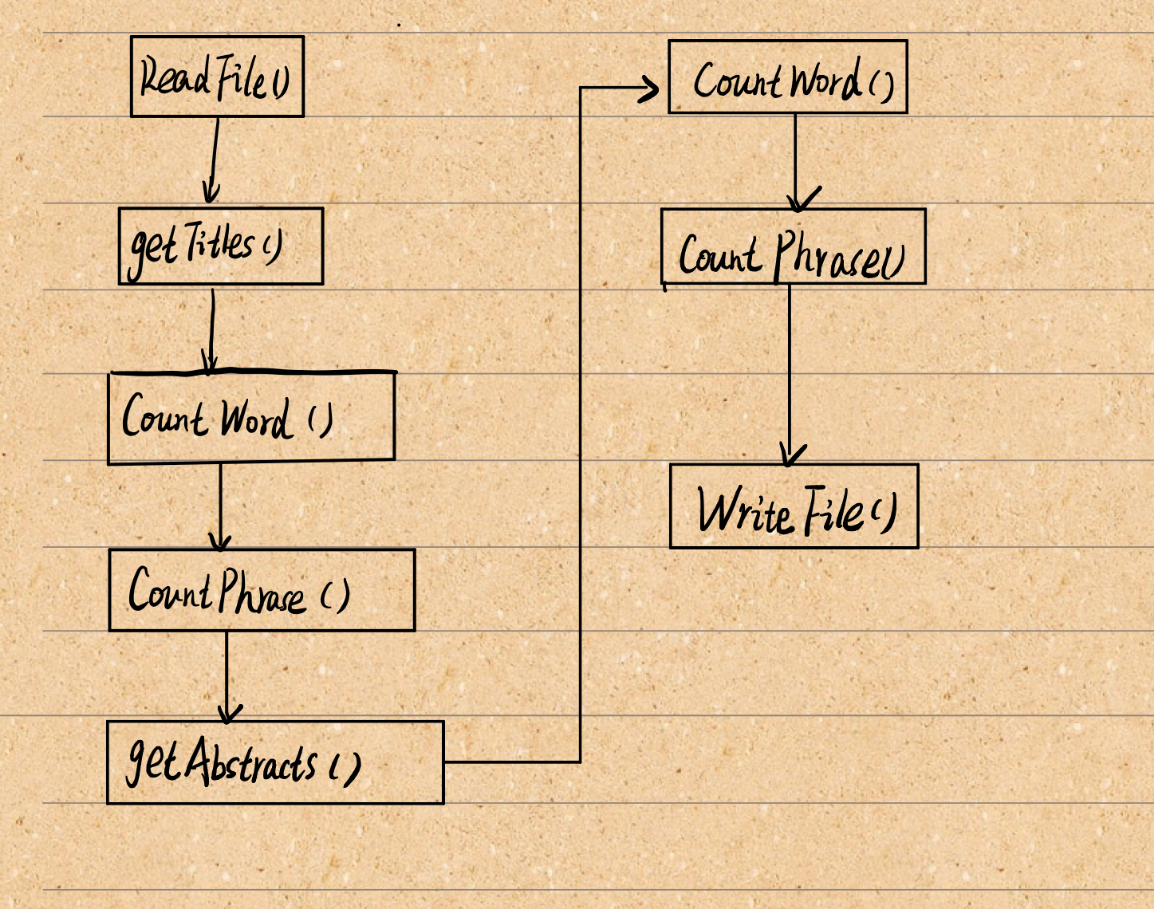
-
算法的关键以及关键实现部分流程图

4.性能分析
-
性能分析图


-
程序中消耗最大的函数
- CountPhrase(String text,int cwords,int wei)
5.代码说明
- LineCount()
- 遍历内容,使用flag标记,若遇到有效内容设置为true,若遇到 且flag为true则有效行数加1。
/**
* 统计有效行数
* @param text
* @return
*/
public int LineCount(String text){
int lines=0;
boolean flag = false;
for(int i=0;i<text.length();i++){
if(text.charAt(i)>' '){
flag=true;
}
else if(text.charAt(i)=='
'){
if(flag) {
lines++;
flag=false;
}
}
}
if(flag)
lines++;
return lines;
}
- WordCount()
- 将内容全部转换为小写字母,将内容中的单词分隔符全部替换为空格,在对其替换后内容进行分割,并遍历所有内容找寻有效单词put到map中并计数。
/**
* 词频统计
* @param text
* @return
*/
public int WordCount(String text){
int cpmount = 0;
//全部字母转小写
String textLow = text.toLowerCase();
//正则表达式,过滤非字母数字字符
String regex = "[^0-9a-zA-Z]";
//过滤文本
textLow = textLow.replaceAll(regex, " ");
//分割文本成单词
StringTokenizer words = new StringTokenizer(textLow);
try {
while (words.hasMoreTokens()) {
String word = words.nextToken();
//判断单词前4个是否为字母
if (word.length() >= 4 && Character.isLetter(word.charAt(0)) && Character.isLetter(word.charAt(1)) && Character.isLetter(word.charAt(2)) && Character.isLetter(word.charAt(3))) {
cpmount++;
if (!wordCount.containsKey(word)) {
wordCount.put(word, new Integer(1));
} else {
int count = wordCount.get(word) + 1;
wordCount.put(word, count);
}
}
}
}catch (Exception e){
//错误
}
return cpmount;
}
- CountWord()
- 将内容全部转换为小写字母,将内容中的单词分隔符全部替换为空格,在对其替换后内容进行分割。
- 遍历所有内容找寻有效单词put到map中并计数,这里会根据输入的权重来计数。
/**
* 统计单词数
* @param text
* @param wei ,当wei=1 权重为10 wei=0 权重为1
* @return 单词数量
*/
public int CountWord(String text,int wei){
int ant=0;
text = text.toLowerCase();
//分隔符集合
String regex = "[^0-9a-zA-Z]";
text = text.replaceAll(regex, " ");
//分割文本成单词
StringTokenizer words = new StringTokenizer(text);
try {
while (words.hasMoreTokens()) {
String word = words.nextToken();
if (word.length() >= 4 && Character.isLetter(word.charAt(0)) && Character.isLetter(word.charAt(1)) && Character.isLetter(word.charAt(2)) && Character.isLetter(word.charAt(3))) { //判断单词前4个是否为字母
ant++;
if (!wordCount.containsKey(word)) {
wordCount.put(word, new Integer(wei==1 ? 10:1));
} else {
int count = wordCount.get(word) + (wei==1 ? 10:1);
wordCount.put(word, count);
}
}
}
}catch (Exception e){
//错误
}
return ant;
}
- CountPhrase()
- 将内容全部转换为小写字母并替换换行符为空字符串,并使用分隔符将内容进行分割。
- 遍历所有内容寻找有效单词,当寻找的单词数量达到要求的词组数量后,取出原文中间的分隔符对词组进行拼接,然后put到map中统计数量,这里会根据输入的权重来计数。
/**
* 统计词组
* @param text
* @param cwords 词组的单词数
* @param wei ,当wei=1 权重为10 wei=0 权重为1
*/
public void CountPhrase(String text,int cwords,int wei){
text = text.toLowerCase();
text = text.replaceAll("
","");
StringBuilder mid=new StringBuilder();//分隔符
StringBuilder wword=new StringBuilder();//单词拼接
Queue<String> que1=new LinkedList<String>();//用于存储词组单词
Queue<String> que2=new LinkedList<String>();//用于存储分隔符
String feng=",./;'[] \<>?:"{}|`~!@#$%^&*()_+-=";//分隔符集合
StringTokenizer words = new StringTokenizer(text,feng,true); //分割文本成单词。
try {
while (words.hasMoreTokens()) {
String word =words.nextToken();
if (word.length() >= 4 && Character.isLetter(word.charAt(0)) && Character.isLetter(word.charAt(1)) && Character.isLetter(word.charAt(2)) && Character.isLetter(word.charAt(3))) { //判断单词前4个是否为字母
que2.offer(mid.toString());
mid.delete(0,mid.length());
que1.offer(word);
if(que1.size()>=cwords){//达到词组单词数量
int cnt=0;
wword.delete(0,wword.length());
for(String w:que1){
wword.append(w);
cnt++;
if(que2.size()>cnt)
{
String tmp=((LinkedList<String>) que2).get(cnt);//取出中间的分隔符
wword.append(tmp);//拼接
}
}
//最后生成正确的wword 词组
// 进行统计操作
if(!phraseCount.containsKey(wword.toString()))
{
phraseCount.put(wword.toString(),new Integer( wei==1 ? 10:1 ));
}
else{
int count=phraseCount.get(wword.toString()) + (wei==1 ? 10:1);
phraseCount.put(wword.toString(),count);
}
que1.remove();
que2.remove();
}
}
else if(word.length()!=1){//不符合条件 将其前面的都删除
que1.clear();
que2.clear();
}else if(word.length()==1 && !(Character.isLetter(word.charAt(0)))){//判断是否为分隔符
mid.append(word);
}
}
}catch (Exception e){
//出错
}
}
- sortList()
- 获取词组map,转换成一个list,自定义一个比较器对象,该对象可以根据map的value值进行排序,最后将list使用该比较器进行排序
/**
* 词频排序
* @return list
*/
public List<HashMap.Entry<String, Integer>> sortList(){
List<HashMap.Entry<String, Integer>> list = new ArrayList<>();
for(Map.Entry<String, Integer> entry : phraseCount.entrySet()){
list.add(entry);
}
Comparator<Map.Entry<String, Integer>> comp = new Comparator<Map.Entry<String, Integer>>(){
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if(o1.getValue().equals(o2.getValue()))
return o1.getKey().compareTo(o2.getKey()); //值相同 按键返回字典序
return o2.getValue()-o1.getValue();
}
//逆序(从大到小)排列,正序为“return o1.getValue()-o2.getValue"
};
list.sort(comp);
return list;
}
}
6.构建之法应用
-
学习到的相关内容
- 本次作业主要实践了《构建之法》第2章中的单元测试、效能分析等内容以及第4章中的结对编程的部分。在书中学习到单元测试的基本知识,例如如何创建单元测试,好的单元测试标准等等。另外,也学习到与队友沟通的几种方式,知道该如何正确地给予反馈给队友,在这些学习之后,我与队友的沟通顺利了不少,也越来越有默契。
-
困难及解决方法
- 最大的困难可能是一开始的需求理解产生分歧,以往实践课或者老师布置的作业并没有罗列详细的需求,而是告诉我们需要做一个什么东西,有几个需求。所以刚看到作业题目的时候,我们两个人不断地扣字眼,时间花费也超出预期。不过在学习使用书中的一些沟通方式技巧之后,两个人最后还是达成了一致,并且在结对编程中,因为有较明确的分工,编码时间比预期地更少了。
-
评价你的队友
- 值得学习的地方
- 最值得学习的地方可能是有责任感,不容易放弃。因为最近又要找实习又要参加比赛还有校赛要办,我本来的打算是好好地做完基本需求就可以了,但是,我的队友主动承担下来了进阶需求的大部分的代码编写,还提出想试试加个绘制图表的功能。“要做就做到最好。”他的话对我起到了鼓励作用,让我也坚持尽力一起把这个作业的进阶需求以及附加设计做完。而且在进阶需求部分有遇上一些小问题,他都一个个去解决了。要是我一个人做这个作业,我想我或许会放弃进阶部分。
- 需要改进的地方
- 可能需要多一点的细心。代码注释可以再多一点点。
7.附加题设计与展示
-
创意描述
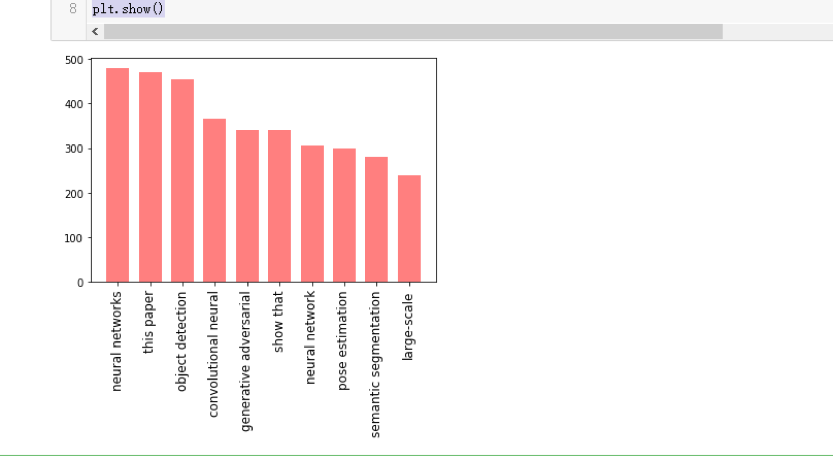
- 前段时间在学习Python的Matplotlib库时,学习到了一些可视化图表的绘制方法,灵机一动,发现为统计出来的词频绘制一个可视化的条形图图表不失为一个简单但是实用的小功能。(根据Java程序统计出来的Top10词频)
-
实现方法
- 根据java程序输出的top10词频,作为python程序的输入。利用Matplotlib绘制出词频条形图,使用户更直观地感受词频之间的对比。
-
主要代码
x = np.array(['neural networks','this paper','object detection','convolutional neural','generative adversarial','show that','neural network','pose estimation','semantic segmentation','large-scale'])
y = np.array([479,470,453,366,340,340,305,298,280,240])
plt.bar(x,y,0.7,alpha=0.5,color='r')
plt.xticks(rotation=90,fontsize=12)
plt.show()
- 实现成果展示