1、简介
机器学习的目的是通过对训练数据的训练,能够对未知的数据有很好的应用效果。
1.1 训练误差和测试误差
训练误差是模型对训练集的计算损失,测试误差是模型对测试集的计算损失,听起来好像是废话。举个栗子,一个数据集有100条,其中80条用来做训练集,20条用来做测试集,用模型对这80条数据进行训练,得到最终模型,用这个最终模型对80条数据进行测试,其中60个正确,20个错误,假设损失函数是0-1损失,那么训练误差就可以用20/80=0.25,对测试集进行测试,有10个正确,10个错误,则测试误差就是10/20=0.5。
1.2、过拟合与欠拟合
过拟合和欠拟合指示的是模型的泛化能力,过拟合是指模型由于过于复杂,经过训练,导致其在训练集效果上很好,但是在测试集效果很差。欠拟合就是指训练集和测试集效果都很差。
2、模型选择
2.1、正则化
正则化是指我们在损失函数的后面加入一个调整项,这个调整项本质上是防止模型陷入过拟合。

(lambda)表示调整两者的参数。
2.2、简单交叉验证
简单交叉验证就是指我们暴力的将数据集分成训练集和测试集,这里的比例我们自己可以定。
2.3、S折交叉验证
S折交叉验证表示我们将数据集分成S份,取其中S-1份进行训练,用留出的那一份进行测试,这样进行多次,算出每个模型的平均误差,选择误差最小的当作最终的模型。
2.4、自助方法
这种方法是我们每次取出数据集中的一条数据并放回,这样我们随机的取m次,用这些取出来的数据当作训练集,其余的当作测试集。这样某样本不会被抽到的概率是
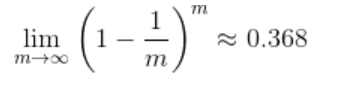
上面的数据集大小是m,一次没抽到的概率是(1-(1/m))进行m次,所以就是m次方。
3、模型评估
3.1、准确率和错误率
对于分类来讲,准确率就是对100条数据进行测试,90条正确,10条错误,则准确率是90%,错误率就是10%。准确率+错误率=1
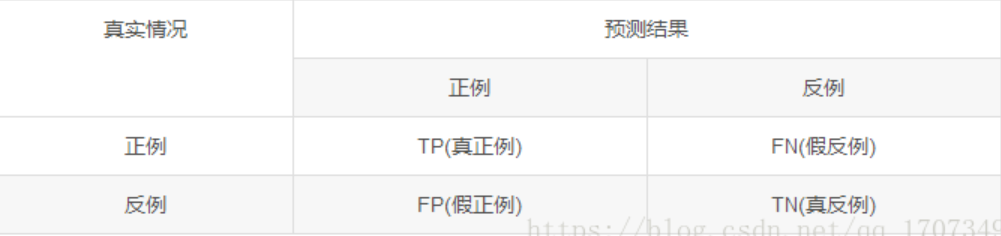
3.2、查准率,查全率,F1
这两个指标是针对二分类来说,同时,也可以将他们扩展到多分类,假设我们有正例60和负例40,其中有40个正例被预测为正例,20个正例被预测为负例,15个负例被预测为负例,25个负例被预测为正例,则查准率(P)=40/(40+25),查全率(R)=40/(40+20),由于这两者一般情况下不会同时增大,所以我们用F1值来进行度量,F1 = (2 * P * R)/ (P + R)
3.3、ROC和AUC
ROC曲线的横坐标是假正FP,纵坐标是真正TP,两者曲线的面积是AUC值。