近实时分析的场景
近实时分析 – 对变化中的数据?供快速分析能力
- 分析现实世界中正在发生的事件的能力,结合历史数据和实时流数据进行汇总分析、预测和明细查询
- 绝对实时和批量不可调和,"近实时" 的意思是这是人机交互中能感受的尺度(秒级),而不是机器自动处理的实时性量级(ns / us级)
- 数据价值从非结构化到结构化,分析从非范式到范式。SQL是结构化分析的最终手段,但是:
- 汇总分析(顺序扫?)与明细查询(随机扫描)
- 小数据量下都不是问题;但是放在海量数据下看,两种负载难以调和
- 海量数据和实时流窗口上的SQL引擎实现也完全不同
- 更接近实时Hadoop上是完全可行的,但是实时性要求会带来架构上的巨大变化
典型场景
需要同时支持顺序和随机读/写的应用场景
●在线交互式BI分析/决策辅助
○ 场景举例: 贷后风险实时监测,实时资产偏好视图,历史风险偏好趋势,市场监测
○ 应用类型: 需要准实时的同步插入/修改,同时汇总分析和单条查询
● 时间序列数据
○ 场景举例: 股市行情数据; 欺诈检测和预防; 风险监控;线上实时反欺诈
○ 应用类型:需要实时捕获流数据,同时结合已有的T+1数据进行汇总、分析和计算
● 机器日志数据分析
○ 场景举例: 台机监控、故障预警
○ 应用类型:需要过滤大量流数据,同时结合已有的T+1数据进行汇总、分析和计算
更实时的、交互式BI
传统数仓中增加实时汇总分析能力

物联网(IoT)产生的实时分析和预测
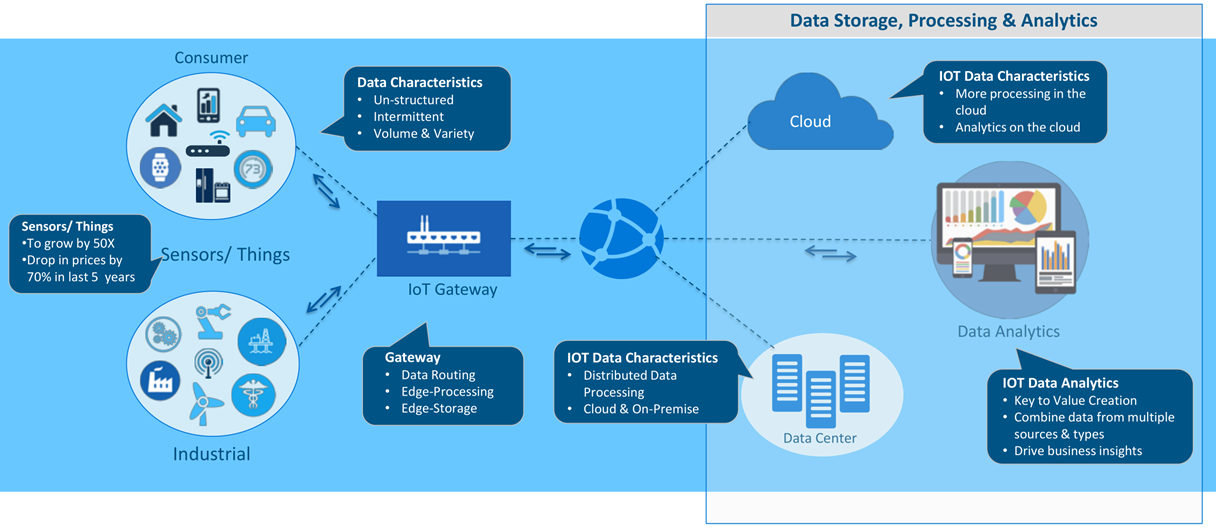
车联网
- 历史分析
- 开发人员希望知道如何优化充电性能
- 新版本软件升级后随着时间推移是如何影响汽车性能的?
- 实时洞察
- 客户希望知道是否是未成年人在驾驶。他们加速多快?
时速多少?他们在哪里?
- 汽车设备——比如在服务前或服务中拿到最新的诊断数据包
源于互联网的Lambda 架构
Lambda 架构
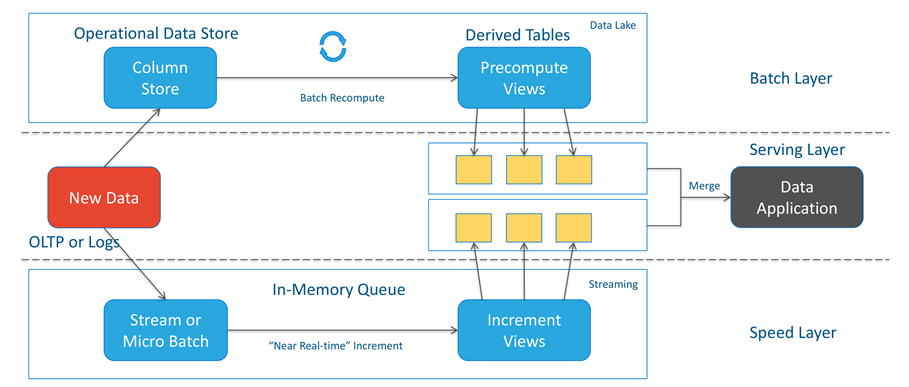
企业应用中Lambda的典型实现方式
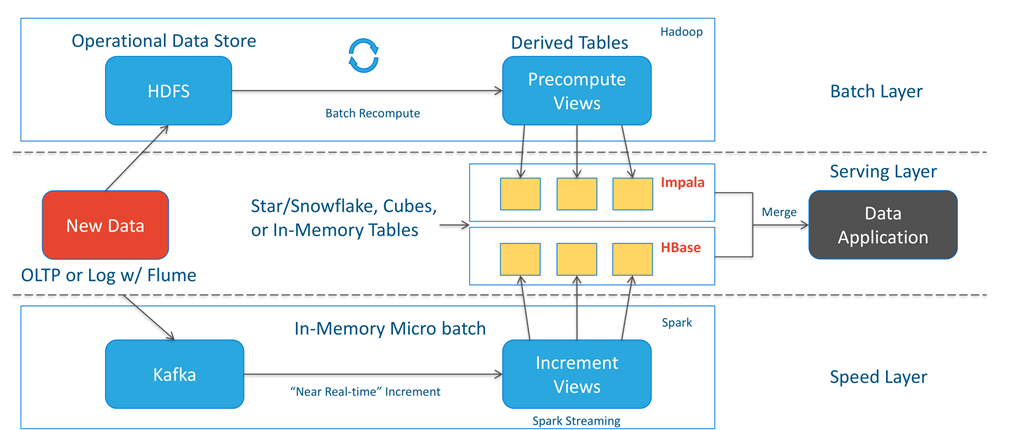
车联网的实时数据处理
Hbase Provides:
• Fast, Random Read & Write Access
• "Mini-scans"
• Scale-out architecture capable of serving Big Data to many users

车辆网历史数据分析方案
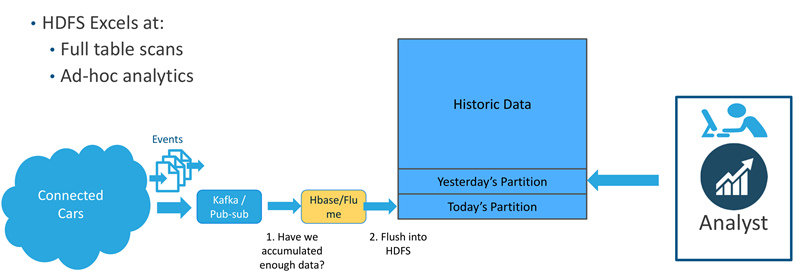
构建在混合架构上的分析管道

但是,HBase+HDFS混合架构的复杂性无处不在
同时供高性能的顺序扫?和随机查询,避免使用HBase+HDFS混合架构的复杂性:
• 开发:必须编写复杂的代码来管理两个系统之间的数据传输及同步
• 运维:必须管理跨多个不同系统的一致性备份、安全策略以及监控
• 业务:新数据从达到HBase到HDFS中有时延,不能马上供分析
在实际运行中,系统通常会遇到数据延时达到,因此需要对过去的数据进行修正等。如果使用不可更改的存储(如HDFS文件),将会非常不便。
Lambda 复杂性一:同步

Lambda 复杂性二:错误难以诊断
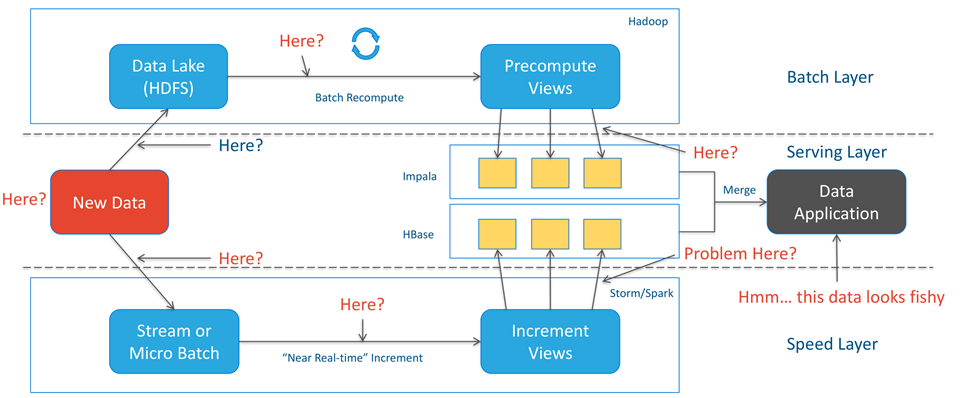
Lambda Pros & Cons
- Pros
• 成功将不同领域的开源框架嫁接到一个统
一架构内,应对不同类型的混合负载
• Batch Layer可应对数据的无限扩展
• Speed Layer可?供准实时的响应性能
- Cons - Complexity
• 需要大量的数据在不同存储和格式中迁移,造成维护困难
• 数据结构重新声明或者数据修改都很困难
• Batch Layer和Speed Layer需要维护两套代码,但其实现逻辑需要一致
• 意外错误的捕获、处理和冲正非常复杂
• 前端查询的复杂度非常大,需要合并数据集
基于Kudu实现简单的近实时分析
当前的欺诈检测架构:存储架构太复杂
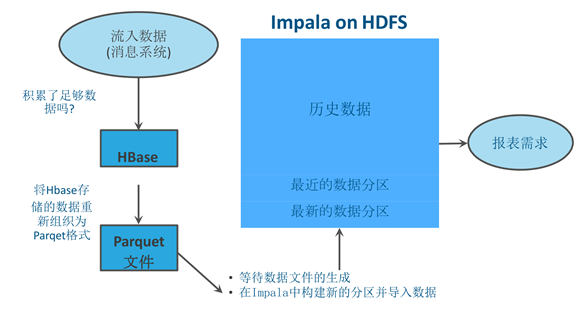
但是怎 样处理下面的问题 ?
● 怎么有效处理转换过程中的错误?
● 如何定义将HBase数据转换成Parquet格式作业的周期?
● 从数据进入到报表中能体现之间的时延如何量化?
● 作业流程怎么保障不被其他操作打断?
使用Kudu的Hadoop实时数据分析
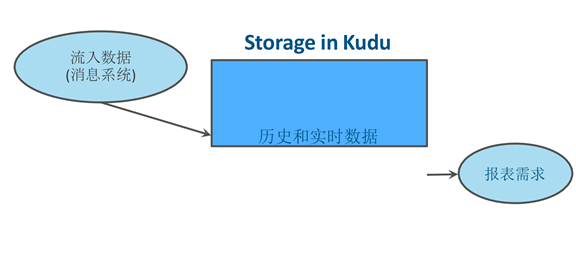
改进点 :
● 只要一套系 统
●不需要后台定 时的批处理任务
● 轻松应对数据迟到和数据修正
●新数据立即用于在分析和 业务运营
Kudu: 在快速变化的数据上进行快速分析
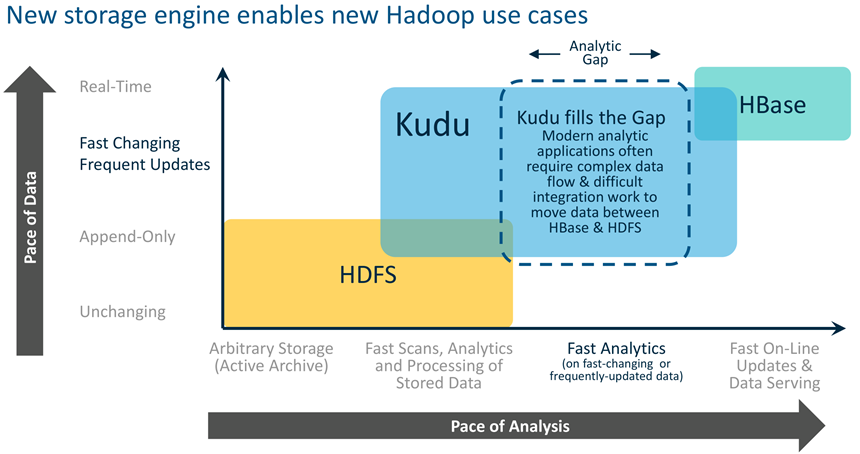
Kudu的设计目标
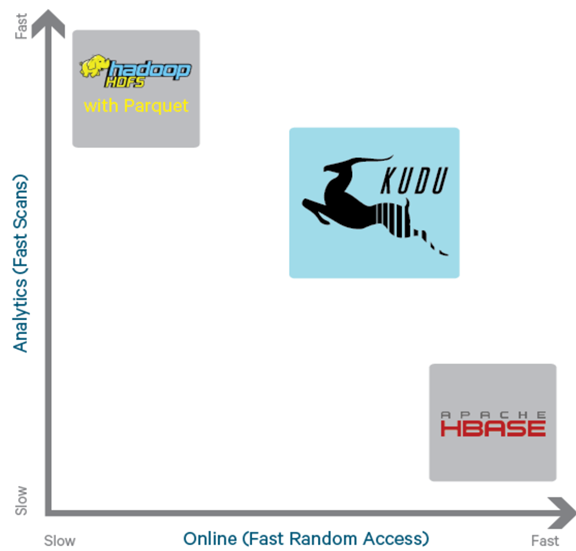
• 扫描大数据量时吞吐率 高(列式存储和多副本机制)
目标 : 相对Parquet的扫?性能差距在2x之内
• 访问少量数据时延时低(主键索引和多数占优复制机制)
目标 : SSD上读写延时不超过1毫秒
• 类似的数据库语义(初期支持单行记录的ACID)
• 关系数据模型
- SQL查询
- "NoSQL"风格的扫?/插入/更新(Java客户端)
Kudu的使用
类似SQL 模式的表
• 有限的列数 (不同于HBase/Cassandra)
• 数据类型: BOOL, INT8, INT16, INT32, INT64, FLOAT, DOUBLE, STRING, BINARY,TIMESTAMP
• 一部分列构成联合主键
• ALTER TABLE快速返回
"NoSQL" 风格的 Java和C++ APIs
• Insert(), Update(), Delete(), Upsert(), Scan()
与MapReduce, Spark 和Impala 的无缝对接
• 将对接更多处理引擎!
车辆网:一致的架构处理异构的数据分析管道

在CDH技术堆栈上的准实时分析技术
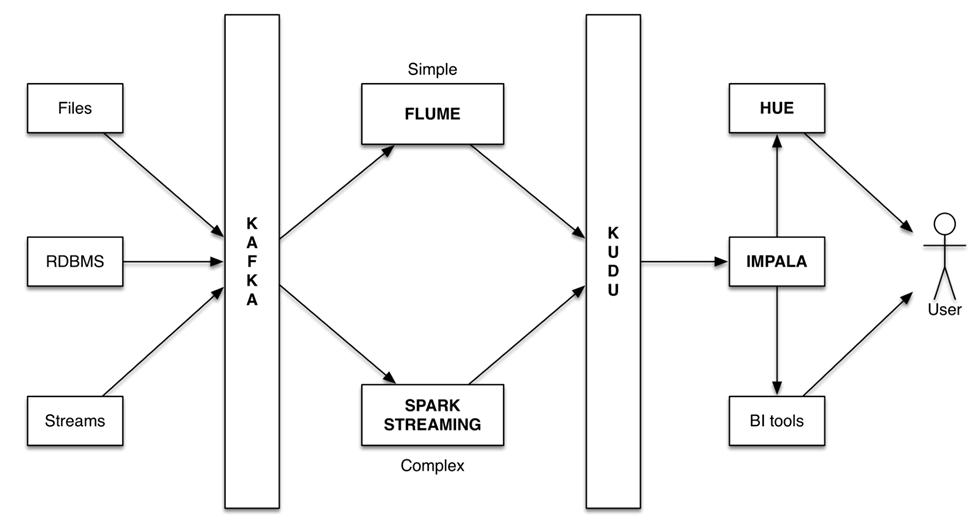
基于OGG 的数据库日志解析和Apache Kudu 的实时分析
•Kudu Adapter (Handler)帮助保持DB和Kudu之间基于日志解析的数据同步。
•使用OGG Java API将DB事务解码为kudu特定的事务。
•使用KUDU API在Kudu结束执行事务操作。
•Kudu Adapter (Handler) 支持数据的Inserts, Updates, Upsert 及Deletes 事务操作.
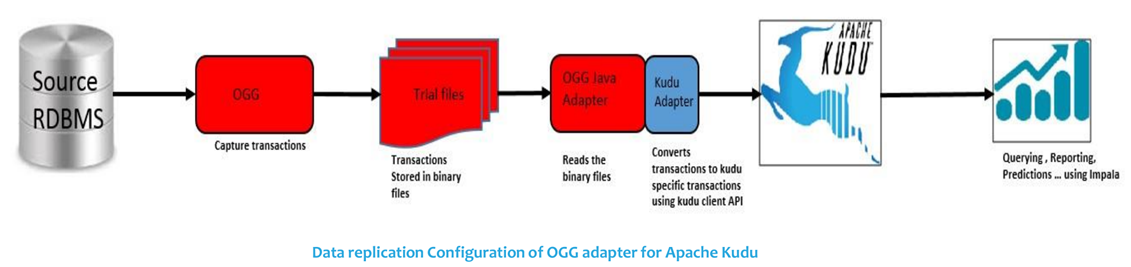
更通用的实时数据处理集成/分析架构
• 与Apache Spark Streaming 集成进行real-time 的数据分析
• 处理完的数据再接入Kafka进行进一步的处理和供下游系统进一步分析
使用案例分享
小米(MI) 简介

使用案例1
移动服务监听及跟踪工具
目标:
收集从移动App及后台服务发起的RPC程序调用重要的跟踪事件
服务监听及错误处理工具
需求:
- 高写吞吐
>50亿条/天的写能力,且持续增长
- 快速查询最新记录并做响应
快速定位错误并作出响应
- 能够确保单条记录快速查询
更容易进行差错
没有Kudu 之前大 数据分析处理
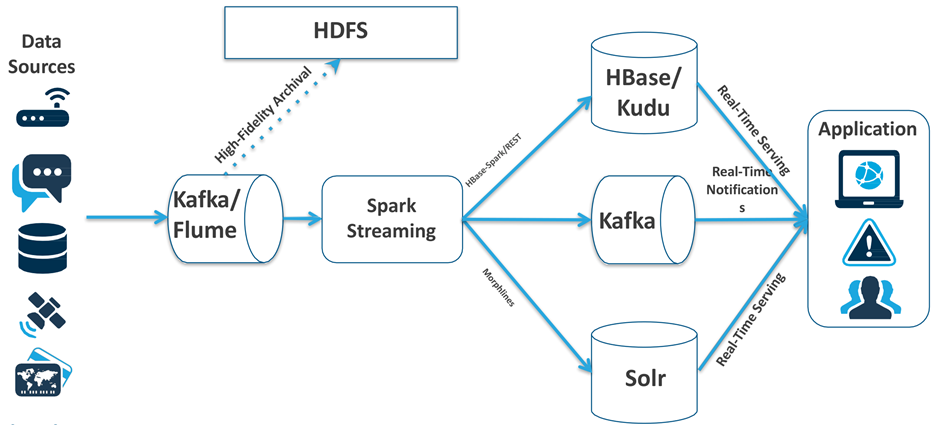
在kudu之前,我们的大数据分析pipeline大概是有这几种:
1. 数据源-> scribe打日志到HDFS -> MR/Hive/Spark -> HDFS
Parquet -> Impala -> 结果service这个数据流一般用来分析各种日志。
2. 数据源 -> 实时更新HBase/Mysql -> 每天批量导出Parquet->
Impala -> 结果serve这个数据流一般用来分析状态数据,也就是一般需要随机更新的数据,比如用户profile之类。
这两条数据流主要有几个问题:
- 数据从生成到能够被高效查询的列存储,整个数据流延迟比较大,一般是小时级别到一天;
- 很多数据的日志到达时间和逻辑时间是不一致的,一般存在一些随机延迟。
- 比如很多mobile app统计应用,这些tracing event发生后,很可能过一段时间才被后端tracing server收集到。我们经常看到一些hive查询,分 析一天或者一小时的数据,但是要读2-3天或者多个小时的日志,然后过滤出实际想要的记录。
- 对于一些实时分析需求,有一些可以通过流处理来解决,不过他肯定没用SQL方便,另外流式处理只能做固定的数据分析,对ad-hoc查询无能为力kudu的特点正好可以来配合impala搭建实时ad-hoc分析应用。
大数据分析管道- 因为Kudu
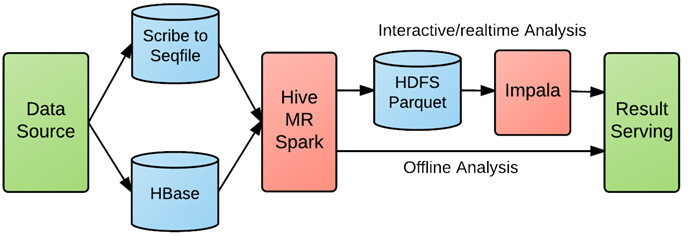
改进后的数据流大概是这个样子:
1. 数据源 -> kafka -> ETL(Storm) -> kudu -> Impala
2. 数据源 -> kudu -> Impala
3. 数据流1 主要是为需要进一步做ETL的应用使用的,另外kafka可以当做一个buffer,当写吞吐有毛刺时,kafka可以做一个缓冲。如果应用严格的实时需求,就是只要数据源写入就必须能够查到,就需要使用数据流2。
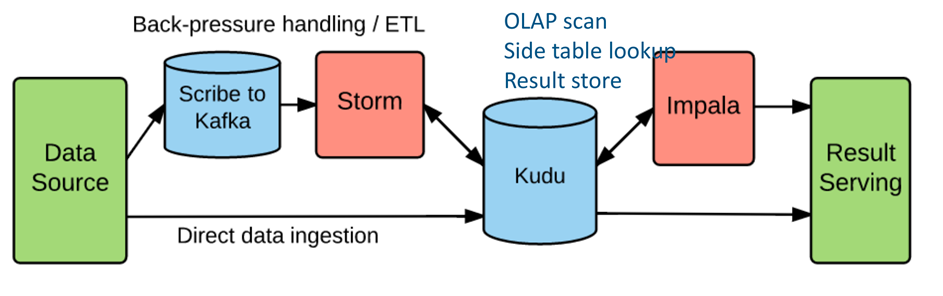
案例1: Benchmark
环境:
- 71 节点集群
- 硬件
CPU: E5-2620 2.1GHz * 24 core Memory: 64GB
Network: 1Gb Disk: 12 HDD
- 软件
Hadoop2.6/Impala 2.1/Kudu
数据:
1 天的服务器端跟踪数据
~26亿行记录
~270 bytes/行
每条记录17 字段, 5 关键字段
案例 1: Benchmark 结果
使用 impala 进行批加载 (INSERT INTO):

查询延时:
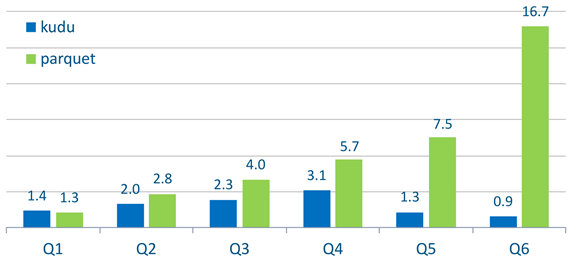
* HDFS parquet 文件复制因子= 3 , kudu 表复制因子= 3
*结果为每条查询执行5次并取平均值
案例2: 京东案例
Jd.com 中国第二大在线电商
- 使用Kafka实时收集数据
• 点击流日志
• 应用/浏览器Trace日志
• 每条记录约70字段
- 6/18 sale day
• 150亿笔交易
• 高峰期每秒一千万条数据插入
• 集群200台服务器
- 查询使用JDBC -> Impala -> Kudu
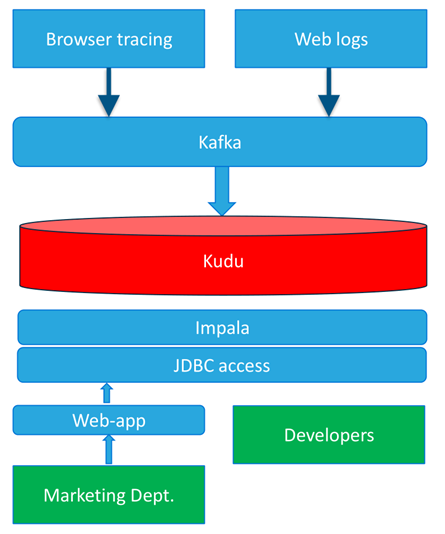
案例3 某互联网金融 使用 Kafka 、Spark 、Kudu 和Impala 构建

业务需求:
- 根据当前客户的操作行为进行风险等级实时分析,防范金融风险
架构说明:
- 数据源Stream API的数据由Kafka接入
- Spark Streaming消费Kafka数据,并注入到Kudu中
- 流数据接入Spark Streaming作业进行实时处理,并使用Mlib进行预测
- 预测的结果保存到Kudu
- 客户使用Impala或Spark SQL进行交互式结果查询
- 分析工具使用JDBC接口访问数据进行分析
案例4 某银行使用 Kafka 、Kudu 和Impala 实现准实时数据仓库应用
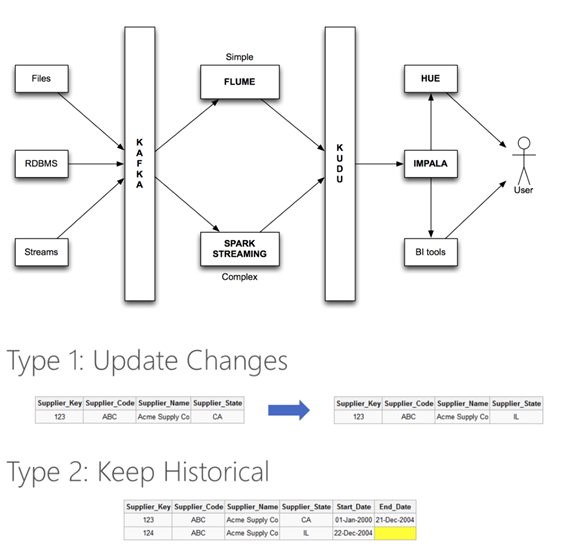
业务需求:
- 数仓应用建立在多维分析模型上,维度表需要根据需要保留历史记录
架构说明:
- 数据源Stream API的数据由Kafka接入到Spark Streaming或Flume,并保存到Kudu
- 通过Impala对维度数据进行SCD操作:
- SCD I: 存在即update
- SCD II: 存在则先insert一条新记录,并更新历史记录,如End Time 或 Flag
- 客户使用Impala进行交互式结果查询
- 分析工具使用JDBC接口访问数据进行分析
案例5 使用 Kafka、Kudu 和Impala实现准实时数据仓库分析应用
业务要求:
客户流式计算测试要求实现Hadoop产品从KAFKA快速加载数据,主要有2个应用场景:
• Append模式即简单将记录添加到数据表中,类似MySQL的insert into,并需要保证数据不重复。
• Insert_update模式即对于有主键的数据表,如果新的记录的主键在数据表中已存在,则用新的记录update旧的记录,如果新的记录的主键 在数据表中不存在,则将新的记录insert导数据表中。
设计实现思路:
1. 基于本次流式计算的测试要求,无论是Append还是Insert_update本来都可以通过使用HBase来实现,因为HBase的Rowkey可以保证数据的唯一性约束,达到Append去重的目的,而HBase的API也支持通过Rowkey去更新已经存在的数据。
2. 但是在本次流计算测试的性能场景要求中,还需要测试混合负载,需要进行数据集的统计查询,即在入库的同时需要进行大量的SQL统计分析查询,还包括join操作。这样HBase肯定无法满足,因为HBase只适合于随机插入以及简单的Rowkey条件查询。
所以我们最终选择了Kudu来完成,既可以满足快速的随机插入,包括去重和更新操作,同时支持并发的SQL查询的混合负载要求。
总体架构设计
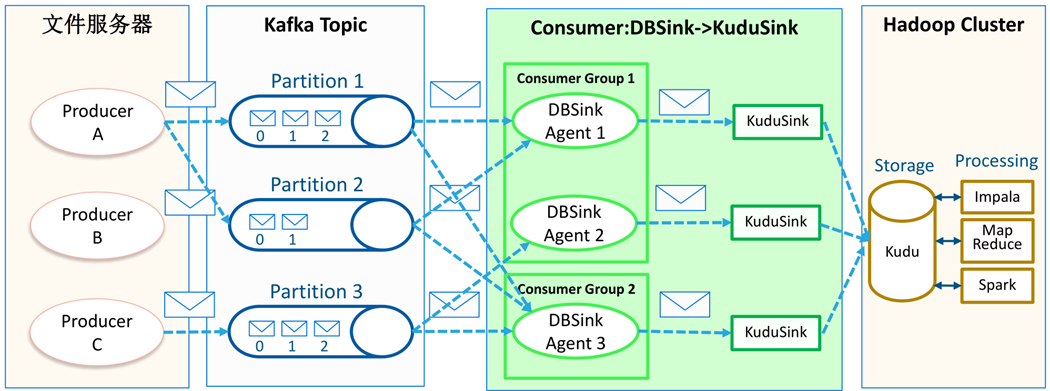
• Append:Kudu是用于存储结构化的表。表有预定义的带类型的列(Columns),每张表有一个主键(primary key)。主键带有唯一性(uniqueness)限制,可作为索引用来支持快速的随机查询。如果我们使用insert()方法,通过Kudu主键的唯一性,我们可以达到去重的目的,当有重复数据导入的时候,Kudu自身会通过主键判断,如果存在,则直接丢弃。
• Insert_update:Kudu源生提供了Upsert()方法,直接可以达到本次测试insert_update的目的,即根据主键判断,如果存在则更新该数据,否则则作为新的数据插入到Kudu
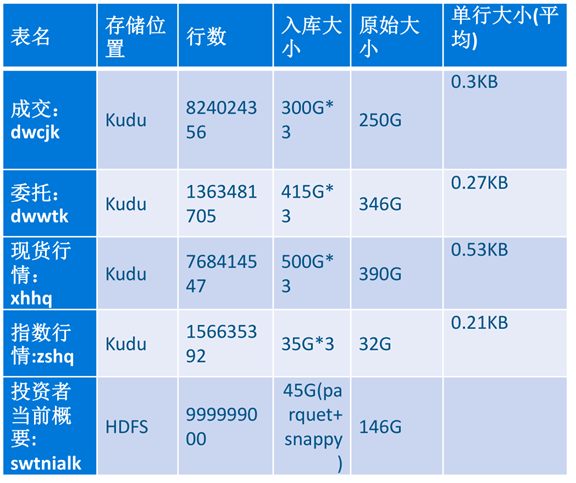
测试数据集及测试结果
本次测试主要用到了五个表:
HDFS中的表主要用来SQL混合负载的join表,并验证Impala跨存储执行性能。
Append,无重复
Upsert,去重

Upsert,去重时有SQL查询的混合负载

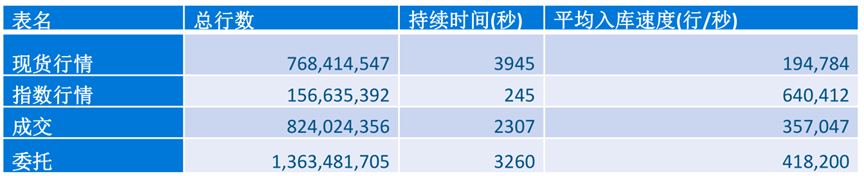
稳定的入库速度
0min-6min,
指数行情:63万条/秒,
现货行情:18万条/秒,
委托:40万条/秒,
成交:35万条/秒,
总的吞吐在:160万条/秒
案例6: 某车企的实时车辆网分析平台
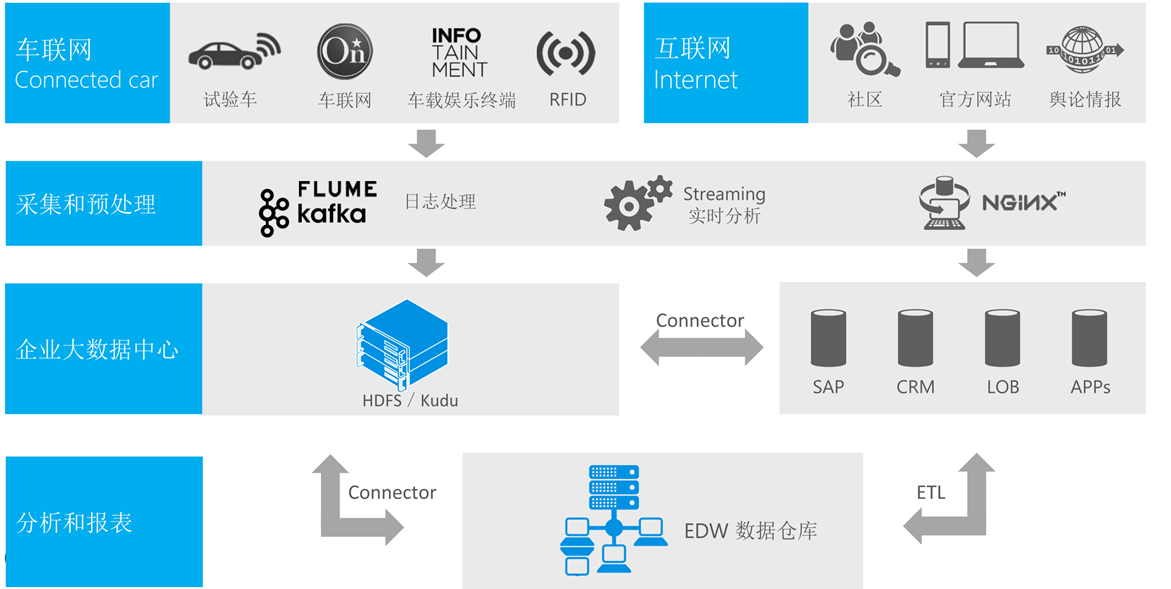
应用场景4:企业大数据中心 技术架构
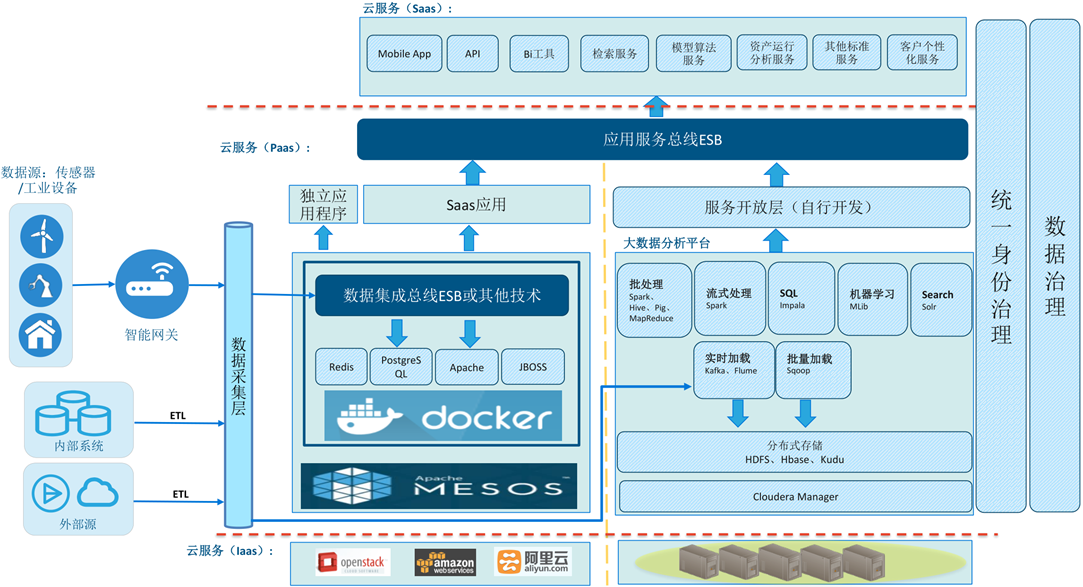
规划中的技术框架
性能基准测试
TPC-H (Analytics benchmark)
- 集群由75个TS 和一个master构成
• 每个节点12 块硬盘, 128GRAM
• Kudu 0.5.0+Impala 2.2+CDH 5.4
• TPC-H Scale Factor 100 (100GB)
- 分析语句举例(6表关联统计分析):
SELECT n_name, sum(l_extendedprice * (1 - l_discount)) as revenue FROM customer, orders, lineitem, supplier, nation, region WHERE c_custkey = o_custkey AND l_orderkey = o_orderkey AND l_suppkey = s_suppkey AND c_nationkey = s_nationkey AND s_nationkey = n_nationkey AND n_regionkey = r_regionkey AND r_name = 'ASIA' AND o_orderdate >= date '1994-01-01' AND o_orderdate < '1995-01-01' GROUP BY n_name ORDER BY revenue desc; |
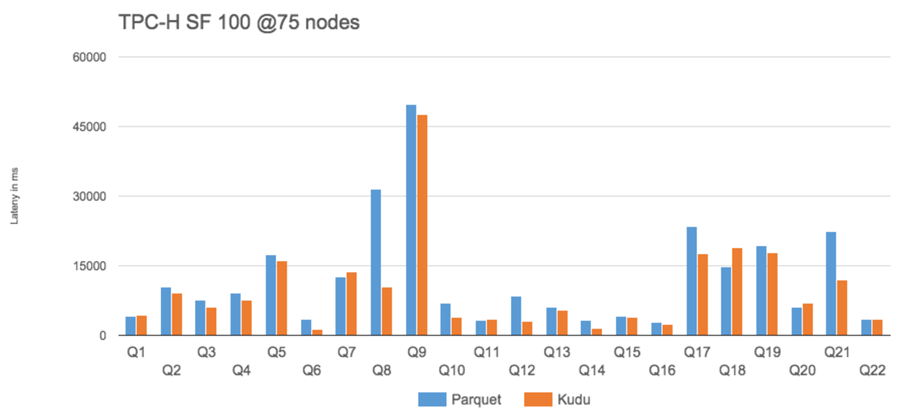
- 对内存数据,Kudu性能比Parquet高31% (几何平均)
- 对硬盘数据,Parquet性能应该比Kudu更好(larger IO requests)
Kudu vs Phoenix
• 10 节点集群 (9 worker, 1 master)
• HBase 1.0, Phoenix 4.3
• TPC-H LINEITEM 表(60亿行记录)
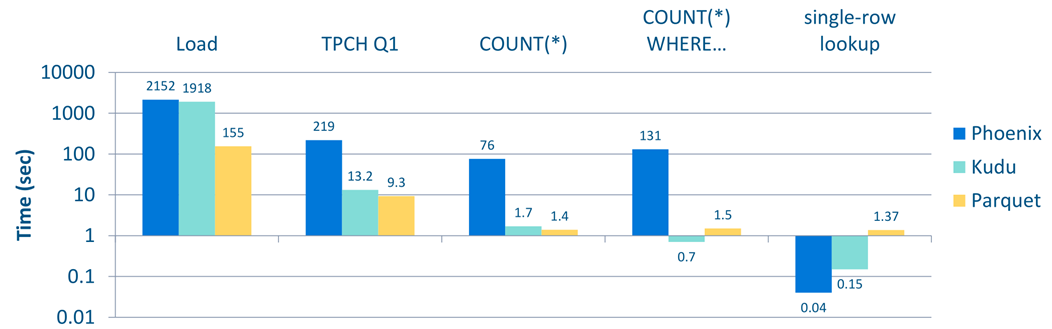
与NoSQL数据库PK随机查询性能 (YCSB)
• YCSB 0.5.0-snapshot
• 10 节点集群
(9 worker, 1 master)
• HBase 1.0
• 1亿条记录, 1千万 ops
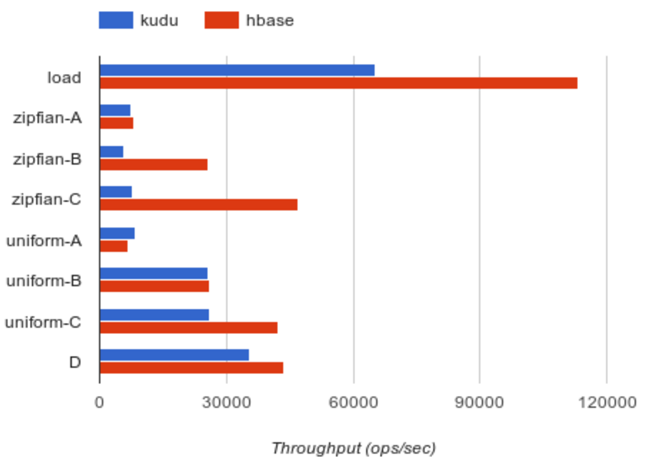
多用户并发查询下性能最好