1.一条update语句
1.先通过引擎找到对应的行数据,并加锁2.对行数据进行修改并调用引擎接口修改这条数据,然后释放锁(此时并没有把数据在磁盘上做出修改)3.redo log在内存中生成这条update的日志,通过innodb_flush_log_trx_commit 参数判断是否flush(持久化到磁盘),并告知mysql执行器完成操作4.执行器生成binlog并持久化到磁盘5.执行器调用引擎提交事务接口,redo log状态变为commit状态完成整个更新操作。2.redo log
redo log buffer:物理上是Mysql进程内存FSPage cache:写入磁盘但没有持久化,物理上是在文件系统page cache中hard disk 持久化到磁盘3.刷脏页
Mysql在记录redo log的时候会先将数据写入到内存中,然后通过flush将内存中的数据写入磁盘中。在此期间会产生脏数据页导致内存和磁盘的数据不一致。
这时候mysql就需要刷脏数据页。即是第一点的第六小点的动作:使用一个后台线程智能地刷新这些变更到数据文件
1.当记录redo log的内存满了,会停止写入redo log操作,然后进行刷脏页工作2.写入日志太多,发现分配的内存不够,这时候需要淘汰一部分数据页,坐刷脏页工作3.mysql空闲时会进行刷脏页工作
需要注意的是:
在flush过程中如果存在读入的数据页没有内存的时候,需要到缓冲池中申请数据页。当数据页不足首先将最久不使用的数据从内存中淘汰,如果是脏数据页还得先进行刷盘才能复用。
4. checkpoint (跟第二点的刷脏页对应)
1.缩短数据库的恢复时间;
2.缓冲池不够用时,将脏页刷新到磁盘;
3.重做日志不可用时,刷新脏页。
-
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。数据库只需对Checkpoint后的重做日志进行恢复,这样就大大缩短了恢复的时间。
-
当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
-
写入日志太多,发现分配的内存不够,这时候需要停止redo log写入然后淘汰一部分数据页,做刷脏页操作,然后移动checkpoint 位置
checkpoint 分为两类:
- Sharp Checkpoint
Sharp Checkpoint 发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,即参数innodb_fast_shutdown=1
但是若数据库在运行时也使用Sharp Checkpoint,那么数据库的可用性就会受到很大的影响。故在InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页,而不是刷新所有的脏页回磁盘。
- Fuzzy Checkpoint
1、Master Thread Checkpoint
以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,此时InnoDB存储引擎可以进行其他的操作,用户查询线程不会阻塞。
2、FLUSH_LRU_LIST Checkpoint
因为InnoDB存储引擎需要保证LRU列表中需要有差不多100个空闲页可供使用。在InnoDB1.1.x版本之前,需要检查LRU列表中是否有足够的可用空间操作发生在用户查询线程中,显然这会阻塞用户的查询操作。倘若没有100个可用空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除。如果这些页中有脏页,那么需要进行Checkpoint,而这些页是来自LRU列表的,因此称为FLUSH_LRU_LIST Checkpoint。
而从MySQL 5.6版本,也就是InnoDB1.2.x版本开始,这个检查被放在了一个单独的Page Cleaner线程中进行,并且用户可以通过参数innodb_lru_scan_depth控制LRU列表中可用页的数量,该值默认为1024,如:
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_lru_scan_depth | 1024 |
+-----------------------+-------+
Fuzzy Checkpoint生命周期如下:Innodb每次取最老的modified page(last checkpoint)对应的LSN,再将此脏页的LSN作为Checkpoint点记录到日志文件,意思就是“此LSN之前的LSN对应的日志和数据都已经flush到redo log。
当mysql crash的时候,Innodb扫描redo log,从last checkpoint开始apply redo log到磁盘,直到last checkpoint对应的LSN等于Log flushed up to对应的LSN,则恢复完成
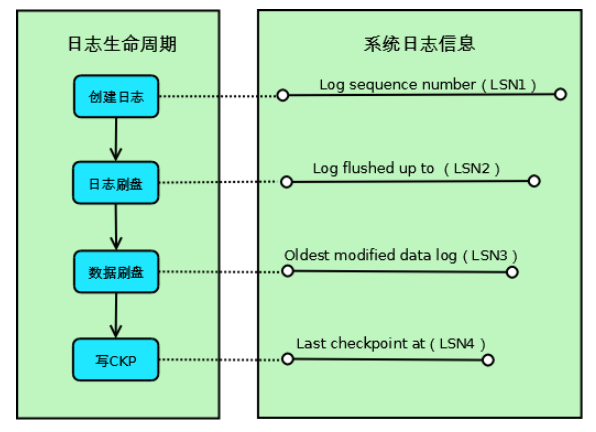
-
Log sequence number(LSN1):当前系统LSN最大值,新的事务日志LSN将在此基础上生成(LSN1+新日志的大小);
-
Log flushed up to(LSN2):当前已经写入日志文件的LSN;
-
Oldest modified data log(LSN3):当前最旧的脏页数据对应的LSN,写Checkpoint的时候直接将此LSN写入到日志文件;
-
Last checkpoint at(LSN4):当前已经写入Checkpoint的LSN;
如上图所示,Innodb的一条事务日志共经历4个阶段:
-
创建阶段:事务创建一条日志;
-
日志刷盘:日志写入到磁盘上的日志文件;
-
数据刷盘:日志对应的脏页数据写入到磁盘上的数据文件;
-
写CKP:日志被当作Checkpoint写入日志文件
3、Async/Sync Flush Checkpoint
指的是重做日志文件不可用的情况,这时需要强制将一些页刷新回磁盘,而此时脏页是从脏页列表中选取的。若将已经写入到重做日志的LSN记为redo_lsn,将已经刷新回磁盘最新页的LSN记为checkpoint_lsn,则可定义:
checkpoint_age = redo_lsn - checkpoint_lsn
再定义以下的变量:
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
若每个重做日志文件的大小为1GB,并且定义了两个重做日志文件,则重做日志文件的总大小为2GB。那么async_water_mark=1.5GB,sync_water_mark=1.8GB。则:
当checkpoint_age<async_water_mark时,不需要刷新任何脏页到磁盘;
当async_water_mark<checkpoint_age<sync_water_mark时触发Async Flush,从Flush列表中刷新足够的脏页回磁盘,使得刷新后满足checkpoint_age<async_water_mark;
checkpoint_age>sync_water_mark这种情况一般很少发生,除非设置的重做日志文件太小,并且在进行类似LOAD DATA的BULK INSERT操作。此时触发Sync Flush操作,从Flush列表中刷新足够的脏页回磁盘,使得刷新后满足checkpoint_age<async_water_mark
5.WAL
WAL机制(Write-Ahead-Logging),主要讲了数据在操作的时候先进行写日志,然后再将数据写入磁盘的过程
6.binlog
事务提交时,执行器将binlog cache完整事务写入binlog中,并清空binlog cache。
整个写入过程分为两步 write和fsync
write:指把日志写入到文件系统page cache,并没有写入磁盘中,速度快fsync:将数据持久化到磁盘,该过程占用磁盘IOPS。7.事务两阶段提交
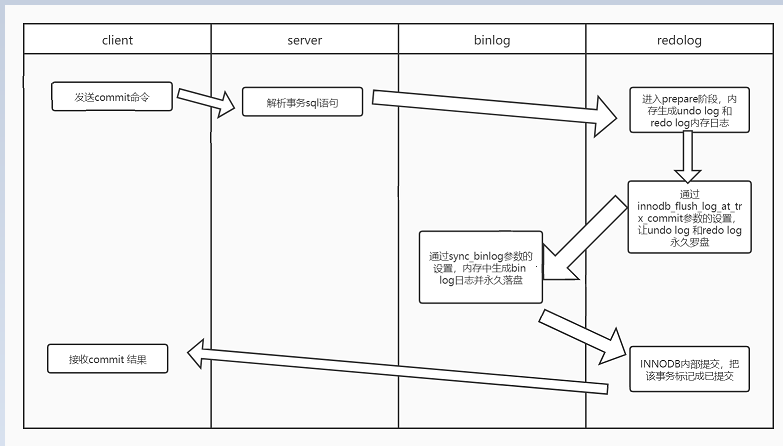
1.Storage Engine(InnoDB) transaction prepare阶段:存储引擎的准备阶段,写redo-buffer然后根据参数罗盘redo log
2.Binary log日志提交:写binlog并落盘.
3.Storage Engine(InnoDB)内部提交把事务状态标记为已提交
8.Crash recovery
如果数据库异常后宕机重启后会通过Crash recovery来恢复
sync_binlog=1 和 innoDB_flush_log_at_trx_commit = 1 称之为双1
双1模式可以保证提交后的事务不会丢失,即crash-safe。
在做Crash recovery时:分为以下3种情况
- binlog有记录,redolog状态commit:正常完成的事务,不需要恢复;
- binlog有记录,redolog状态prepare:在binlog写完提交事务之前的crash,恢复操作:提交事务。(因为之前没有提交)
- binlog无记录,redolog状态prepare:在binlog写完之前的crash,恢复操作:回滚事务(因为crash时并没有成功写入数据库)
9.组提交
mysql 5.7开始默认开启组提交。
1. 要保证顺序必须是提交加入到队列的顺序(binlog_order_commits保证)。
2. 如果有新的事务提交,此时队列为空,则可以加入到FLUSH队列中。不过,因为此时FLUSH临界区正在被占用,所以新事务组必须要等待。
3. 给每个事务分配sequence_number,如果是第一个事务,则将这个组的last_committed设置为sequence_number-1.
4. 将带着last_committed与sequence_number的GTID事件FLUSH到Binlog文件中。
5. 将当前事务所产生的Binlog内容FLUSH到Binlog文件中。
组提交之redo log
多个同时处于prepare阶段的事务生成各自的redo log 会一起刷盘。假设2WTPS,并不需要4W次刷盘。也会在binlog中生成相同的last_commited(表示事务提交的时候,上次事务提交的编号).这些事务称之为1个事务组。
其实每一个组的last_committed值,都是上一个组中事务的sequence_number最大值,也是本组中事务sequence_number最小值减1。同时这两个值的有效作用域都在文件内,只要换一个文件(flush binary logs),这两个值就都会从0开始计数。上述的last_committed和sequence_number代表的就是所谓的LOGICAL_CLOCK
组提交之binlog
为了增加一组事务中的事务数量,提高刷盘收益,MySQL使用两个参数控制获取队列事务组的时机:
binlog_group_commit_sync_delay=N:在等待N μs后,开始事务刷盘(图中Sync binlog)
binlog_group_commit_sync_no_delay_count=N:如果队列中的事务数达到N个,就忽视binlog_group_commit_sync_delay的设置,直接开始刷盘(图中Sync binlog)
组提交可以有效减低iops。 尽管上面两个参数都关闭,也会开启组提交。因为redo log组提交不由这两个参数控制。
10. 并行复制
MySQL 5.7的并行复制基于一个前提,即所有已经处于prepare阶段的事务,都是可以并行提交的。这些当然也可以在从库中并行提交,因为处理这个阶段的事务,都是没有冲突的,该获取的资源都已经获取了。反过来说,如果有冲突,则后来的会等已经获取资源的事务完成之后才能继续,故而不会进入prepare阶段。
一个组提交(group commit)的事务都是可以并行回放,因为这些事务都已进入到事务的prepare阶段,则说明事务之间没有任何冲突(否则就不可能提交)。
- binlog_order_commits会影响提交行为。如果设置为ON,那么此时提交就变为串行操作了,就以队列的顺序为提交顺序。而这也是LOGICAL_CLOCK并行复制的基础。因为order commit使得所有的事务分了组,并且有了序列号,从库拿到这些信息之后,就可以根据序号放心大胆地做分发了。
- slave_parallel_workers 从库并行复制得线程数
- slave_parallel_type: logical_clock 表示以事务组提交的方式并行复制。database 表示以不同database的方式并行复制