Batched Key Access Join
Index Nested-Loop Join虽好,但是通过辅助索引进行链接后需要回表,这里需要大量的随机I/O操作。若能优化随机I/O,那么就能极大的提升Join的性能。为此,MySQL 5.6推出了Batched Key Access Join,该算法通过常见的空间换时间,随机I/O转顺序I/O,以此来极大的提升Join的性能。
MRR
在说明Batched Key Access Join前,首先介绍下MySQL 5.6的新特性mrr——multi range read。这个特性根据rowid顺序地,批量地读取记录,从而提升数据库的整体性能。看下面的SQL语句的执行计划:
mysql> explain select * from orders
-> where o_orderdate >= '1993-08-01'
-> and o_orderdate < date_add( '1993-08-01' ,interval '3' month)G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: range
possible_keys: i_o_orderdate
key: i_o_orderdate
key_len: 4
ref: NULL
rows: 143210
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
上述的SQL语句需要根据辅助索引i_o_orderdate进行查询,但是由于要求得到的是表中所有的列,因此需要回表进行读取。而这里就可能伴随着大量的随机I/O。这个过程如下图所示:
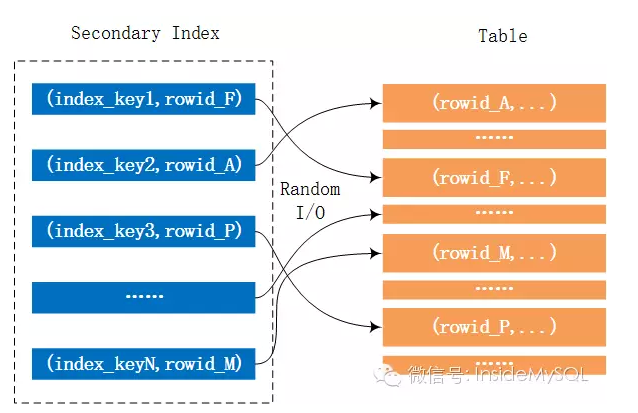
而mrr的优化在于,并不是每次通过辅助索引读取到数据就回表去取记录,而是将其rowid给缓存起来,然后对rowid进行排序后,再去访问记录,这样就能将随机I/O转化为顺序I/O,从而大幅地提升性能。这个过程如下所示:
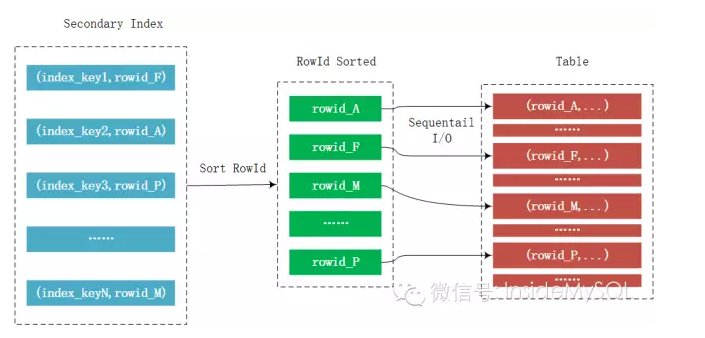
从上图可以发现mrr通过一个额外的内存来对rowid进行排序,然后再顺序地,批量地访问表。这个进行rowid排序的内存大小由参数read_rnd_buffer_size控制,默认256K。
要开启mrr还有一个比较重的参数是在变量optimizer_switch中的mrr和mrr_cost_based选项。mrr选项默认为on,mrr_cost_based选项默认为off。mrr_cost_based选项表示通过基于成本的算法来确定是否需要开启mrr特性。然而,在MySQL当前版本中,基于成本的算法过于保守,导致大部分情况下优化器都不会选择mrr特性。为了确保优化器使用mrr特性,请执行下面的SQL语句:
mysql>set optimizer_switch='mrr=on,mrr_cost_based=off';
同样执行前面的SQL语句,可以发现这时优化的执行计划为:
mysql> explain select * from orders where
-> o_orderdate >= '1993-08-01'
-> and o_orderdate < date_add('1993-08-01' ,interval '3' month)G
*************************** 1. row***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: range
possible_keys: i_o_orderdate
key: i_o_orderdate
key_len: 4
ref: NULL
rows: 143210
filtered: 100.00
Extra: Using index condition; Using MRR
1row in set, 1 warning (0.00 sec)
最后来对比一下关闭和开启mrr特性后上述SQL的执行时间:

在讲述完mrr特性后,再来看BKA Join就非常清晰明了了。通过mrr特性优化Join的回表操作,从而提升Join的性能。这时BKA Join的整个过程如下所示:

然而,这么好的特性,却是在MySQL中默认关闭的!!!这可能是导致用户认为MySQL Join性能比较差的一个原因。若要使用BKA Join,务必执行下列的SQL语句:
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
Query OK, 0 rows affected (0.00 sec)
若开启了BKA Join,则通过EXPLAIN命令,可以发现优化器的执行结果选项会有Using join buffer (Batched Key Access)的提示,如:
mysql> explain SELECT
-> COUNT(*)
-> FROM
-> part,
-> lineitem
-> WHERE
-> l_partkey, = p_partkey
-> AND p_retailprice > 2050 AND p_size < 100
-> AND l_discount > 0.04G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: part
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 196810
filtered: 11.11
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ref
possible_keys: i_l_suppkey_partkey,i_l_partkey
key: i_l_suppkey_partkey
key_len: 5
ref: dbt3_s1.part.p_partkey
rows: 28
filtered: 33.33
Extra: Using where; Using join buffer (Batched Key Access)
2 rows in set, 1 warning (0.00 sec)
最后来看下执行速度,可以发现BKA的提升非常明显:

未完待续