本文主要是利用scrapy框架爬取果壳问答中热门问答, 精彩问答的相关信息
环境
win8, python3.7, pycharm
正文
1. 创建scrapy项目文件
在cmd命令行中任意目录下执行以下代码, 即可在该目录下创建GuoKeWenDa项目文件
scrapy startproject GuoKeWenDa
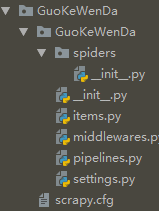
2. 创建爬虫主程序
在cmd中切换到GuoKeWenDa目录下, 执行以下代码:
cd GuoKeWenDa
scrapy genspider GuoKeWenDaSpider GuoKeWenDaSpider.toscrape.com
创建GuoKeWenDaSpider.py文件成功
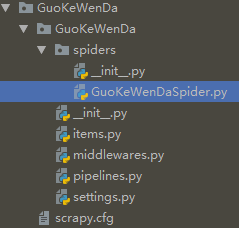
3. 定义要爬取的项目
分析果壳热门问答和果壳精彩问答, 发现两页面的结构一致, 我们爬取其中的主题, 简介, 关注数, 回答数, 标签, 文章链接等6个信息
在items.py中定义
1 import scrapy 2 from scrapy.item import Item, Field 3 4 class GuokewendaItem(Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 title = Field() 8 intro = Field() 9 attention = Field() 10 answer = Field() 11 label = Field() 12 link = Field()
4. 编写爬虫主程序
在GuoKeWenDaSpider.py文件中编写:
1 import scrapy 2 from scrapy.spiders import CrawlSpider 3 from scrapy.selector import Selector 4 from scrapy.http import Request 5 from GuoKeWenDa.items import GuokewendaItem 6 7 class GuoKeWenDa(CrawlSpider): 8 name = 'GuoKeWenDa' 9 allowed_domains = ['GuoKeWenDaSpider.toscrape.com'] 10 urls = ['hottest', 'highlight'] 11 #对urls进行遍历 12 start_urls = ['https://www.guokr.com/ask/{0}/?page={1}'.format(str(m),str(n)) for m in urls for n in range(1, 101)] 13 def parse(self, response): 14 item = GuokewendaItem() 15 #初始化源码 16 selector = Selector(response) 17 #用xpath进行解析 18 infos = selector.xpath('//ul[@class="ask-list-cp"]/li') 19 for info in infos: 20 title = info.xpath('div[2]/h2/a/text()').extract()[0].strip() 21 intro = info.xpath('div[2]/p/text()').extract()[0].strip() 22 attention = info.xpath('div[1]/p[1]/span/text()').extract()[0] 23 answer = info.xpath('div[1]/p[2]/span/text()').extract()[0] 24 labels = info.xpath('div[2]/div/p/a/text()').extract() 25 link = info.xpath('div[2]/h2/a/@href').extract()[0] 26 if labels: 27 label = " ".join(labels) #用join将列表转成以" "分隔的字符串 28 else: 29 label ='' 30 item['title'] = title 31 item['intro'] = intro 32 item['attention'] = attention 33 item['answer'] = answer 34 item['label'] = label 35 item['link'] = link 36 yield item
5. 保存到MongoDB
import pymongo class GuokewendaPipeline(object): def __init__(self): '''连接MongoDB''' client = pymongo.MongoClient(host='localhost') db = client['test'] guokewenda = db['guokewenda'] self.post= guokewenda def process_item(self, item, spider): '''写入MongoDB''' info = dict(item) self.post.insert(info) return item
6. 配置setting
在原有代码中去掉以下代码的注释 (快捷键"Ctrl" + "/")
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' DOWNLOAD_DELAY = 5 DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } ITEM_PIPELINES = { 'GuoKeWenDa.pipelines.GuokewendaPipeline': 300, }
7. 新建main.py文件
在GuoKeWenDa文件目录下新建main.py文件, 编辑:
1 from scrapy import cmdline 2 cmdline.execute('scrapy crawl GuoKeWenDa'.split())
执行main.py文件
8. 爬取结果

总结
实际中热门问答只有2页, 因此遍历它的第3到100页就显得太多余:
urls = ['hottest', 'highlight'] start_urls = ['https://www.guokr.com/ask/{0}/?page={1}'.format(str(m),str(n)) for m in urls for n in range(1, 101)]
可利用"+"连接两个url(参考: https://www.jianshu.com/p/9006ddca23b6), 修改为:
start_urls = ['https://www.guokr.com/ask/hottest/?page={}'.format(str(m)) for m in range(1,3)] + ['https://www.guokr.com/ask/highlight/?page={}'.format(n) for n in range(1,101)]