深度学习中的概率知识详解
1. 基础概念
随机变量(连续,离散): 对可能状态的描述, 在机器学习算法中,每个样本的特征取值,标签值都可以看作是一个随机变量,包括离散型随机变量和连续型随机变量
概率分布: 用来指定每个状态的可能性, 对于离散型的概率分布,称为概率质量函数(Probability Mass Function, PMF),对于连续性的变量,其概率分布叫做概率密度函数(Probability Density Function, PDF).
边缘概率分布:如果我们知道了一组变量的联合概率分布,但想要了解其中一个子集的概率分布,这个子集的概率分布称为边缘概率分布
联合概率分布:两个或两个以上随机随机变量联合地概率分布情况。
相互独立: 如果∀x∈X,y∈Y,P(X=x,Y=y)=P(X=x)P(Y=y)∀x∈X,y∈Y,P(X=x,Y=y)=P(X=x)P(Y=y)
,那么就称随机变量X和Y是相互独立的。
条件独立: 如果∀x∈X,y∈Y,z∈Z,P(X=x,Y=y∥Z=z)=P(X=x∥Z=z)P(Y=y∥Z=z)∀x∈X,y∈Y,z∈Z,P(X=x,Y=y‖Z=z)=P(X=x‖Z=z)P(Y=y‖Z=z)
,那么就称随机变量X和Y是关于Z相互独立的。
贝叶斯准则: 在已知P(y∥x)P(y‖x)
和P(x)P(x)
的情况下,P(x∥y)=P(x)P(y∥x)P(y)P(x‖y)=P(x)P(y‖x)P(y)
,贝叶斯准则经常被用在已知参数的先验分布情况下求后验分布。
期望: 函数f(x)f(x)
在某个分布P(x)P(x)
下的平均表现情况,记为Ex∼P[f(x)]=∫p(x)f(x)dxEx∼P[f(x)]=∫p(x)f(x)dx
。
方差: 函数f(x)f(x)
在某个分不下表现的差异性,记为Var(f(x)=E[(f(x)−E[f(x)])2]Var(f(x)=E[(f(x)−E[f(x)])2]
。
协方差: 两个变量之间线性相关的强度,记为Cov(f(x),g(x))=E[(f(x)−E[f(x)])(g(x)−E(g(x)))]Cov(f(x),g(x))=E[(f(x)−E[f(x)])(g(x)−E(g(x)))]
。
条件概率: 求B条件下, A发生的概率:
条件概率的链式法则:
信息熵: 描述某个概率分布中不确定性的度量,记为H(x)=−Ex∼P[logP(x)]H(x)=−Ex∼P[logP(x)] 。
交叉熵: 描述两个概率分布之间相似度的一个指标,在机器学习中经常使用交叉熵作为分类任务的损失函数,记为H(P,Q)=−Ex∼P[logQ(x)]H(P,Q)=−Ex∼P[logQ(x)] 。
2. 期望,方差,协方差
期望反应函数f(x)f(x) 的平均值. 设Ex p[f(x)]Ex p[f(x)] 是函数f(x)f(x) 关于某分布P(x)P(x) 的期望:
-
对于离散型随机变量:
Ex p[f(x)]=∑xP(x)f(x)Ex p[f(x)]=∑xP(x)f(x) -
对于连续性随机变量:
Ex p[f(x)]=∫p(x)f(x)dxEx p[f(x)]=∫p(x)f(x)dx
通常在概率上下文中可以不写脚标: E[f(x)]E[f(x)] , 更一般地, 当没有歧义时可以省略方括号, 将期望简写为EE .
期望是线性的:
方差衡量x依它的概率分布采样时, 随机变量x的函数f(x)f(x)
差异程度. 方差的定义:
协方差给出两个变量的线性相关度及这些变量的尺度. 协方差定义:
相关系数ρxyρxy
关于协方差的特性:
- 若协方差绝对值很大, 则变量值得变化很大, 且相距各自均值很远
- 若协方差为正, 则两变量x,y都倾向于取较大值, 若协方差为负, 则一个倾向于取较大值,另一个倾向取较小值
相关系数: 将每个变量归一化, 之衡量变量间的相关性, 不关注变量尺度大小.
3. 常用的概率分布模型
Bernoulli分布和Multinoulli分布
Bernoulli分布是单个二值随机变量分布, 单参数ϕ∈[0,1]ϕ∈[0,1]
控制,ϕϕ
给出随机变量等于1的概率. 一些性质:
概率:
方差,期望:
Multinoulli分布也叫范畴分布, 是单个kk
值随机分布,经常用来表示对象分类的分布.
, 其中kk
是有限值.Multinoulli分布由向量p⃗ ∈[0,1]k−1p→∈[0,1]k−1
参数化,每个分量pipi
表示第i个状态的概率, 且pk=1−1Tppk=1−1Tp
.
适用范围: 伯努利分布适合对离散型随机变量建模, 注意下述狄拉克δδ 函数适用对连续性随机变量的经验分布建模.
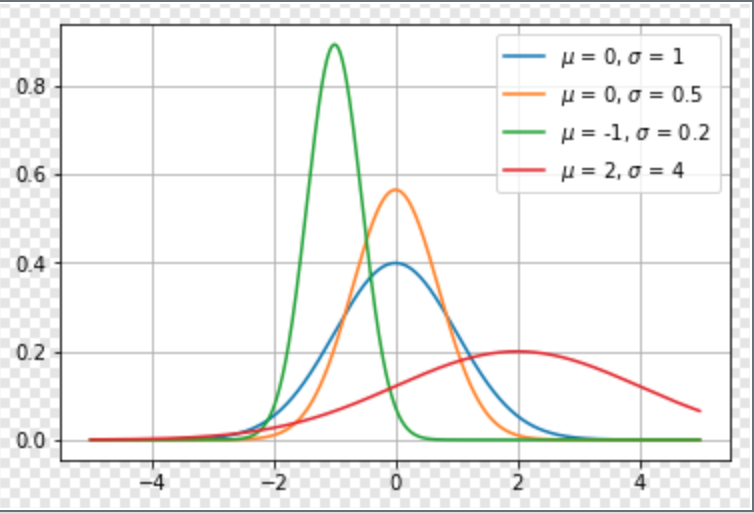
高斯分布
高斯也叫正态分布(Normal Distribution), 概率度函数如下:
其中, μμ 和σσ 分别是均值和方差, 中心峰值x坐标由μμ 给出, 峰的宽度受σσ 控制, 最大点在x=μx=μ 处取得, 拐点为x=μ±σx=μ±σ .
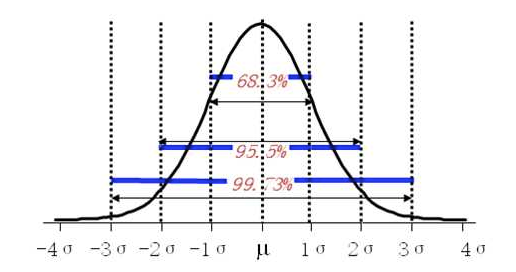
正态分布中,±1σ、±2σ、±3σ下的概率分别是68.3%、95.5%、99.73%,这3个数最好记住。
此外, 令μ=0,σ=1μ=0,σ=1
高斯分布即简化为标准正态分布:
对概率密度函数高效求值:
其中, β=1σ2β=1σ2 , 通过参数β∈(0,∞)β∈(0,∞) 来控制分布的精度.
问: 何时采用正态分布?
答: 缺乏实数上分布的先验知识, 不知选择何种形式时, 默认选择正态分布总是不会错的, 理由如下:
1. 中心极限定理告诉我们, 很多独立随机变量均近似服从正态分布, 现实中很多复杂系统都可以被建模成正态分布的噪声, 即使该系统可以被结构化分解.
2. 正态分布是具有相同方差的所有概率分布中, 不确定性最大的分布, 换句话说, 正态分布是对模型加入先验知识最少的分布.
正态分布的推广:
正态分布可以推广到RnRn
空间, 此时称为多位正态分布, 其参数是一个正定对称矩阵∑∑
:
对多为正态分布概率密度高效求值:
, 此处, β⃗ β→ 是一个精度矩阵.
指数分布和Laplace分布
指数分布
深度学习中, 指数分布用来描述在x=0x=0 点出取得边界点的分布, 指数分布定义如下:
, 指数分布用指示函数Ix>=0Ix>=0 来使x取负值时的概率为零.
* Laplace分布*
Laplace分布允许我们在任意一点μμ
处设置概率质量的峰值:
Dirac分布和经验分布
Dirac分布
Dirac分布可保证概率分布中所有质量都集中在一个点上. Diract分布的狄拉克δ函数(也称为单位脉冲函数)定义如下:
狄拉克δ函数图像:
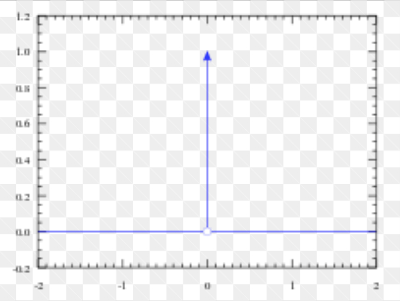
说明:
- 严格来说狄拉克δ函数不能算是一个函数,而是一种数学对象, 因为满足以上条件的函数是不存在的, 但是我们可以用分布的概念来解释, 因此称为狄拉克分布或者δδ
分布
- 它是一种极简单的广义函数. 广义函数是一种数学对象, 依据积分性质而定义. 我们可以把狄拉克δδ
函数想成一系列函数的极限点, 这一系列函数把除0以外的所有点的概率密度越变越小.
经验分布
狄拉克分布常作为经验分布的一个组成部分:
, 其中, m个点x(1)x(1) , …, x(m)x(m) 是给定的数据集, 经验分布将概率密度1m1m 赋给了这些点.
当我们在训练集上训练模型时, 可以认为从这个训练集上得到的经验分布指明了采样来源.
适用范围: 狄拉克δ函数适合对连续型随机变量的经验分布
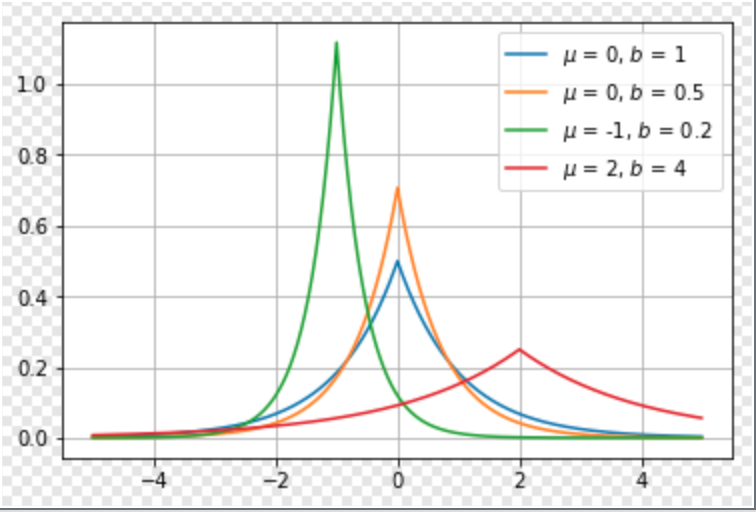
拉普拉斯分布(Laplace distribution)
有着与高斯分布很相近的形式,概率密度函数为Laplace(x;μ,γ)=12γexp(−|x−μ|γ)$,形状如下图:
高斯分布
拉普拉斯分布
4. 深度学习常用激活函数
-
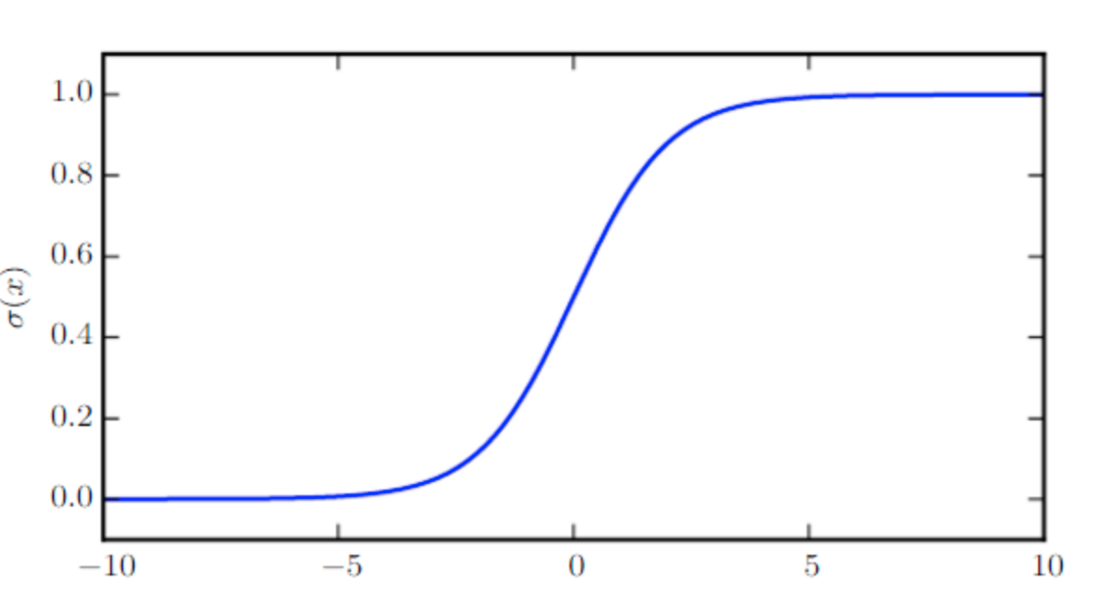
Logistic sigmoid函数
- σ(x)=11+exp(−x)σ(x)=11+exp(−x)
-
函数图像
-
logistic函数有许多重要的性质,通常被用来对数值进行平滑,下面是它的部分性质
σ(x)ddxσ(x)1−σ(x)logσ(x)=exex+e0=σ(x)(1−σ(x))=σ(−x)=−ζ(−x)σ(x)=exex+e0ddxσ(x)=σ(x)(1−σ(x))1−σ(x)=σ(−x)logσ(x)=−ζ(−x)
-
线性整流函数(Rectified Linear Unit, ReLU)
- ReLU(x)=max(0,x)ReLU(x)=max(0,x)
- 目前神经网络中最常用的一种非线性激活函数
-
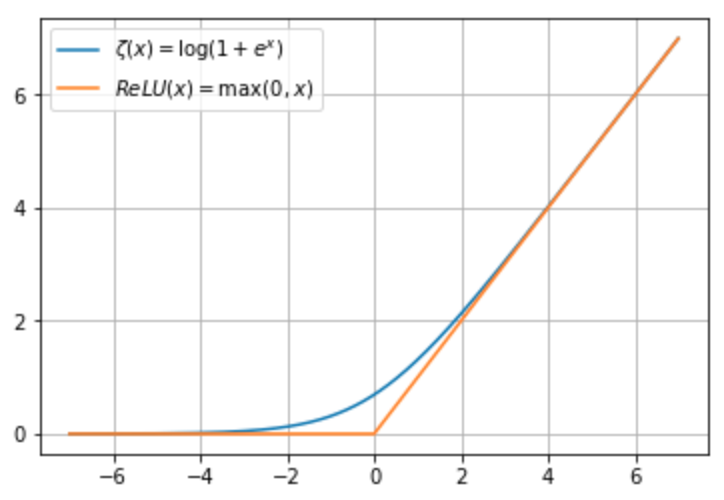
Softplus函数
- ζ(x)=log(1+exp(x))ζ(x)=log(1+exp(x))
-
softplus函数可以看作是max(0,x)max(0,x) 的一个平滑,他与ReLU的函数图像如下
-
它有如下性质
ddxξ(x)∀x∈(0,1),σ−1(x)∀x>0,ζ−1(x)ζ(x)ζ(x)−ζ(−x)=σ(x)=log(x1−x)=log(ex−1)=∫x−∞σ(y)dy=xddxξ(x)=σ(x)∀x∈(0,1),σ−1(x)=log(x1−x)∀x>0,ζ−1(x)=log(ex−1)ζ(x)=∫−∞xσ(y)dyζ(x)−ζ(−x)=x
5.结构化概率模型
概率图模型: 通过图的概念来表示随机变量之间的概率依赖关系
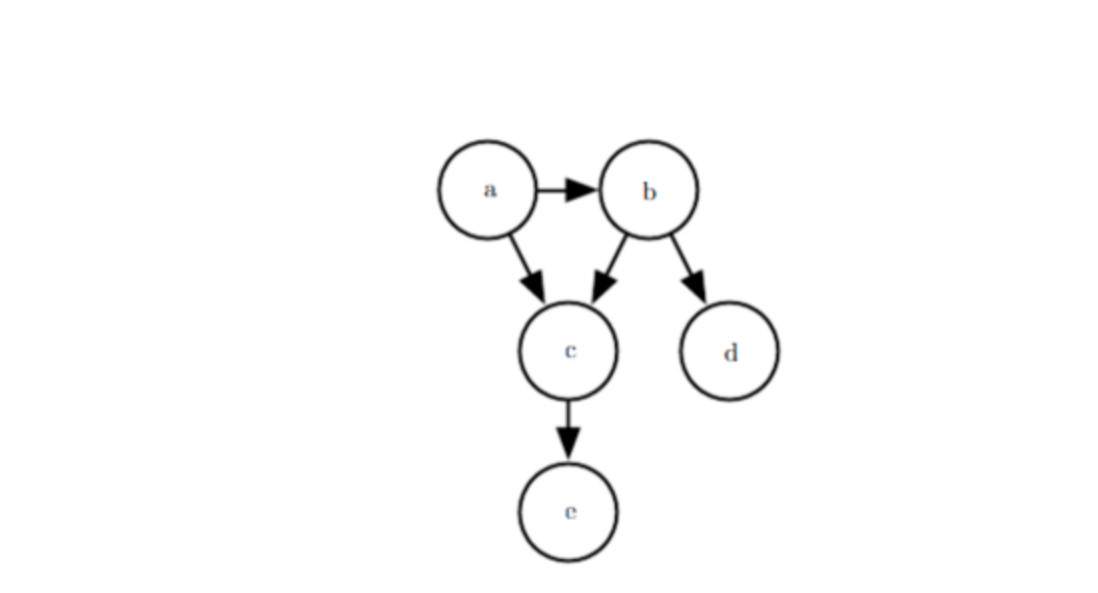
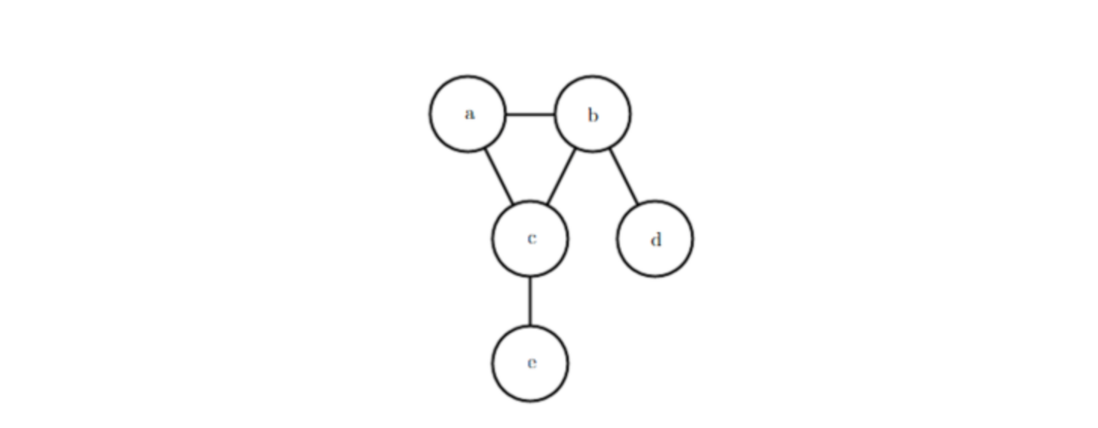
有向图表示的概率模型:
下图即为一个关于变量a,b,c,d,ea,b,c,d,e
之间的有向图模型,通过该图可以计算
无向图表示的概率模型:
公式:
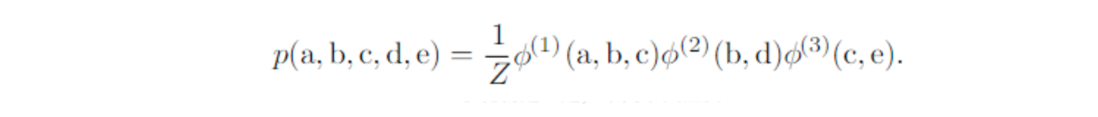
图:
似然函数
在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。似然函数可以理解为条件概率的逆反。
在已知某个参数αα 时,事件A会发生的条件概率可以写作P(A;α)P(A;α) ,也就是P(A|α)P(A|α) 。我们也可以构造似然性的方法来表示事件A发生后估计参数αα 的可能性,也就表示为L(α|A)L(α|A) ,其中L(α|A)=P(A|α)L(α|A)=P(A|α) 。
最大似然估计(MLE)与最大后验概率(MAP)
最大似然估计是似然函数最初的应用。似然函数取得最大值表示相应的参数能够使得统计模型最为合理。从这样一个想法出发,最大似然估计的做法是:首先选取似然函数(一般是概率密度函数或概率质量函数),整理之后求最大值。实际应用中一般会取似然函数的对数作为求最大值的函数,这样求出的最大值和直接求最大值得到的结果是相同的。似然函数的最大值不一定唯一,也不一定存在。
这里简单的说一下最大后验概率(MAP),如下面的公式
其中等式左边P(α|X)P(α|X) 表示的就是后验概率,优化目标即为argmaxαP(α|X)argmaxαP(α|X) ,即给定了观测值X以后使模型参数αα 出现的概率最大。等式右边的分子式P(X|α)P(X|α) 即为似然函数L(α|X)L(α|X) ,MAP考虑了模型参数αα 出现的先验概率P(α)P(α) 。即就算似然概率P(X|α)P(X|α) 很大,但是αα 出现的可能性很小,也更倾向于不考虑模型参数为αα 。
生成式模型与判别式模型
判别式模型学习的目标是条件概率P(Y|X)P(Y|X) 或者是决策函数Y=f(X)Y=f(X) ,其实这两者本质上是相同的。例如KNN,决策树,SVM,CRF等模型都是判别式模型。
生成模型学习的是联合概率分布P(X,Y)P(X,Y) ,从而求得条件概率分布P(Y|X)P(Y|X) 。例如NB,HMM等模型都是生成式模型。