1、网络编程:
socket----recv send方法
socketserver---多线程下的socket
接收大数据--方式:先发送长度,接收端接收该长度
防止粘包---方式1,发送接收交替进行 方式2,最后一次接收可变长度
2、多线程
threading---启动多线程方法,join
守护线程--setDemo(True)主线程结束,启动的守护线程跟着结束
GIL锁---同一时刻只有一个线程获得CPU计算资源。1、获取时间片2、获得GIL锁 在单核处理器上第2个条件永远满足
互斥锁--同一时刻只有一个线程修改共享变量
递归锁--声明同一个锁进嵌套的三个门,这个锁就要用递归锁
信号量--同一时刻运行n个线程修改共享变量 n=1,2,3,4...
多线程的协调--event,set标志位,clear标志位,wait标志位,isset方法。 如果标志位isset就前进,否则停下wait标志位
3、生成者消费者队列
生产者可以有多个线程,消费者可以多个线程。消费者者不停处理队列中的数据,生产者不停往队列里放数据
4、多进程
multiprocessing--父进程ID:os.getppid() 本进程ID:os.getpid() 进程占资源不能无限启动,有进程池:只能同时运行n个进程。
进程间数据传递:Queue、Pipe 进程间数据共享:Manager
5、协程
gevent---是对greenlet的封装,greenlet有switch方法,遇到IO手动切换,gevent是对其的封装,可以自动检测到IO自动切换
gevent有joinall方法,标记IO操作:monkey.patch_all()
6、协程的实现
数据的内核态,用户态。拿recv方法来说,send完成后recv的数据就准备好了,调用recv方法就将数据从内核内存空间拷贝到用户内存空间。
阻塞IO(没数据接收就阻塞) 非阻塞IO(没数据接收抛异常) 同步IO(阻塞IO,非阻塞IO,IO多路复用/事件驱动型IO 都是同步IO) 异步IO(完全不阻塞理论上的)
协程的实现方式:IO多路复用。 遇到一个IO就注册一个事件,监测这些事件,执行完成的就返回
IO多路复用三种实现方式:select、poll、epoll
epoll和gevent一样, 在Linux底层都是libevent.so实现的
讲bio,nio之前先看看服务端socket,服务端socket有2个阻塞点,一个是accept的时候,一个是recv的时候
import socket sock = socket.socket() sock.bind(("127.0.0.1", 8000)) sock.listen(20) client, address = sock.accept() # 阻塞1 ret = client.recv(1024) # 阻塞2 print(ret)
bio
特点:accept和recv都阻塞的情况下,想实现并发,必须要用多线程来实现
就是每次accept之后,启动一个线程处理与客户端通信,recv,send等

nio
随着内核对IO操作的优化,现在accept和recv都不阻塞了,一个线程就能实现IO并发
(当然,用多线程并发还能更高,把accept交个线程1,把遍历clients交个线程2, 还可以把clients切两半,交给两个线程)
伪代码实现:
import socket, time sock = socket.socket() sock.bind(("127.0.0.1", 8000)) sock.listen(20) sock.setblocking(False) # 1. accept改为非阻塞 clients = [] # 收到的请求都放在这里 buffer = bytes() # 模拟:服务端的缓存 while True: time.sleep(1) client, address = sock.accept() # 不阻塞了,无连接client返回null if not client: print("暂无连接---") else: client.setblocking(False) # 2.client改为非阻塞 clients.append(client) # 收到连接加入列表 for client in clients: if client.read(): # 客户端读到数据 buffer.read(client.read()) # 模拟:从客户端里读数据到buffer,position从0移到读到的长度位置 buffer.plit() # 模拟:position回到0位置 ret = buffer.write(10) # 模拟:从buffer中取出数据进行使用 print(ret) else: print("%s : 未收到数据" % client)

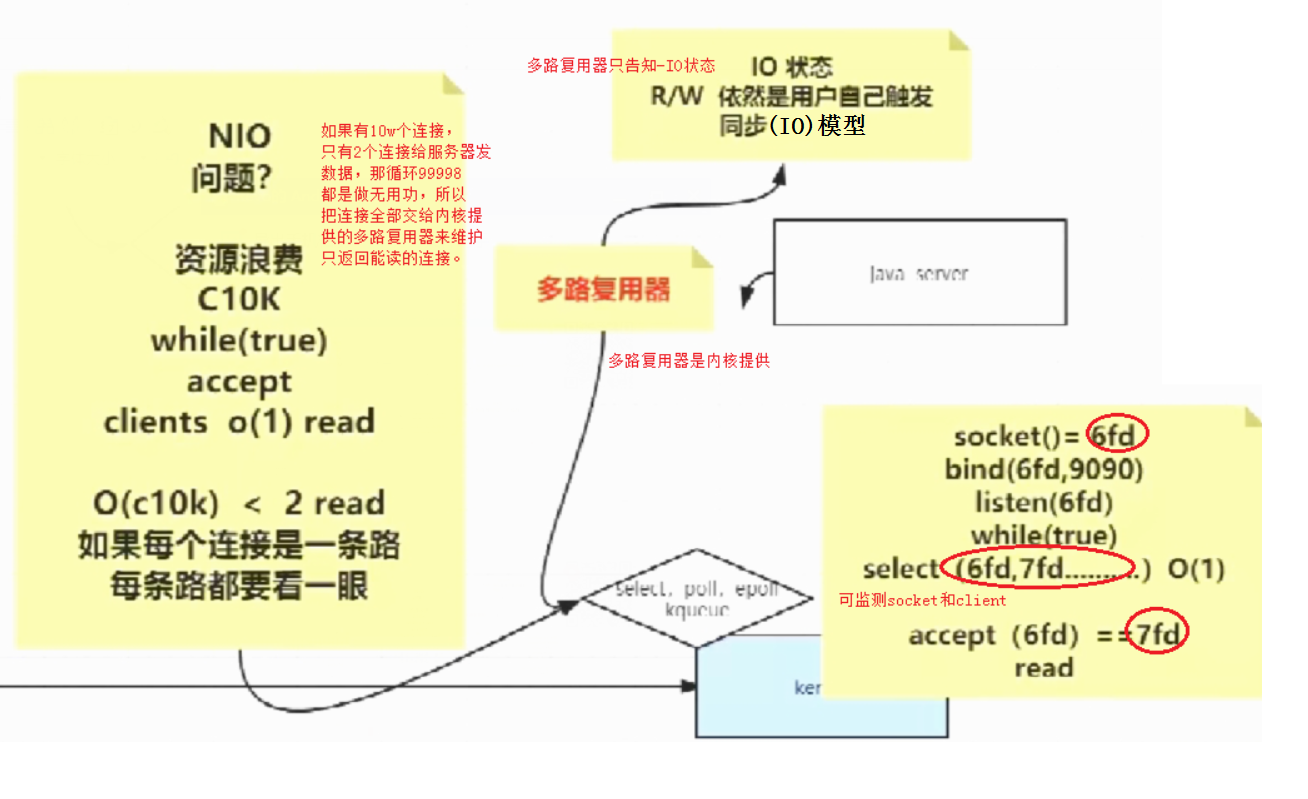
多路复用io
由于nio会造成资源浪费,所以把socket和client全部交个多路复用器来维护,客户端只需要遍历那些readable或者writable的client就行。
这样节省了资源。
but,多路复用器只告知状态。read和write操作扔需用户自己完成,这种R/W由用户自己完成的叫同步IO。以上,bio,nio,多路复用io都属于同步IO模型
伪代码
import socket, time import select sock = socket.socket() sock.setblocking(False) sock.bind(("127.0.0.1", 8000)) sock.listen(20) listens = [] listens.append(sock) while True: read_list, write_list = select.select(listens) # 多路复用器,用来监测sock和client的状态,分为can_read和can_write for item in read_list: if item.can_accept(): # 有新连接 client, address = item.accept() client.setblocking(False) buffer = bytes() listens.append(client, buffer) elif item.can_read(): # 有客户端发数据 client, buffer = item.client, item.buffer buffer.read(client.read()) # 模拟:从客户端里读数据到buffer,position从0移到读到的长度位置 buffer.plit() # 模拟:position回到0位置 ret = buffer.write(10) # 模拟:从buffer中取出数据进行使用 print(ret)
从上面可以引申出:
阻塞/非阻塞 同步/异步是什么?
拿现实生活的例子 ,老张=阻塞/非阻塞, 智能水壶=同步/异步 (阻张同水)
同步阻塞IO:老张立着等普通水壶开了,自己倒杯水 (bio)
同步非阻塞IO:老张看电视,一会去看一下普通水壶开没开,如果发现开了,自己倒杯水(nio,多路复用io)
异步阻塞IO:老张立着等智能水壶自己开了给自己送杯开水 (程序中没有这种模型)
异步非阻塞IO:老张边看电视,边等智能水壶开了给自己送杯开水(前提是老张烧开水前要告诉智能水壶,你开了之后自己给我倒杯水过来==>callback)
伪代码: 智能水壶.烧开水(开水开了, callback=(return 开水))
要牢牢的记住:select、poll、epoll都是多路复用器,都是同步IO模型,但epoll是里面效率最高的。
为什么epoll是效率最高的呢??上面的代码中使用的是select实现的多路复用器,实际上,select和poll都有弊端:
1. select.select( [.文件描述符1,文件描述符2,..] ) 每次循环调这个方法都传递了重复的参数。
2. 每次调用select.select( [文件描述符1,文件描述符2,..] ) 的时候内核都需要遍历传递的所有参数
这样肯定让内核做了重复劳动,有没有一个办法,把用户要监控的sock和client存起来呢?
因为存起来之后,随网卡有数据包的到来产生中断事件,产生了回调,就知道那个文件描述符有数据到达,内核在忙别的事的时候就把readable的文件描述符准备好了。
伪代码

nignx是使用epoll的,怎么看呢?
`yum -y install strace` //先安装内核指令监控器,用来监控内核空间和用户空间的交互过程
`cd /usr/local/nginx/sbin/` //进入nginx安装目录
`strace -ff -o out ./nginx` //开始监控,阻塞

`ps -ef | grep nginx`

`ll` //out开头的是监控记录,out.进程ID

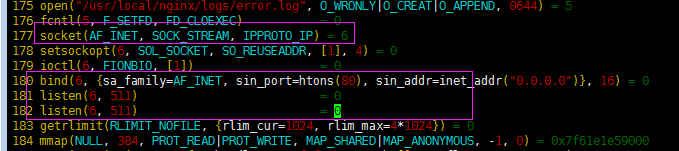
`vim out.50796` //50796进程作用是进行socket监听
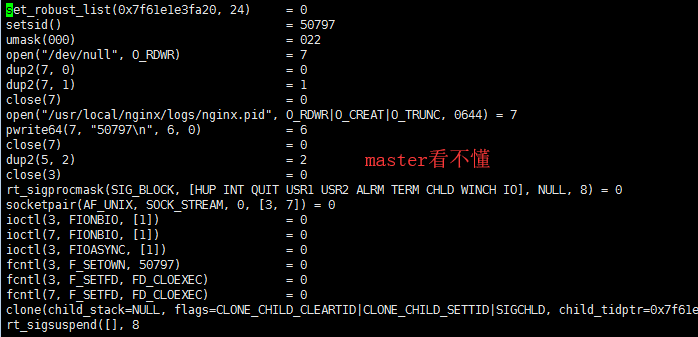
`vim out.50797` //50397是master,作用是管理worker,交互命令看不懂。。。。
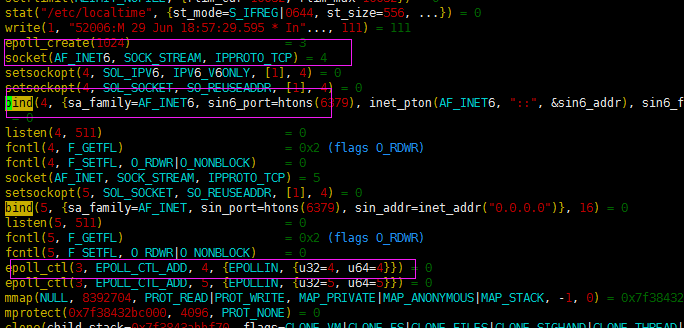
`vim out.50798` //工作进程worker,可以看出nginx使用的是epoll模型

同样redis也是用的epoll模型
最后一个问题:
Linux没有实现异步IO(效率并不高),Epoll是一种I/O多路复用技术,用户程序需要主动的去询问内核是否有事件发生,而不是事件发生时内核主动的去调用回调函数,所以不是异步的。
而Tornado等框架之所以声称是异步的,是框架在epoll的基础上进行了一层封装,由框架去取事件,然后由框架去调用用户的回调函数,所以对于基于框架的用户程序来说,是异步的。
Tornado是单线程,所以所有的I/O操作必须是非阻塞的
