如果想在任务成功或者失败额外做点事,可以重写Task类。
tasks.py
from __future__ import absolute_import, unicode_literals from .celery import app from celery.task import Task class MyTask(Task): def on_success(self, retval, task_id, args, kwargs): print('task done==================>: {0}'.format(retval)) return super(MyTask, self).on_success(retval, task_id, args, kwargs) def on_failure(self, exc, task_id, args, kwargs, einfo): print('task fail, reason=================>: {0}'.format(exc)) return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo) @app.task(base=MyTask) def add(x, y): return x + y
@app.task(bind=True)
意思是绑定任务为实例方法,执行中的任务能获取到了自己执行任务的各种信息,可以根据这些信息做很多其他操作,例如判断链式任务是否到结尾等等。
示例:
# tasks.py from celery.utils.log import get_task_logger logger = get_task_logger(__name__) @app.task(bind=True) def add(self, x, y): logger.info(self.request.__dict__) return x + y
案例模拟进度条,查看任务进度
------------------目录结构-------------------
--start.py
--proj
--celery.py
--tasks.py
--------------------------------------------------


from __future__ import absolute_import, unicode_literals #导入安装的celery(所以上面要写绝对导入),而不是自己导自己(from .celery) from celery import Celery app = Celery('proj', broker='redis://', backend='redis://', include=['proj.tasks',]) # 这个celery管理了哪些task文件可以有多个,其中有个定时任务periodic_task # Optional configuration, see the application user guide. # update方法更新配置,也可以直接写在上面初始化Celery里面 app.conf.update( result_expires=3600, # 任务结果一小时内没人取就丢弃 ) if __name__ == '__main__': app.start()
from __future__ import absolute_import, unicode_literals from .celery import app #from celery import Celery import time @app.task(bind=True) def test_mes(self): for i in range(1, 11): time.sleep(1) self.update_state(state="PROGRESS", meta={'p': i*10}) return 'finish'
from proj.tasks import test_mes import sys def pm(body): res = body.get('result') if body.get('status') == 'PROGRESS': sys.stdout.write(' 任务进度: {0}%'.format(res.get('p'))) sys.stdout.flush() else: print(' ') print(res) r = test_mes.delay() r.get(on_message=pm, propagate=False) #'FINISH'
excel入库步骤进度显示
tasks.py
from .celery import app import time @app.task(bind=True) def excel_info_db(self): time.sleep(1) self.update_state(state="PROGRESS", meta={'step':'加载excel到内存', 'progress':'100%'}) time.sleep(1) self.update_state(state="PROGRESS", meta={'step': '在内存中校验excel', 'progress': '100%'}) time.sleep(1) self.update_state(state="PROGRESS", meta={'step': '入库', 'progress': '100%'}) return 'finish'
链式任务:
有些任务可能需由几个子任务组成,此时调用各个子任务的方式就变的很重要,尽量不要以同步阻塞的方式调用子任务,而是用异步回调的方式进行链式任务的调用:
比如某个任务要依赖某几个任务的返回值,那这几个任务就可以同时进行,可节省时间
---------------目录结构----------------------
--start.py
--proj
--celery.py
--tasks.py
-------------------------------------------------
tasks.py
# tasks.py from .celery import app import time @app.task() def fetch_page(url): time.sleep(3) return "抓取到的%s的内容" % url @app.task() def parse_page(page): # page是fentch_page的返回值 time.sleep(3) return "对%s做解析,得到数据" % page ''' 如果用这个@app.task(ignore_result=True)装饰 就算全部执行完,res.get()还是会阻塞 ''' @app.task() def store_page_info(info, url): print(info + '%s数据进行入库...' % url) time.sleep(3) return '执行结束'
start.py
# start.py from celery import group, chain from proj.tasks import * def update_page_info(url): # fetch_page -> parse_page -> store_page # 第一种写法 # chain = fetch_page.s(url) | parse_page.s() | store_page_info.s(url) # # chain() # 第二种写法,res.get()为最后返回的结果 res = chain(fetch_page.s(url),parse_page.s(),store_page_info.s(url))() while True: if res.ready(): print(str(res.get())) break update_page_info('www.google.com')
celery.py(celery配置)
from __future__ import absolute_import, unicode_literals #导入安装的celery(所以上面要写绝对导入),而不是自己导自己(from .celery) from celery import Celery app = Celery('proj', broker='redis://', backend='redis://', include=['proj.tasks',]) # 这个celery管理了哪些task文件可以有多个,其中有个定时任务periodic_task # Optional configuration, see the application user guide. # update方法更新配置,也可以直接写在上面初始化Celery里面 app.conf.update( result_expires=3600, # 任务结果一小时内没人取就丢弃 ) if __name__ == '__main__': app.start()
执行:
1.启动worker:`celery -A proj worker -l debug` //cd到proj目录下才能启动
2.向队列放任务: `python3 start.py` //cd到proj的上一级目录执行
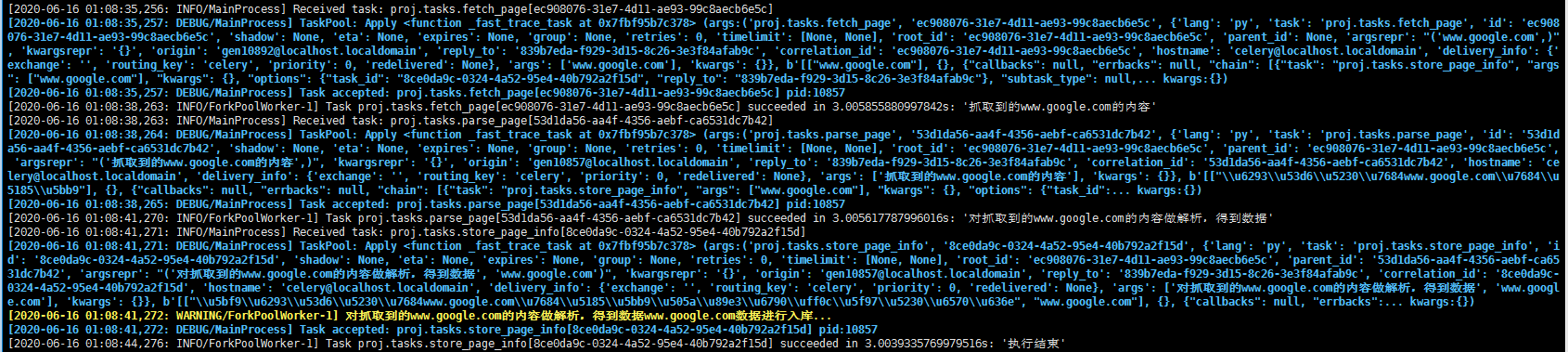
链式任务中前一个任务的返回值默认是下一个任务的输入值之一 ( 不想让返回值做默认参数可以用 si() 或者 s(immutable=True) 的方式调用 )。
这里的 s() 是方法 celery.signature() 的快捷调用方式,signature 具体作用就是生成一个包含调用任务及其调用参数与其他信息的对象,个人感觉有点类似偏函数的概念:先不执行任务,而是把任务与任务参数存起来以供其他地方调用。
调用任务方式二:fetch_page.apply_async((url), link=[parse_page.s(), store_page_info.s(url)])前面讲了调用任务不能直接使用普通的调用方式,而是要用类似 add.delay(2, 2) 的方式调用,而链式任务中又用到了 apply_async 方法进行调用,实际上 delay 只是 apply_async 的快捷方式,二者作用相同,只是 apply_async 可以进行更多的任务属性设置,比如 callbacks/errbacks 正常回调与错误回调、执行超时、重试、重试时间等等,具体参数可以参考:https://docs.celeryproject.org/en/latest/reference/celery.app.task.html#celery.app.task.Task.apply_async
组任务group
并行执行组内的每个任务
from celery import group
group(fetch_page.s(url),parse_page.s('test1'),store_page_info.s('test2',url))()任务分割chord
分为header和body两个部分,会先执行header在将header的结果传给body执行
from celery import chord
chord(header=[fetch_page.s(url)],body=parse_page.s())()任务分组chunks
按照任务个数分组,并不是并发执行
from celery import chunks
fetch_page.chunks(['1','2','3'],2)() #2代表每组的任务个数,需要注意的是如果第一个参数传入的是字符串的话,那么字符串会被分割成每个字符当作参数传入