一:大小端
(一)大小端区别(字节)
区别是依据:计算机系统在存储数据时起始地址是高地址还是低地址。
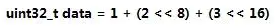
小端:从低地址开始存储
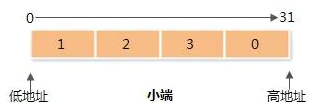
大端:从高地址开始存储
补充:这里大小端是按字节区别的,还有按字的。按字节,则字节大小数据不会改变数据格式,所以如上图中小端“1”,和大端“1”是一样存储的
补充:在内存中存储数据还是从低地址开始寻址,找到一块空间分配以后,根据大小端区别向内部填充数据
(二)代码实现对大小端的判断
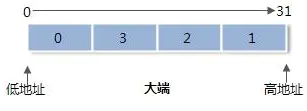
#include <iostream> #include <stdint.h> using namespace std; bool bigCheck() { union Check{ //起始地址是一致的 char a; uint32_t data; }; Check c; c.data = 1; if(1==c.a){ return false; } return true; } int main(int argc,char* argv[]) { if(bigCheck()){ cout<<"big "<<endl; }else{ cout<<"small "<<endl; } return 0; }
1.选取内存空间
2.大端存放数据
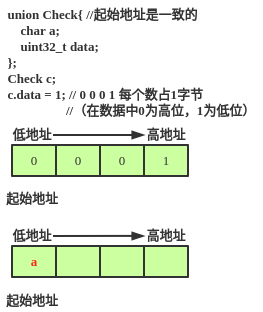
3.小端存放数据
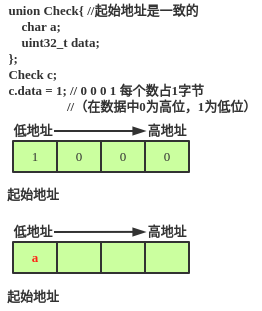
输出结果:

二:本地系统与网络中的大小端问题
(一)本地操作系统与网络字节序
1.本地字节序
不同操作系统可能会采用不同的字节序,所以当通信双方字节序不同时需要考虑字节序转化问题
2.网络字节序
为了避免在网络通信中引入其他复杂性,网络字节序统一是大端的
(二)序列化与反序列化
任何变量,不管是堆变量还是栈变量都对应着操作系统中的一块内存,由于内存对齐的要求程序中的变量并不是紧凑存储的,例如一个c语言的结构体Test在内存中的布局可能如下图所示。
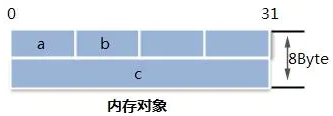
1.序列化:通过将计算机语言中的内存对象转换为网络字节流,例如把c语言中的结构体Test转化成uint8_t data[6]字节流。

2.反序列化:将网络字节流转换为计算机语言中的内存对象,例如把uint8_t data[6]字节流转化成c语言中的结构体Test。
通过序列化可以使得网络传输得到数据量更少,通过反序列化使得数据接受时格式与原来一致。
三:网络编程中的一点小疑惑
(一)前面提到本地字节序和网络字节序(大小端)不同,那么如何转换??
htonl()--"Host to Network Long" ntohl()--"Network to Host Long" htons()--"Host to Network Short" ntohs()--"Network to Host Short"
以上4种函数实现了对16位、32位数据的网络到本地、本地到网络的转换。
补充:数字所占位数小于或等于一个字节(8 bits)时,不要用htons转换。这是因为对于主机来说,大小端的最小单位为字节(byte)
(二)本地到网络中的哪些数据需要转换??(重点)
不是所有从本地传输到网络中的数据都需要进行大小端的转换!!!
我们只需要将IP网络层需要访问的数据转化为大端模式,这样网络才知道如何传递、转发数据。而这些数据是指IP地址和端口,IP网络层需要根据这些信息进行转发。
IP为网络层,使用的是大端字节序,在IP层中要读取TCP头部中的信息,以确定要访问的地址。
所以要将port,ip等将在网络层被读取的信息转为大端字节序。
而发送的具体信息,并不被网络层所读取(只是传输),因此只要保证接受方与发送发使用的字节序相同,就不需要进行转换
