一:常见激活函数Sigmoid、Relu、Tanh、Softmax
(一)sigmoid:https://www.jianshu.com/p/506595ec4b58---可以作为激活函数
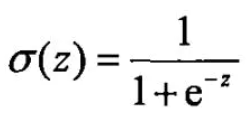
1) 值域在0和1之间 2) 函数具有非常好的对称性 3) 函数对输入超过一定范围就会不敏感

(二)tanh:http://www.ai-start.com/dl2017/html/lesson1-week3.html---可以作为激活函数
tanh函数或者双曲正切函数是总体上都优于sigmoid函数的激活函数,值域是位于+1和-1之间,其均值是更接近零均值的。在训练一个算法模型时,如果使用tanh函数代替sigmoid函数中心化数据,使得数据的平均值更接近0而不是0.5.
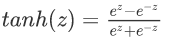
但是在二分类中(0,1)还是用sigmoid更好,因为范围在(0,1)之间。

sigmoid与tanh缺点: sigmoid函数和tanh函数两者共同的缺点是,在特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后斜率就会接近于0,导致降低梯度下降的速度
(三)relu:http://www.ai-start.com/dl2017/html/lesson1-week3.html---可以作为激活函数
修正线性单元的函数(ReLu): 所以,只要是正值的情况下,导数恒等于1,当是负值的时候,导数恒等于0。
补充:从实际上来说,当使用的导数时,=0的导数是没有定义的。但是当编程实现的时候,的取值刚好等于0.00000001,这个值相当小,所以,在实践中,不需要担心这个值,是等于0的时候,假设一个导数是1或者0效果都可以。
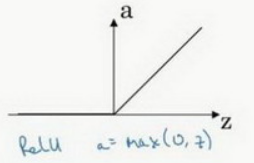
注意:这里也有另一个版本的Relu被称为Leaky Relu。
当是负值时,这个函数的值不是等于0,而是轻微的倾斜,这个函数通常比Relu激活函数效果要好,尽管在实际中Leaky ReLu使用的并不多。

Relu优点:
第一,在的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于0,在程序实现就是一个if-else语句,而sigmoid函数需要进行浮点四则运算,在实践中,使用ReLu激活函数神经网络通常会比使用sigmoid或者tanh激活函数学习的更快。
第二,sigmoid和tanh函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散,而Relu和Leaky ReLu函数大于0部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,Relu进入负半区的时候,梯度为0,神经元此时不会训练,产生所谓的稀疏性,而Leaky ReLu不会有这问题)
在ReLu的梯度一半都是0,但是,有足够的隐藏层使得z值大于0,所以对大多数的训练数据来说学习过程仍然可以很快。
(四):回归函数softmax
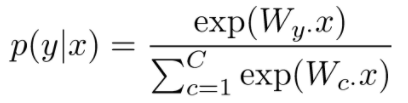
1)softmax第一步就是将模型的预测结果转化到指数函数上,这样保证了概率的非负性。 2)各种预测结果概率之和等于1

softmax不同于其他激活函数,一般只用于输出层上!!之前,我们的激活函数都是接受单行数值输入,例如Sigmoid和ReLu激活函数,输入一个实数,输出一个实数。Softmax激活函数的特殊之处在于,因为需要将所有可能的输出归一化,就需要输入一个向量,最后输出一个向量。
补充:hardmax
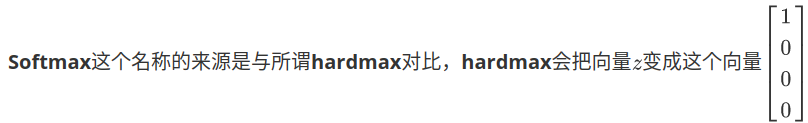
二:交叉熵函数
(一)错误记忆-XXX
由于先去学习的二分类,所以把交叉熵求解记成了如下格式:https://www.jianshu.com/p/b07f4cd32ba6
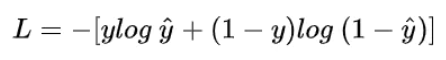
这只是二分类当中的交叉熵函数!!!,对于多分类是错误的!!!!
(二)正确版本-√√√

其中,k是类别。交叉熵刻画的是通过概率分布y^来表达概率分布y的困难程度。因为正确答案是希望得到的结果,所以当交叉熵作为神经网络的损失函数时,y代表的是正确答案,y^代表的是预测值。
交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小, 两个概率分布越接近。
补充:交叉熵代价函数见:https://www.zhihu.com/question/341500352/answer/795497527
(三)在tensorflow中的交叉熵求解

labels = [[0.2,0.3,0.5]] #真实值 logits = [[2,0.5,1]] #预测值 #直接计算交叉熵 result1 = tf.nn.softmax_cross_entropy_with_logits(labels=labels,logits=logits) #输入的不是经过softmax缩放过的值 #需要先对预测值进行缩放 logits_scaled = tf.nn.softmax(logits) result2 = -tf.reduce_sum(labels*tf.log(logits_scaled),1) with tf.Session() as sess: print(sess.run(result1)) print(sess.run(result2))
![]()
三:softmax_cross_entropy_with_logits解惑
其实上面案例(三)已经给出了解答:就是Tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作。softmax_cross_entropy_with_logits内部会实现缩放,即softmax操作。
(一)案例一如二中(三)
(二)案例二
labels = [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0] logits = [5.414214045506107, 1.0364190761952838, 1.0931452034494957, 3.894246202026429, 2.3824730004342136, 5.965072403073978, 2.076533529367469, 1.4828656147245602, 2.3414934241076537, 3.5602012920818584, 0.11375485316768152, 3.450451299129589, 2.8094892586761437, 1.788879710725854, 2.80663522176181, 4.924723247878252, 2.4961140164238786, 5.9613323377434995, 0.7989157311136863, 4.2635188203807335, 3.4873045567789664, 5.11255294433231, 3.2693959007989832, 4.490670418324648, 1.6669091076779448, 5.747519715144237, 1.4899624466441748, 4.077105711625433, 0.1835752962824988, 5.337763177515887, 5.809078207371751, 3.070040261173903, 2.4653770382715177, 0.03311200569409323, 3.3492673710270733, 3.477621449855114, 3.63523160480906, 2.312116025458221, 0.45082654327315574, 0.4283251243179722] #logits是随机初始化的值 labels = np.array([labels]) logits = np.array([logits])
logits_scaled = tf.nn.softmax(logits)
#两种交叉熵正确解法 result1 = tf.nn.softmax_cross_entropy_with_logits(labels=labels,logits=logits) result2 = -tf.reduce_sum(labels*tf.log(logits_scaled),1) #使用缩放后的值作为输入,是错误的 result3 = tf.nn.softmax_cross_entropy_with_logits(labels=labels,logits=logits_scaled)
with tf.Session() as sess: print(sess.run(result1)) print(sess.run(result2)) print(sess.run(result3)) #使用缩放的值作为输入,结果会出错

(三)使用缩放后的值作为softmax_cross_entropy_with_logits输入,导致的错误
CNN实现验证码识别中:
正确使用softmax_cross_entropy_with_logits时:
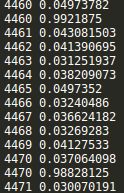
在4000次迭代后,误差降为0.03,准确率在98%。
错误使用softmax_cross_entropy_with_logits时:

