数学建模算法
- 可以使用多个算法求解同一个问题,相互印证比较,写进论文中可以增色不少。
目录
线性规划
- 标准形式:向量均为列向量,最后一条语句中缺少的项使用
[]代替 - 化成求最小值,约束不等式为
<=号; - 脚本的最后配合输出语句使用
- 切记切记:列向量每行使用
;隔开 x为列向量,可以不是(n*1),可以是(n*2)等等

插值 && 拟合 && 逼近
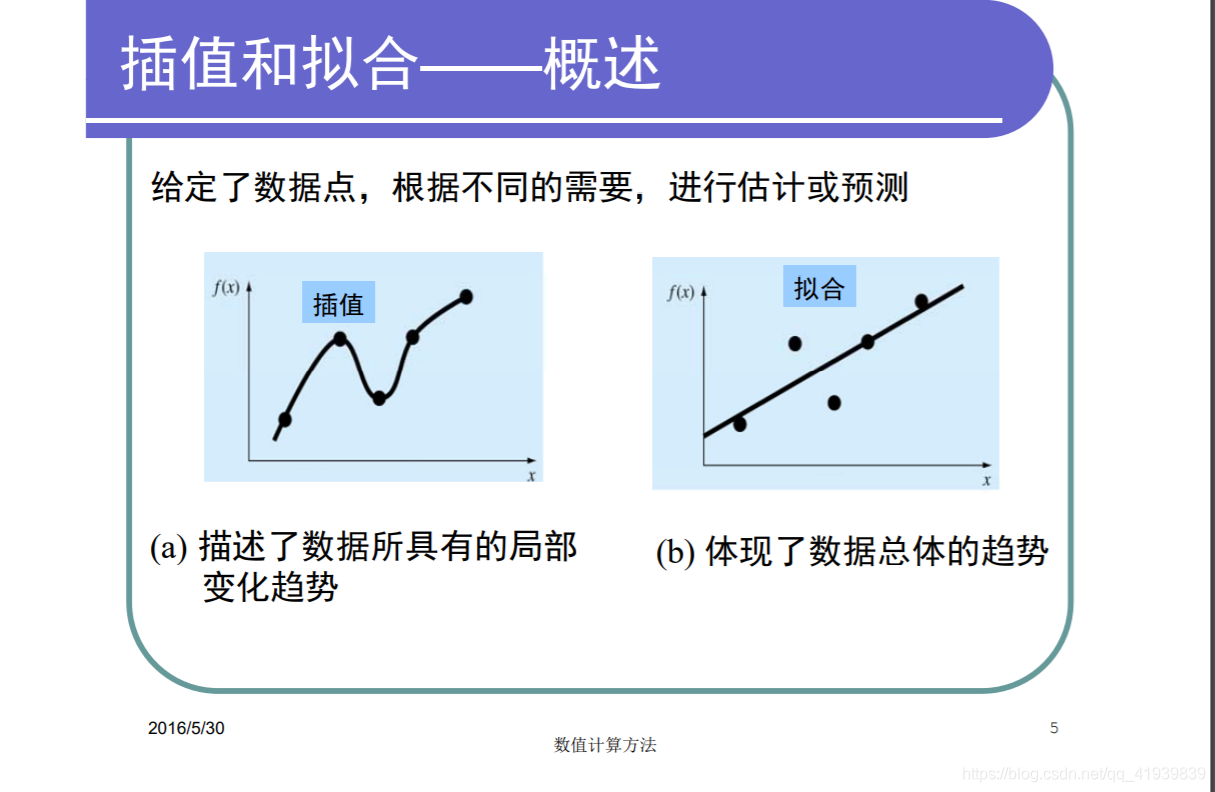

- 插值: 插值曲线一定要经过样本点,即使样本点有误差也要严格经过样本点,这就要求样本点数据正确无误的时候使用插值(对象:散点),三次样条插值使用很广泛
- 拟合:在插值的基础上有了误差分析,不严格要求进过所有样本点,只要求构造函数描述整体趋势并使得误差最小。(对象:散点)
- 函数逼近:拟合是构造函数对散点拟合,函数逼近是对已知的复杂函数,通过构造一个较简单的函数或多项式,使得数据接近原来的复杂函数
层次分析法(计算权重)
方法步骤
- 应用:解决选择最佳问题。给出一系列影响选择的因素,按照因素之间的相互关联和相对重要程度,综合考虑这些因素,做出最佳选择。

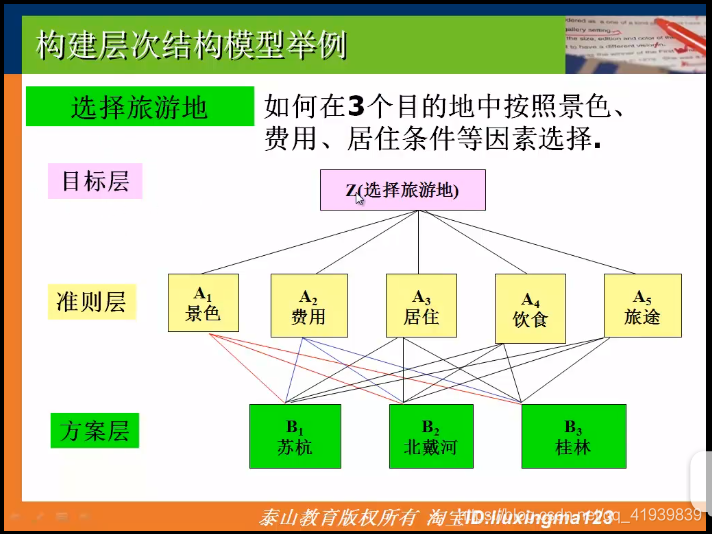

- 当各行各列严格成比例时,表示完全一致性

实例
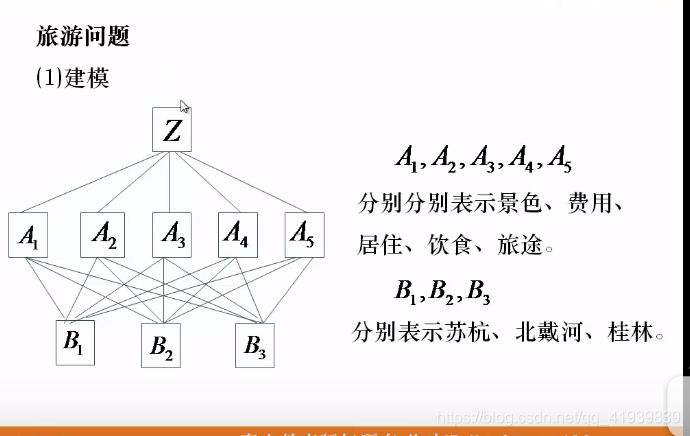
- 构造比较矩阵
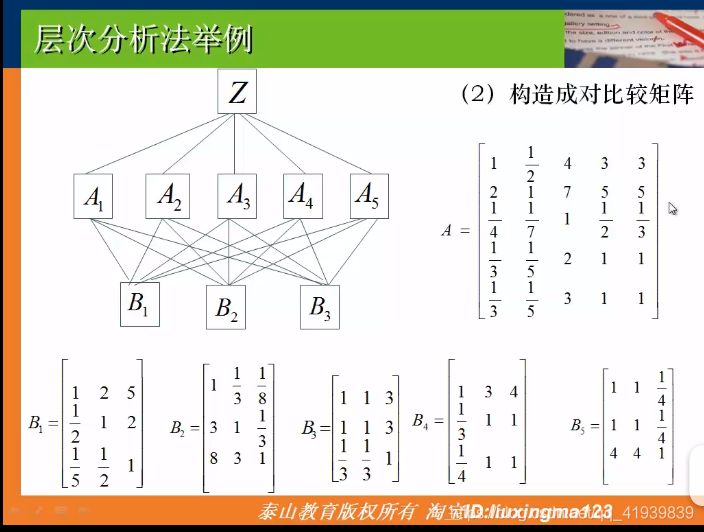
A矩阵为A1,A2,..…..,A5之间两两比较的结果,如:A1:A3=4,结合前面图的成对比较阵标度表,表示对于最佳选择来说,A1(景色)比A3(居住)大于稍微重要但是又小于明显重要。
B1,B2,..…B5表示三个地方在这5个因素之间的对比。如:B1中第一行的2表示在景色方面苏杭比北戴河要稍微好一些(结合成对比较阵标度表)这些矩阵的填写主观性很强,可以通过查找相关资料稍微减少主观性
% 按要求输入比较矩阵即可得出每个因素相对于目标来说的权值
% 注意矩阵的输入格式,代码无需修改直接使用
disp('请输入成对比较矩阵A(n阶)');
A=input('A=');
[n,n]=size(A);
x=ones(n,100);
y=ones(n,100);
m=zeros(1,100);
m(1)=max(x(:,1));
y(:,1)=x(:,1);
x(:,2)=A*y(:,1);
m(2)=max(x(:,2));
y(:,2)=x(:,2)/m(2);
p=0.0001;i=2;k=abs(m(2)-m(1));
while k>p
i=i+1;
x(:,i)=A*y(:,i-1);
m(i)=max(x(:,i));
y(:,i)=x(:,i)/m(i);
k=abs(m(i)-m(i-1));
end
a=sum(y(:,i));
w=y(:,i)/a;
t=m(i);
disp(w);
%以下是一致性检验
CI=(t-n)/(n-1);RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59];
CR=CI/RI(n);
if CR<0.10
disp('此矩阵的一致性可以接受!');
disp('CI=');disp(CI);
disp('CR=');disp(CR);
end

- 圈住的部分表示5个影响因素的权值,CI和CR可以不用管
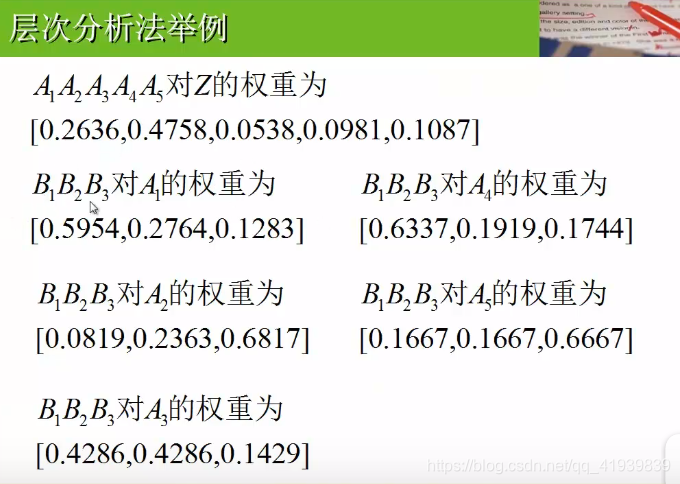
- 根据得到的权值,进行权值传递(其实就是对应权值相乘再累加)得到最低层对最终目标的取值,根据权值大小可以得出最佳选择


- 答案的正确性程度取决于成对比较矩阵的合理性
模型拓展
- 多准则层,一层一层计算即可
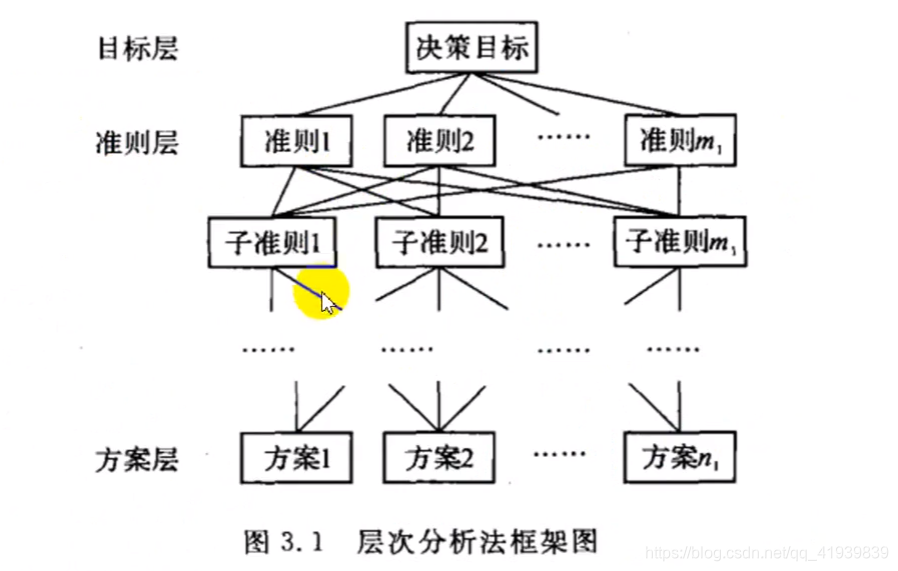
- 每个准则层对应自己的方案层,非当前准则层的因素的权重设置为0即可,具体看付费群的论文

多属性决策模型(计算属性值)
+
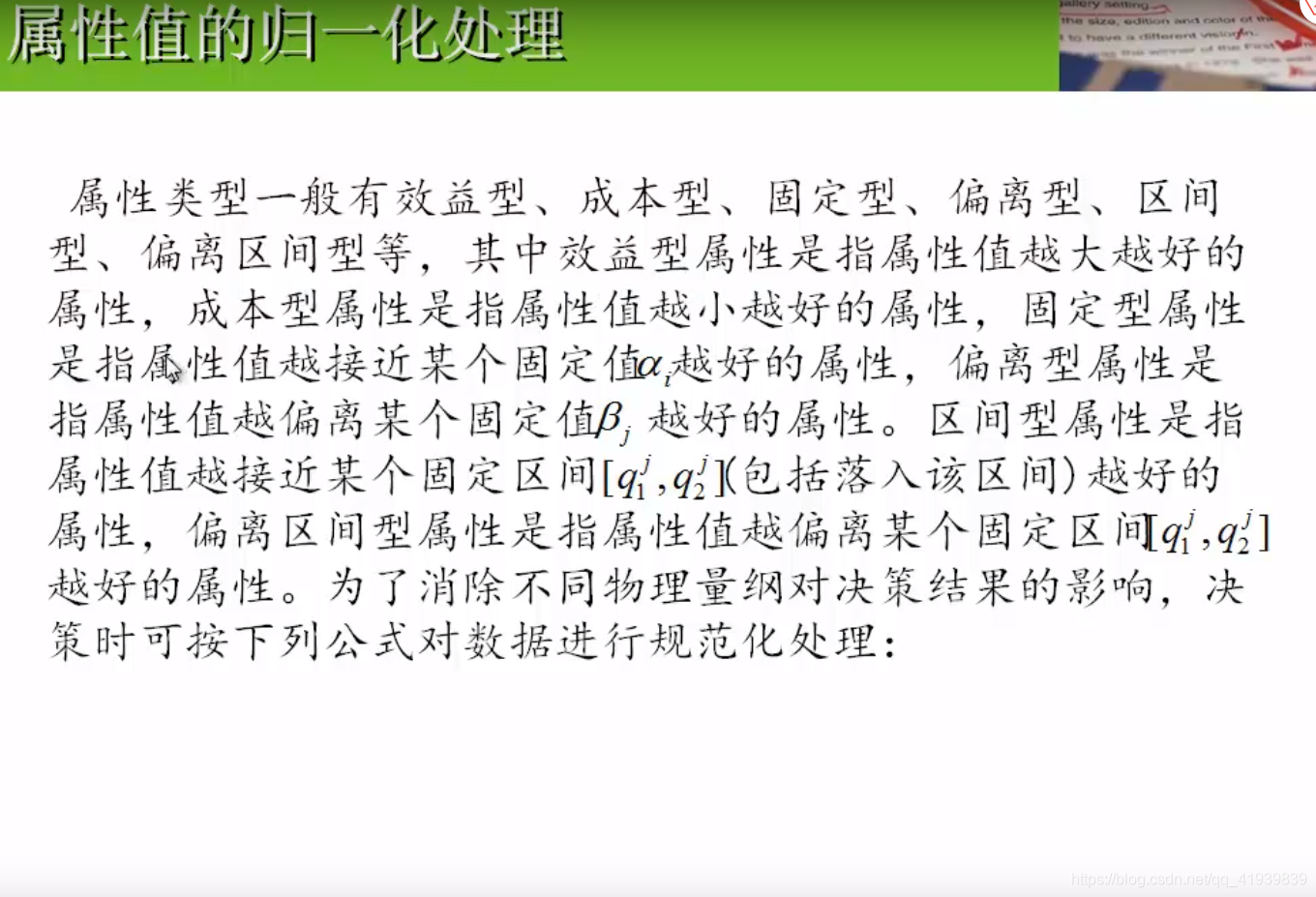
- 属性值的归一化处理,在上面的得分数据组中,比如:不一定每个得分都是百分制的,可能有些是十分制的。属性值量纲不一致时,通过归一化处理全部转化为百分制形式。




例子

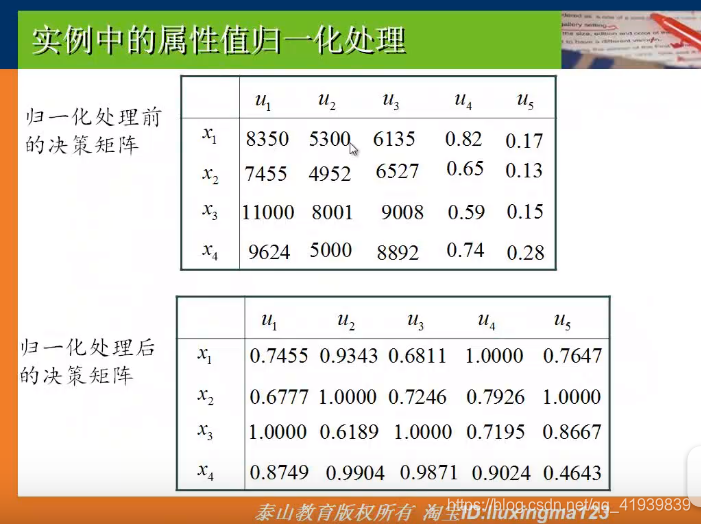
- 利用上一讲的层析分析计算权值

- 利用加权平均算子,结合属性权值和属性值计算每个企业的总得分
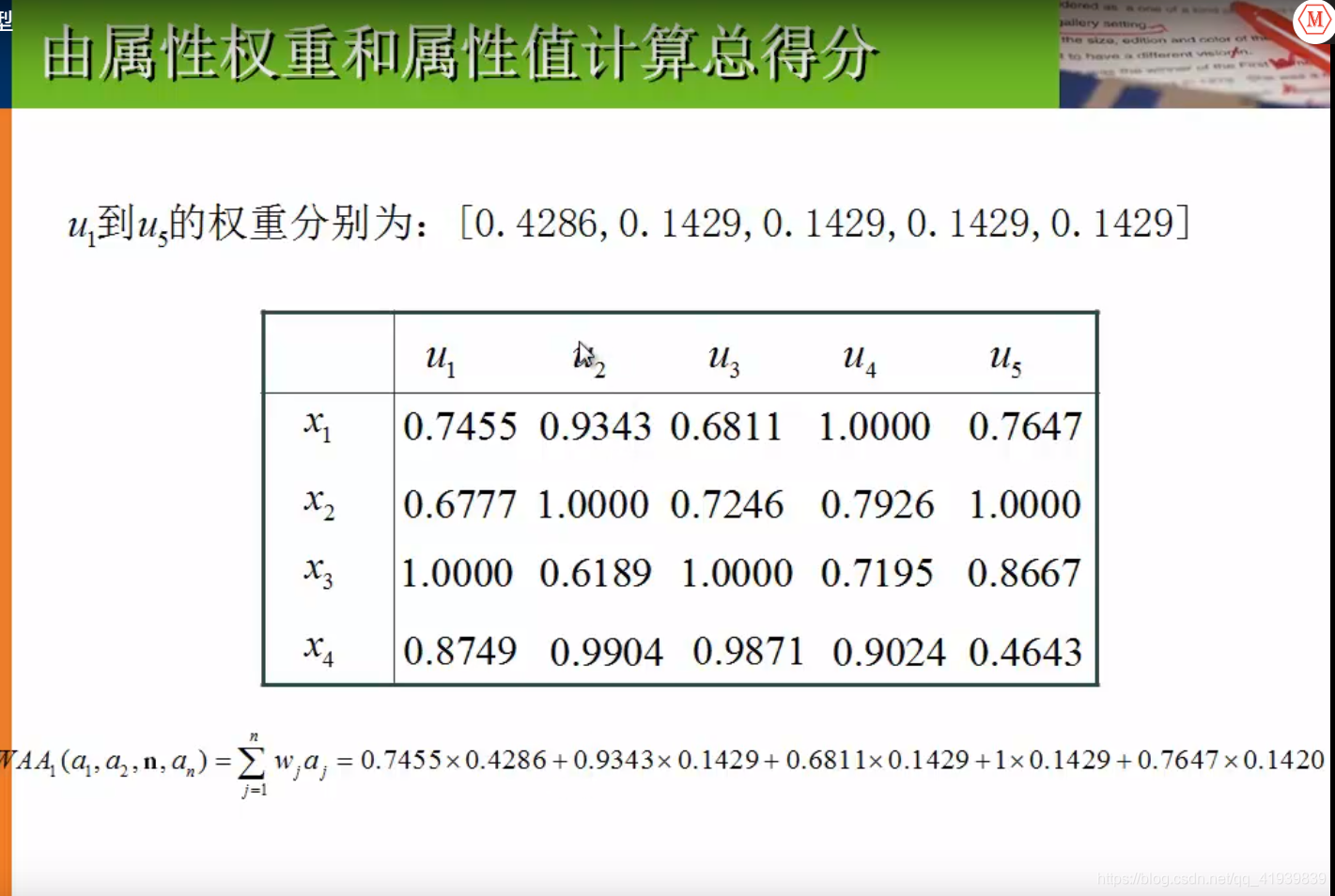

灰色预测(小样本回归分析)
和常见预测方法的区别:
- 常见预测方法:一些常用的预测方法,像回归分析,需要大量样本,,若样本较小会造成较大的误差
- 灰色预测:此模型所需建模信息少,建模精度高,处理小样本预测问题的有效工具
特点
-
不直接使用原始数据,对原始数据进行处理生成新的数据,用于预测(原始数据一般杂乱无章,但是内部必然存在某种规律,只不过被表象所掩盖),常见生成灰色预测数据的方式:累加生成,类减生成,均值生成,级比生成
-
累加生成:其实就是前缀和

-
GM(1,1)模型精度检验(适用于较强指数规律序列,描述单调变化,非单调的摆动或者饱和S形使用其他模型(参加数学建模算法与应用))
- 只有通过检验的模型才能用来预测,常用精度检验方法:相对误差大小检验法,关联度检验法,后验差检验法
- 后验差检验法


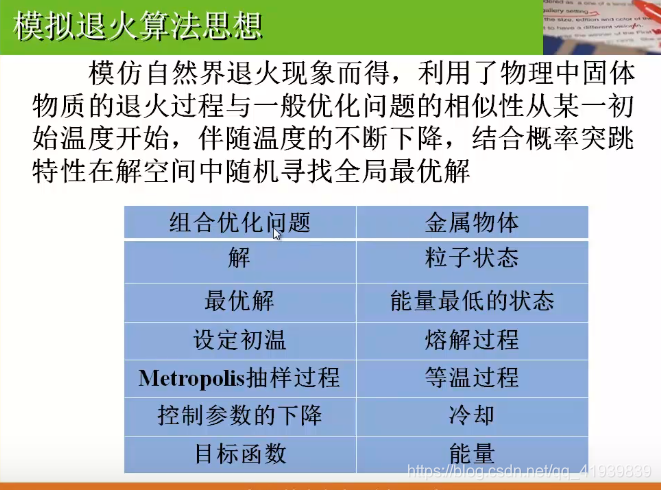
模拟退火算法
- 模拟物理退火,使总能量达到最低值,系统达到平衡状态,也就是可以用来求最小值,乘上-1或者取倒数可以用来求解最大值。
- 从某一初始温度开始,伴随问题的不断下降,结合概率突跳特性在解空间中随机寻找全局最优解
主成分分析法
主成分分析,因子分析,层次分析法比较
- 主成分分析法,因子分析法,层次分析法,前两种方法是多维变量的降维处理,简化数据的,后一种主观赋权的综合评价方法
- 对于少数据样本不如因子分析有用,但是数据量较大时,主成分分析方法就有用武之地了
- 主成分分析法:线性变换进行降维,将多指标转化为几个不相关的综合指标(主成分),每个主成分都是原始变量的线性组合,主成分几乎保留原始变量的全部信息,达到抓住问题实质的目的
- 因子分析:主成分的推广,不是对原始变量的取舍,而是根据原始变量和信息进行重新组合,找出变量的公共因子,化简数据
神经网络
-
一般有两种神经网咯,bp神经网络(有导师学习方式训练,误差逆传播算法),RBF神经网络(有很强的逼近能力,分类能力,学习速度)
-
一般使用RBF,更简单智能,相比BP神经网络要自定义神经元个数,RBF会在训练过程中自适应取定神经元个数,RBF代码参考《数学建模算法与应用》,最后的误差分析参考《MATLAB与机器学习》
-
RBF神经网络只有一个参数可调,《数学建模算法与应用》中这个参数是缺省值,参数值越小误差越大,但是当这个参数值达到1e5数量级的时候,误差也很大,这个参数要根据实际情况取合适的值。
