并发编程
在早期,大多数计算机只用一个处理组件,称为处理器或中央处理器(CPU)。并行算法是一种计算方法,它会尝试使用多个执行并行算法的处理器更好地解决问题。
并行计算导论
顺序算法与并行算法
----顺序算法---- ----并行算法----
begin cobegin
step 1 task 1
step 2 task 2
... ...
step n step n
end coend
在cobegin算法中,所有的程序都是并行执行的
并行性与并发性
在单CPU系统中,一次只能执行一个任务。在这种情况下,不同的任务只能并发执行,即在逻辑上并行执行。在CPU系统中,并发性是通过多任务处理来实现的。
线程
线程的由来
早期操作系统没有线程只有进程。由于技术进步以及计算机技术的发展,cpu的性能突飞猛进,从20MHz发展到了2GHz以上,从单核CPU发展到了多核CPU,性能提升了上千倍。为了充分发挥cpu的性能、提升资源利用率同时为了解决进程笨重的调度问题于是就演进出了进程内部调度方式-线程。
定义:线程是指“进程代码段”的一次顺序执行流程。线程是CPU调度的最小单位。一个进程可以有一个或多个线程,各个线程之间共享进程的内存空间、系统资源(如用户id、打开的文件描述符和信号等)进程仍然是操作系统资源分配的最小单位。
创建某个进程就是在一个唯一地址空间创建一个主线程。某进程的所有线程都在该进程的相同地址空间中执行,但每个线程都是一个独立的执行单元。
线程的优点
(1)与进程相比,线程创建和切换的速度更快。进程的上下文复杂而庞大,复杂性主要来源于管理进程映像的需要。创建新的进程,操作系统必须为其分配内存并构建页表(用来跟踪每个进程的页面)。但是如果在某个进程中创建线程,操作系统不必为新的线程分配内存和创建页表,因为线程和进程共用一个地址空间。
(2)线程的响应速度更快。一个进程只有一个执行路径——当某个进程被挂起时,整个进程都将停止执行;相反,当某个线程被挂起时,同一进程中的其他线程可以继续执行。
(3)线程更适合并行计算。并行计算的目标是使用多个执行路径更快地解决问题。基于分治原则(二叉树查找和快速排序)的算法经常表现出高度的并用性,可以通过并行来提高计算速度。在进程中,各进程间不能有效共享数据,因为它们的地址空间不同(可用进程间通信(IPC)来交换数据或者其他方法),但是线程共享同一地址空间中的所有(全局)数据。因此,使用线程编写并行执行的程序比使用进程更简单、自然。
线程的缺点
(1)由于地址空间共享,线程需要来自用户的明确同步。
(2)许多库函数可能对线程不安全。任何使用全局变量或依赖于静态内存内容的函数,线程都不安全。
(3)在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
线程操作
线程的执行轨迹与进程类似。线程可在内核模式或用户模式下执行。
在用户模式下,线程在进程的相同地址空间中执行,但每个线程都有自己的执行堆栈。线程是独立的执行单元,可根据操作系统内核的调度策略,对内核进行系统调用,变为挂起、激活以继续执行等。
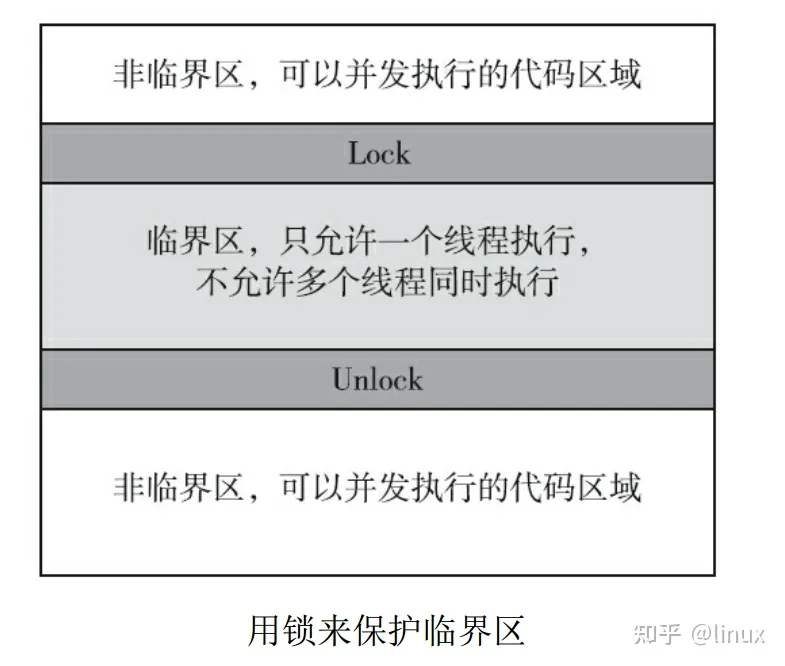
较好地解释了临界区和非临界区
线程管理函数
创建线程
使用pthread_create()函数
int pthread_create (pthread_t *pthread_id, pthread_attr_t *attr, void *(*func)(void *), void *arg);
如果成功返回0,如果错误返回错误代码。
- pthread_id是指向pthread_t类型的指针。它会被操作系统内核分配的唯一线程ID填充。线程可通过pthread_self()函数来获得自己的ID,比如:
pthread_t tid=pthread_self()。在Linux中,pthread_t类型被定义为无符号长整型,因此线程ID可以打印为%lu。 - attr是另一种不透明数据类型的指针,它指定线程属性。如果attr参数为NULL,将使用默认属性创建线程。
- func是要执行的新线程函数入口地址。
- arg是指向线程函数参数的指针,可写为 void *func(void *arg)。
可用函数size_t pthread_attr_getstacksize()来获取线程默认堆栈的大小。
线程ID
是一种不透明的数据类型(取决于实际情况)。使用pthread_equal()函数对线程ID进行比较。
int pthread_equal(pthread_t t1,pthread_t t2);
返回值:不同线程返回0,否则返回非0。
线程终止
线程可以调用函数进行终止
int pthread_exit(void *status);
返回值:0退出值表示正常终止,非0值表示异常终止
线程连接
一个线程可以等待另一个线程的终止,通过函数终止线程的退出状态。
int pthread_join (pthread_t thread, void **status ptr);
返回值:以status_ptr返回。
线程示例程序
用线程计算矩阵的和
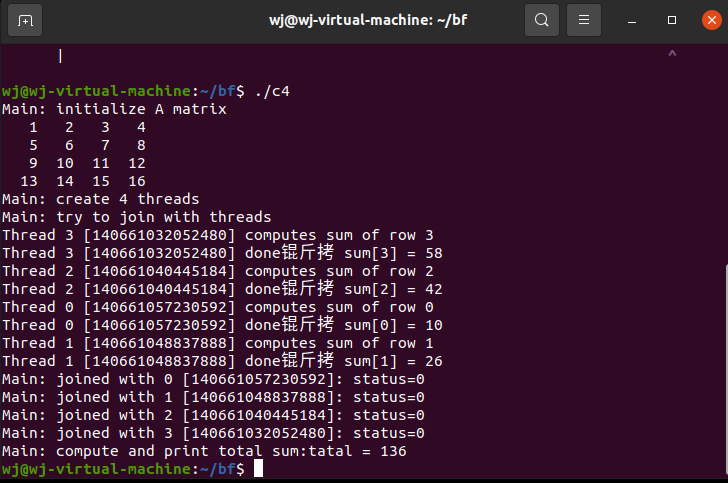
计算一个NXN整数矩阵中所有元素的和。每个工作线程计算不同行的部分和,并将部分和存入全局数组 int sum[N]的相应行中。当所有的工作进程计算完成后,主线程继续进行计算,将每个线程部分和相加。
完整代码如下:
/**** C4.l.c files compute matrix sum by threads****/
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define N 4
int A[N][N], sum[N];
void *func(void *arg)
{
int j, row;
pthread_t tid = pthread_self(); // get thread ID number
row = (int)arg; // get row number from arg
printf("Thread %d [%lu] computes sum of row %d\n", row, tid, row);
for (j=0; j<N; j++)
{
sum[row] += A[row][j];
}
printf("Thread %d [%lu] done锟斤拷 sum[%d] = %d\n",row, tid, row, sum[row]);
pthread_exit((void*)0); // thread exit: 0=normal termination
}
int main (int argc, char *argv[])
{
pthread_t thread[N]; // thread IDs
int i, j, r, total = 0;
void *status;
printf("Main: initialize A matrix\n",N);
for (i=0; i<N; i++)
{
sum[i] = 0;
for (j=0; j<N; j++)
{
A[i][j] = i*N + j + 1;
printf("%4d" ,A[i][j]);
}
printf("\n");
}
printf("Main: create %d threads\n", N);
for(i=0; i<N; i++)
{
pthread_create(&thread[i], NULL, func, (void *)i);
}
printf("Main: try to join with threads\n");
for(i=0; i<N; i++)
{
pthread_join(thread[i], &status);
printf("Main: joined with %d [%lu]: status=%d\n",i, thread[i], (int)status);
}
printf("Main: compute and print total sum:");
for (i=0; i<N; i++)
{
total += sum[i];
}
printf("tatal = %d\n", total);
pthread_exit(NULL);
}
这里编译要注意,因为需要定向查找pthread库,所以编译命令为gcc c4.c -o -c4 -pthread
编译结果如下:
用线程快速排序
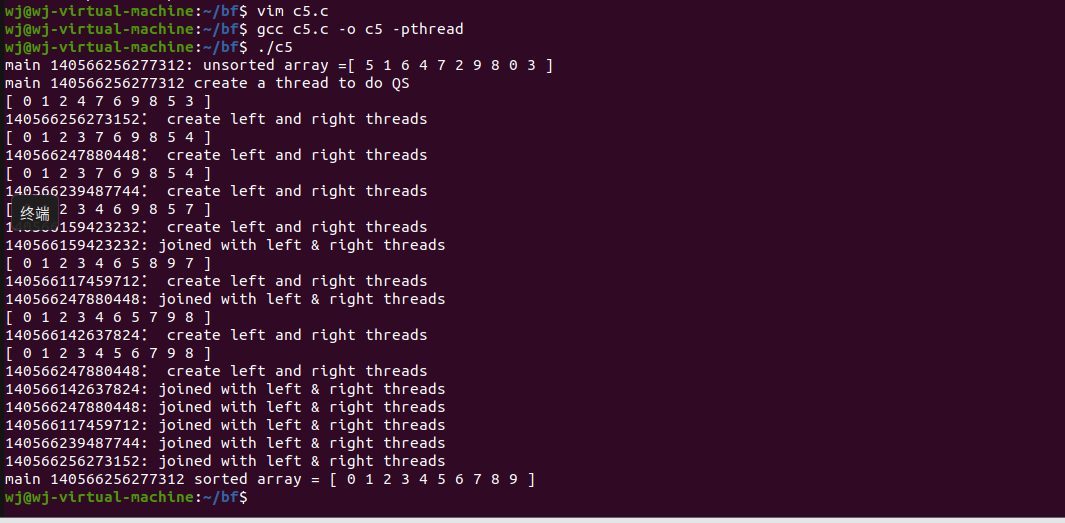
程序启动时,它作为进程的主线程运行。主线程调用qsort(&arg),实现N个整数的快速排序。在qsort中,首先选择一个基准整数,数组整数被分为两部分,左边的部分小于这个基准元素,右边的大于。这个程序会创建两个子线程来对两个部分分别排序。
编译结果如下:
进程同步
当多个线程试图修改同一共享变量或数据结构时,如果修改结果取决于线程的执行顺序,则称为竞争条件。在并发程序中,绝不能有竞态条件,否则结果可能不一致——线程需要同步。可应用于内核模式和用户模式。
互斥量
pthread_mutex_lock(&m);
access shared data object;
pthread_mutex_unlock(&m);
最简单的同步工具是锁,它允许执行实体仅在有锁的情况下才能继续执行。锁在pthread中被称为互斥量——相互排斥。互斥变量是用pthread_mutex_t类型声明的。
线程使用互斥量来保护共享数据对象。
当线程执行pthread_mutex_lock(&m)时,如果互斥量被解锁,它将封锁互斥量,称为互斥量的所有者并继续执行,否则,它将被阻塞并在互斥量等待队列中等待。只有获取了互斥量的进程才能访问共享数据对象。一次只能由一个执行实体执行的一系列执行通产称为临界区。在pthread中,互斥量用来保护临界区。临界区内在任何时候最多只能有一个线程。
在解锁某互斥量时,如果互斥量等待队列中没有阻塞的线程,它就会解锁该互斥量,这时,互斥量没有所有者。否则,它从互斥量等待队列中解锁等待进程,使其称为新的所有者,互斥量继续保持封锁。
我们运行书中给的互斥代码
运行结果如下:
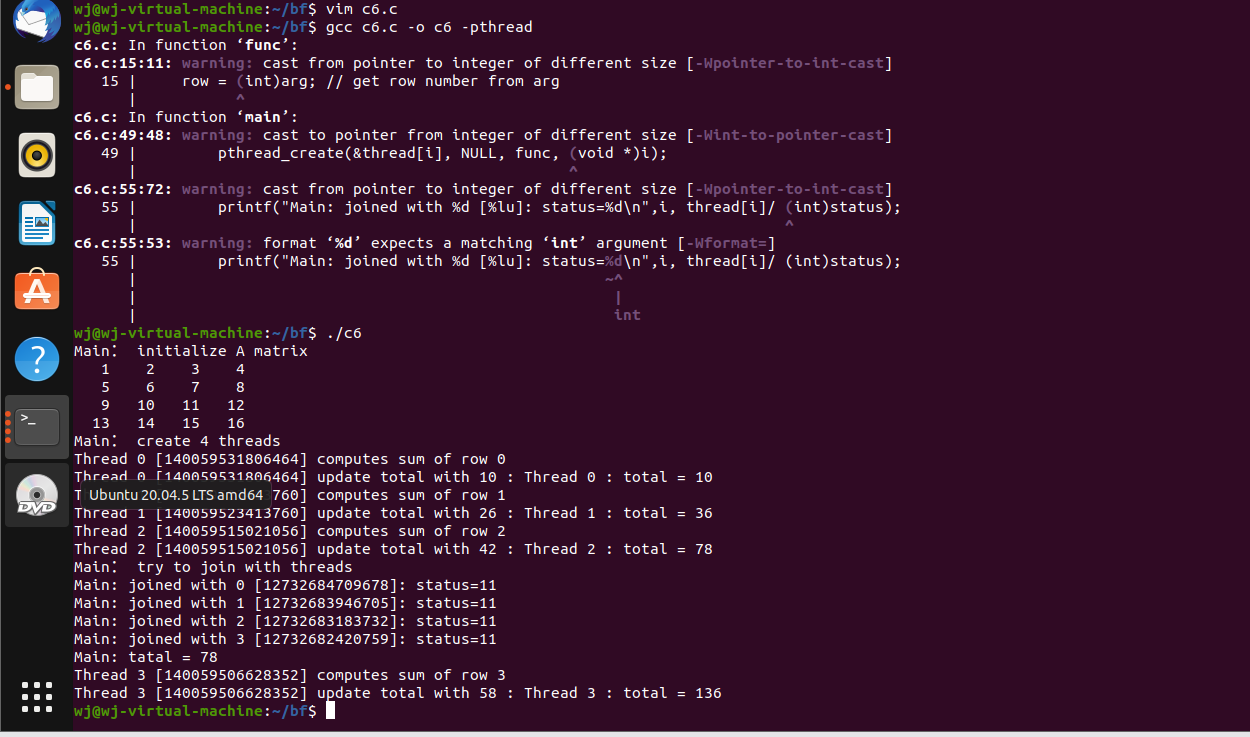
可见,每个工作线程计算每一个部分的部分和,每次只能有一个线程来进行自身数据往总和的相加过程,使用互斥量来保证不会出现竞态。
死锁预防
在任何封锁协议中,误加锁可能会产生死锁问题。在实际系统中,唯一可行的办法是死锁预防,试图在设计并行算法时防止死锁的发生。一种简单的死锁预防方法是对互斥量进行排序,并确保每个线程只在一个方向请求互斥量,这样请求序列中就不会有循环。还可以用条件加锁和退避来预防死锁。
条件变量
作为锁,互斥量仅用于确保线程只能互斥地访问临界区和共享数据对象。条件变量提供了一种线程协作的方法。条件变量总是和互斥量一起使用。当使用条件变量时,线程必须首先获取相关的互斥量。然后,它在互斥量的临界区内执行操作,然后释放互斥量。
条件等待是线程间同步的另一种方法。
如果条件不满足,它能做的事情就是等待,等到条件满足为止。通常条件的达成,很可能取决于另一个线程,** 比如生产者-消费者模型**。 当另外一个线程发现条件符合的时候,它会选择一个时机去通知等待在这个条件上的线程。 有两种可能性,一种是唤醒一个线程,一种是广播,唤醒其他线程。
条件变量本质上是PCB等待队列 + 等待接口 + 唤醒接口。
条件变量的初始化
静态初始化
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
动态初始化
pthread_cond_init(pthread_cond_t *cond,const pthread_condattr_t *attr);
| 参数 | 说明 |
|---|---|
| cond | 条件变量,传递地址 |
| attr | 条件变量属性,一般传入NULL |
条件变量的等待
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
int pthread_cond_timedwait(pthread_cond_t *restrict conpthread_mutex_t *restrict mutex,const struct timespec *restrict abstime);
条件不会无缘无故地突然变得满足了, 必然会牵扯到共享数据的变化。 所以一定要有互斥锁来保护。 没有互斥锁, 就无法安全地获取和修改共享数据。同步并没有保证互斥,而保证互斥是使用到了互斥锁。
pthread_mutex_lock(&m)
while(condition_is_false)
{
pthread_mutex_unlock(&m);
//解锁之后, 等待之前, 可能条件已经满足, 信号已经发出, 但是该信号可能会被错过
cond_wait(&cv);
pthread_mutex_lock(&m);
}
上面的解锁和等待不是原子操作。 解锁以后, 调用cond_wait之前,如果已经有其他线程获取到了互斥量, 并且满足了条件, 同时发出了通知信号, 那么cond_wait将错过这个信号, 可能会导致线程永远处于阻塞状态。 所以解锁加等待必须是一个原子性的操作, 以确保已经注册到事件的等待队列之前, 不会有其他线程可以获得互斥量。
在唤醒之后还需要进行检查条件是否满足,因为唤醒中存在虚假唤醒(spurious wakeup) , 换言之,条件尚未满足, pthread_cond_wait就返了。 在一些实现中, 即使没有其他线程向条件变量发送信号, 等待此条件变量的线程也有可能会醒来。条件满足了发送信号, 但等到调用pthread_cond_wait的线程得到CPU资源时, 条件又再次不满足了。 好在无论是哪种情况, 醒来之后再次测试条件是否满足就可以解决虚假等待的问题。