本周我学习了课本第七章和第八章的内容。
下面是我对这两章内容的总结。
首先是第七章的文件操作
7.1文件操作级别
文件操作分为五个级别,从低到高分别为:
(1)硬件级别
fdisk:将硬盘、U盘或SDC盘分区;
mkfs:格式化磁盘分区;
fsck:检查和维修系统
碎片整理:压缩文件系统中的文件
(2)操作系统内核中的文件系统函数
(3)系统调用:用户模式程序使用系统调用来访问内核函数
open()、read()、lseek()函数都是C语言库函数。每个库函数都会发出一个系统调用,使进程进入内核模式来执行相应的内核函数,例如open可进入
kopen()等。系统调用可让用户读/写多个数据块,这些数据块只是一系列
(4)I/O库函数
C语言提供了一个标准的I/O库函数,提高了运行效率
(5)用户命令
用户可以使用Unix/Linux命令来执行文件操作,而不是编写程序
(6)sh脚本
必须要手动输入命令。sh包含所有的有效Unix/Linux命令,还支持变量和控制语句,比系统调用方便得多。
7.2I/O文件操作
7.3低级别文件操作
各分区可以分为几个逻辑单元,可以格式化为特定的文件系统,称为分区。如果某分区是个扩展类型,则可以再次划分为几个扩展分区。
如下,我们在Ubuntu下创建了一个虚拟磁盘映射文件
7.3.3挂载分区
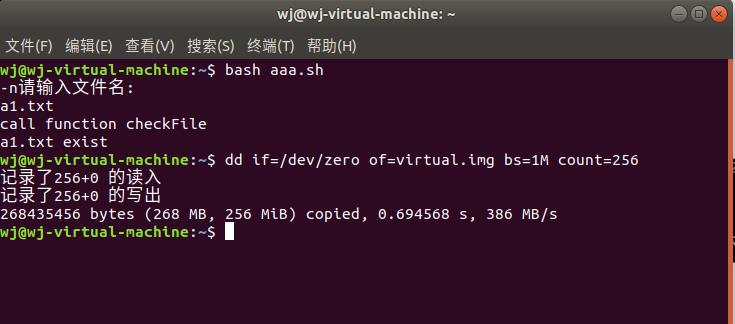
在终端输入:dd if=/dev/zero of=virtual.img bs=1M count=256
dd是将一个一个256个0字节块写入目标文件virtual.img的程序。
运行结果如下:
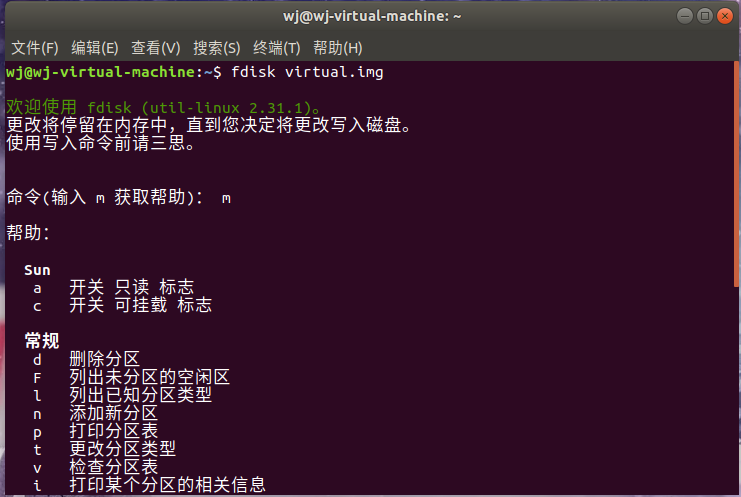
在磁盘映像上运行fdisk:
输入fdisk virtual.img,结果如下图所示:
输入
sudo mkfs.ext4 virtual.img
使用mkfs命令格式化磁盘(我们这里是自己创建的虚拟磁盘镜像)
结果如下图所示:
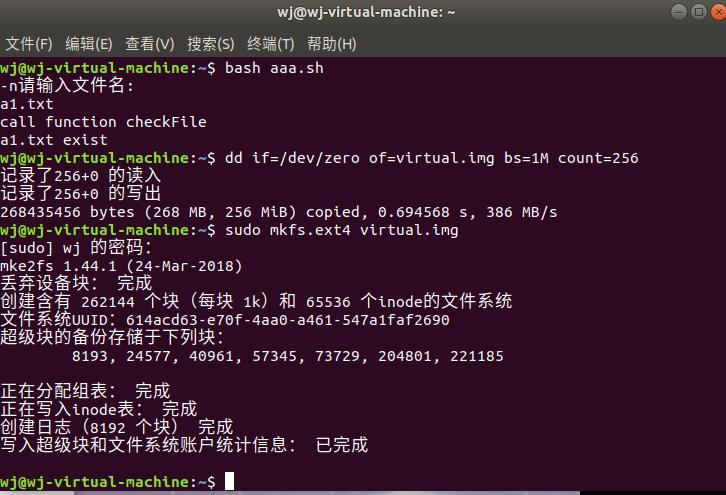
使用mount命令挂载磁盘到目录树上
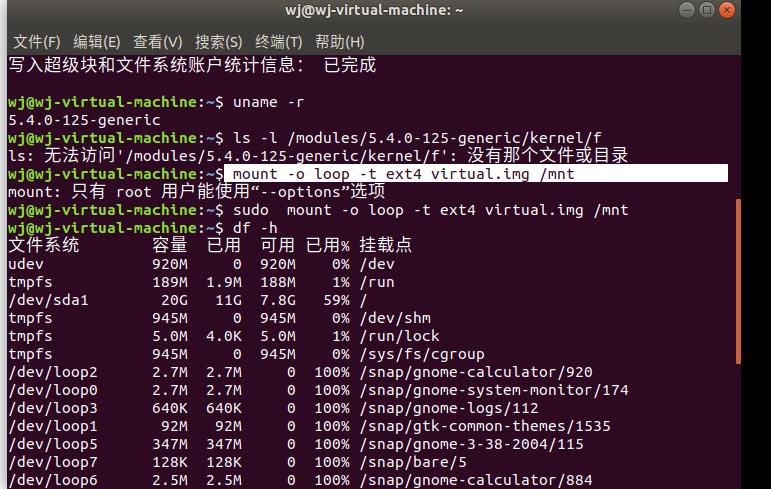
使用fdisk为磁盘分区
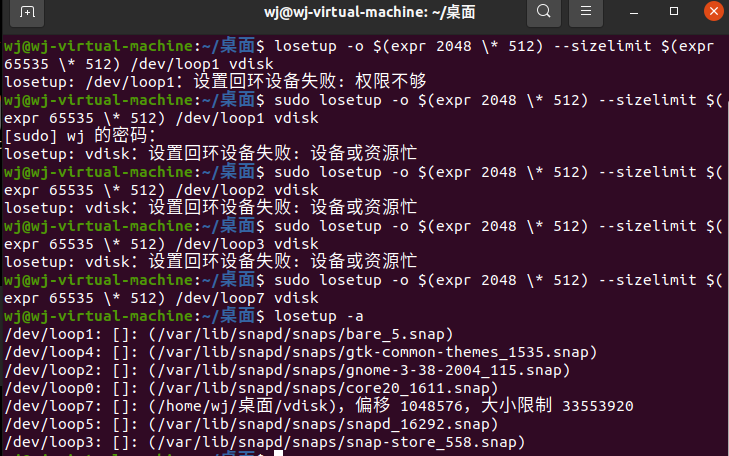
查看所有的loop回环设备
也可以使用losetup -a来查看它们
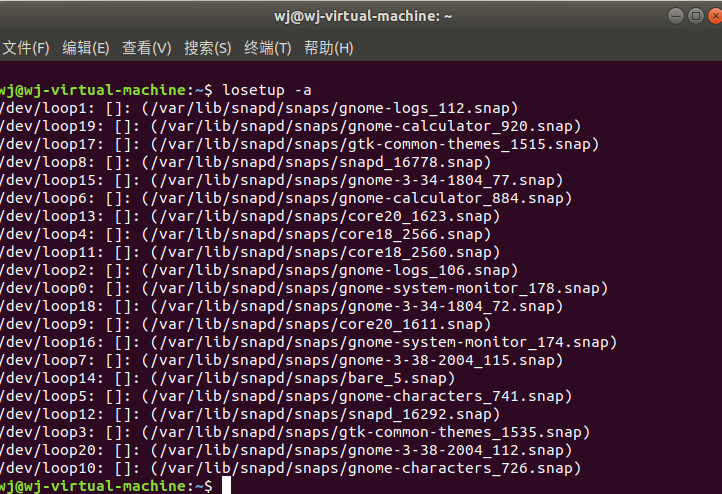
当我输入losetup /dev/loop1时发现提示我设备繁忙,去云班课发现也有同学出现了类似的问题,上网搜查资料后发现,原来是命名的问题,我们只需
要一步步往后递推,寻找空闲的回环设备
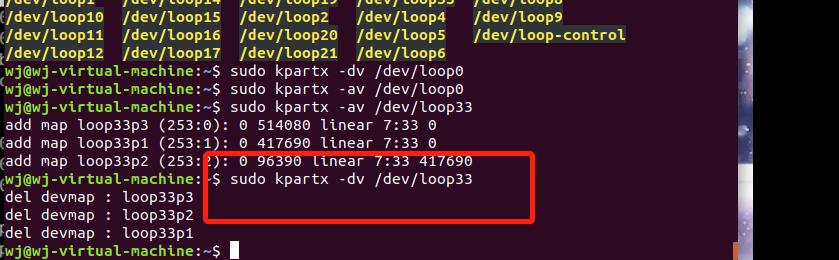
解除设备关联:
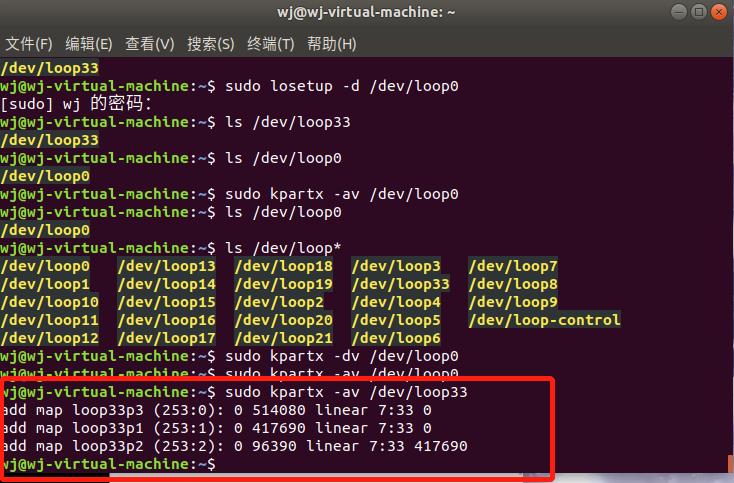
取消映射
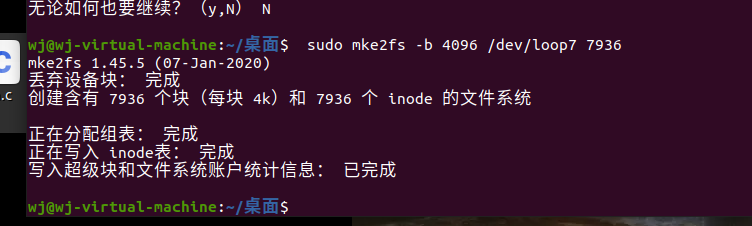
格式化/dev/loop1
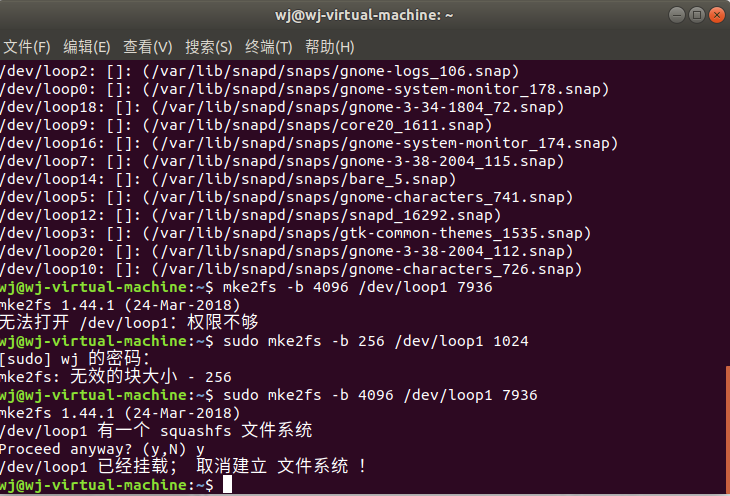
作业195页练习:
sudo mkfs.ext2 /dev/sda1(插叙:这里最好还是用sdb盘去分区,不然会出现很多意外情况)
格式化分区sda1为ext2文件系统类型
https://img2022.cnblogs.com/blog/2167156/202209/2167156-20220921224020654-2097077203.png)
////////插曲/////
由于我的不当操作(没有留意我的虚拟机里没有sdb盘,导致我把sda盘格式化成ext2系统文件格式了!!!!结果我的ubuntu打开时
就黑屏了555////////同学们引以为戒,一定要先分区,再挂载,不然会出现非常严重的后果————比如C整个盘格式化。。。
终于一番折腾我重装了ubuntu操作系统。。。继续这周的学习
终于新建了一个虚拟机~
在第七章学习超级块时,我对这块的知识非常迷,于是上网找了些比较浅显易懂和的解释:
Linux硬盘组织方式为:引导区、超级块(superblock),索引结点(inode),数据块(datablock),目录块(diredtory block).
其中超级块中包含了关于该硬盘或分区上的文件系统的整体信息,如文件系统的大小等;
超级块后面的数据结构是索引结点(inode,我们之后学到的),它包含了针对某一个具体文件的几乎全部信息,如文件的存取权限、所有者、大小、建立时间以及对应的目录块和数据块等;
数据块是真正存储文件内容的位置.
但是索引结点中不包括文件的名字,文件名是放在目录块里的.目录块里包含有文件的名字以及此文件的索引结点编号.
查看linux上的超级块信息:
先输入df查看我们的磁盘使用及挂载情况,可见我的磁盘sda盘已经分区
了,还有一个添加的虚拟磁盘sdb盘。
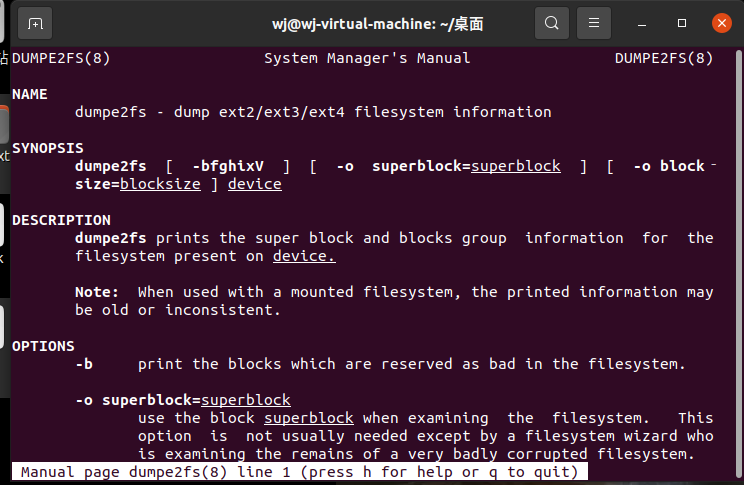
源自:https://blog.csdn.net/weixin_39675513/article/details/116702394
输入dumpe2fs /dev/sda5查看
发现数据量很大
第八章 使用系统调用进行文件操作
8.1系统调用
以两种不同的模式运行,即内核模式和用户模式,用户模式的权限非常有限,不能执行任何需要特殊权限的操作,有特殊权限的操作必须在Kmode下执行。
系统调用必须由程序自身发出,用法和普通函数一样
int syscall(int number,....)
syscall() 执行一个系统调用,第一个参数是系统调用编号,后面的参数是对应内核函数的参数。
系统调用可让进程从用户模式切换到内核模式,内核的系统调用处理程序根据系统调用编号number将调用路由到一个相应的内核函数。当进程结束执
行内核函数后会返回到用户模式并得到所需结果;如果失败,错误编号会记录在errno中,可以通过strerror获取错误对应的描述字符串。成功返回
=0,失败返回-1。
8.2系统调用手册页
大多数unix/linux中,在线手册页保存在/usr/man/目录中。在ubuntu linux中,则保存在/usr/share/man中。
下面列举了在终端输入man 相关命令的示意图:
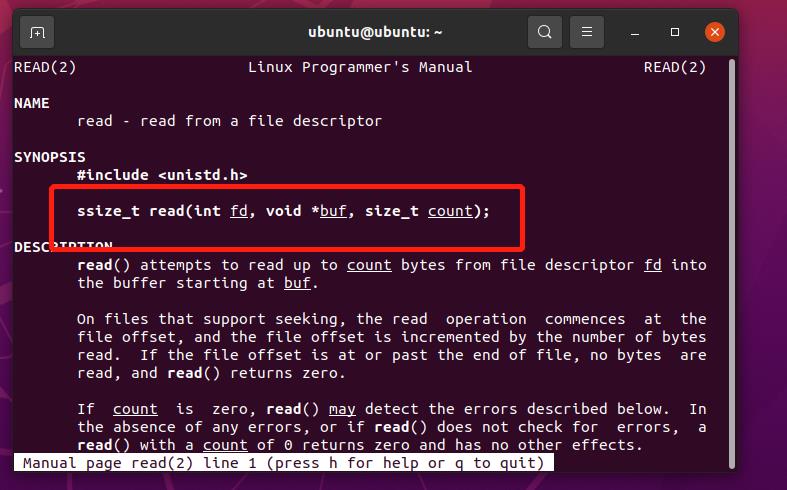
使用man 2 stat命令:
使用man 2 read命令
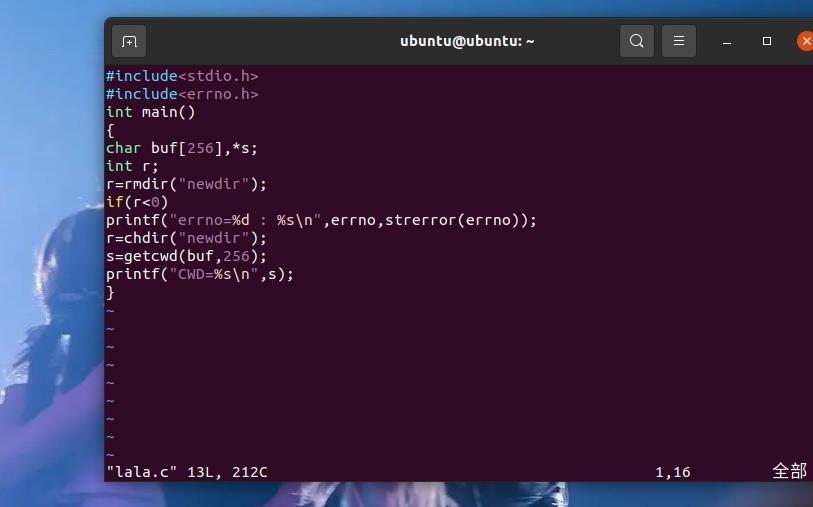
在运行书上给定的代码时,我的输出出现了提示“段错误”的情况,经上网搜索后发现原来是函数访问的内存超过了应有的范围

运行代码,成功创建一个文件夹newdir(实现了命令行语句 mkdir newdir)
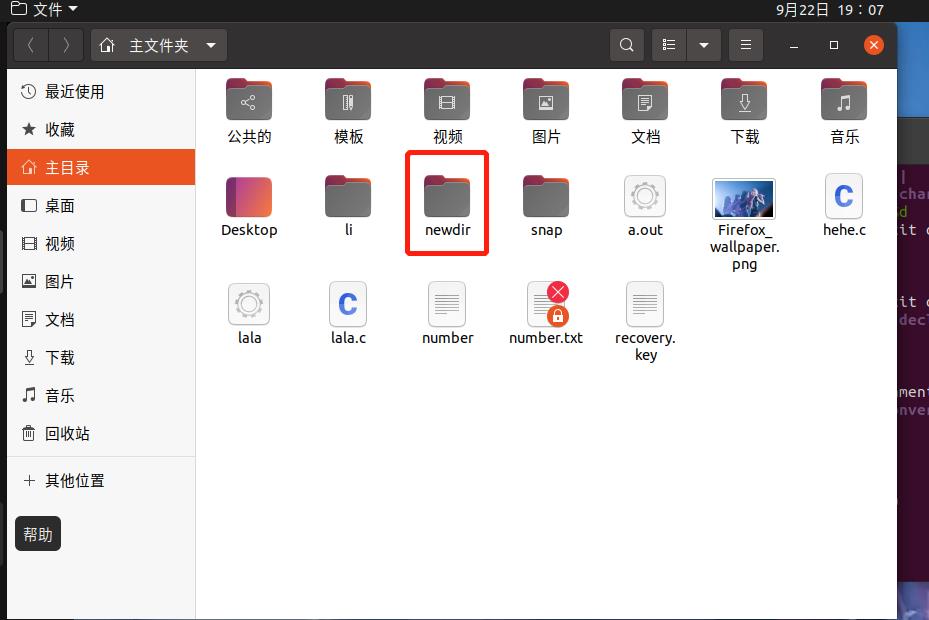
关于mkdir语句中的0766我不是很懂,上网查找资料后有了一定的了解

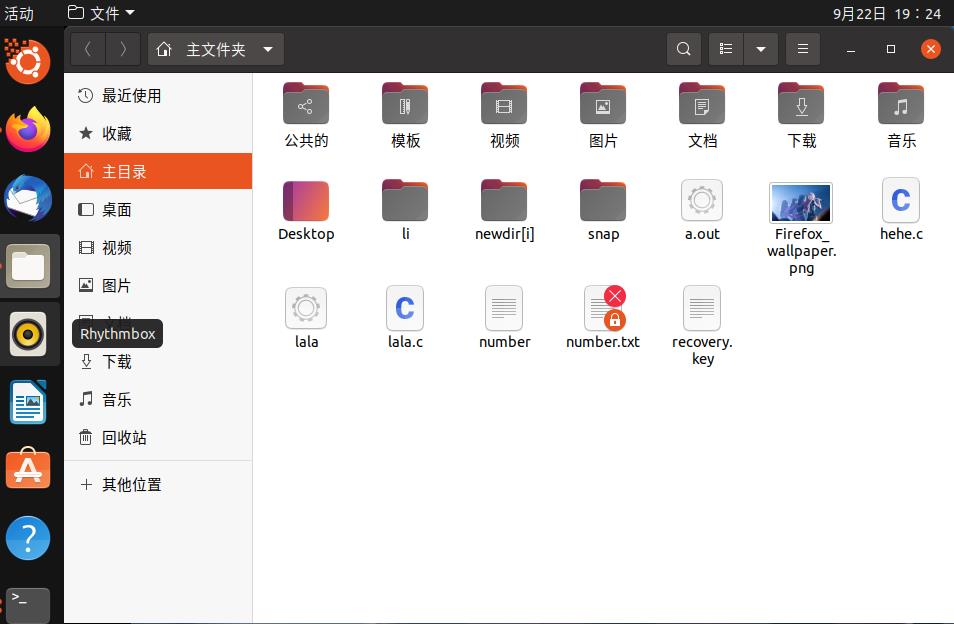
接下来我对代码进行了改动,使刚刚创建的newdir删除。(期间我又另创了一个newdir[i])
结果如下:已删除
8.3链接文件
Unix/Linux允许使用不同的路径名来表示同一个文件。这些文件都叫做LINK(链接)文件。有两种类型的链接,即硬链接和软连接或符号链接
①硬链接: ln oldpath newpath 对应的系统调用是 link(char *oldpath,char *newpath)
对任何一个链接或者源文件进行修改,都会影响到其他的文件,但是删除链接文件,不会影响其他链接文件的访问。
inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,如果给该inode增加一条硬链接,“链接数”会增加1。反过来,删除一个文件名,就
会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
创建硬链接:
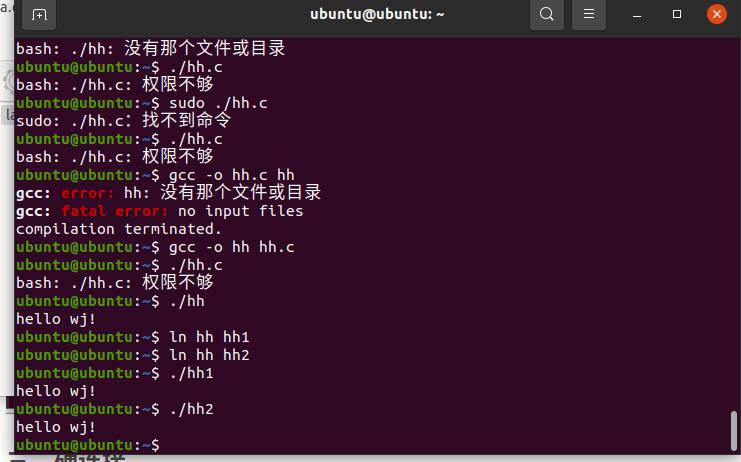
运行硬链接:
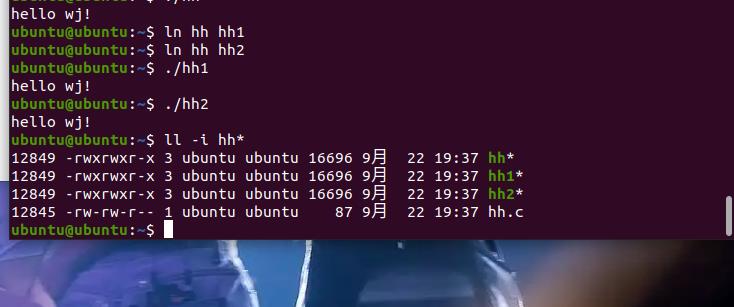
硬链接文件会共享文件系统中相同的文件表示数据结构(索引节点)。文件链接数会记录链接到同一索引节点的硬链接数量。硬链接仅适用于非目录文件。
系统调用:
unlink(char *pathnmae) 会减少文件的链接数
如果链接数变为0,文件会被完全删除。————最好多创建几个到文件的硬链接
②符号链接文件 ln -s oldpath newpath
对应的系统调用是:symlink(char *oldpath char *newpath)
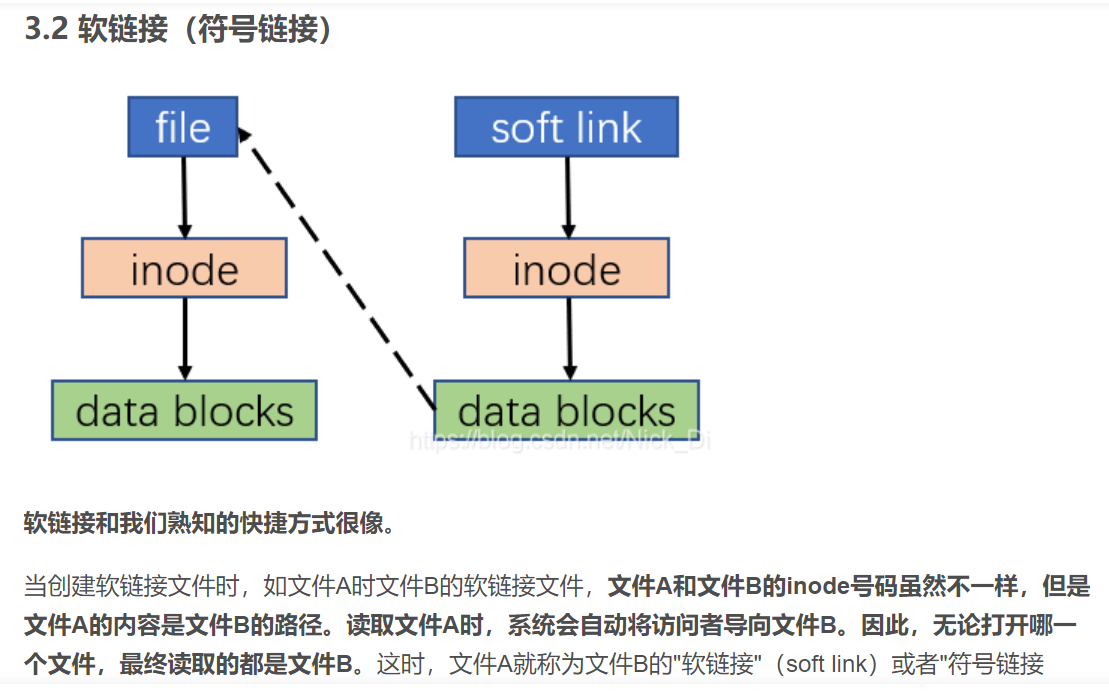
看了这个解说,我觉得软链接有点像存放指针(地址)的数组,hh。
hh3.c文件内容:
创建一个hh5.c软链接到hh3.c: 并用ls查看桌面文件内容,可以看到hh5链接到了hh3文件
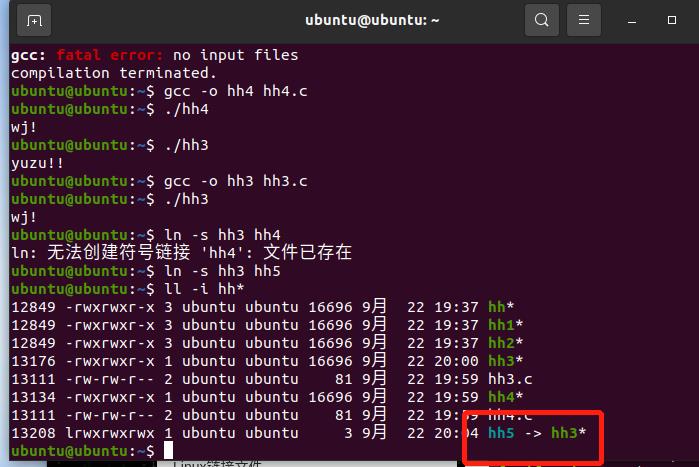
软链接适用于任何文件,包括目录。
软链接可通过较短的名称访问一个较长的路径名称;还可以将标准动态库名称链接到实际版本的动态库。
(1)软链接一个缺点是目标文件可能不复存在了,用ls命令查看深色RED,看是否链接已经断开。
(2)如果hh->/a/b/c是软链接,用open("hh",0)西永调用将打开被链接的文件/a/b/c,而不是链接文件(hh)本身。所以open()/read()系统调用不能读
取软链接文件,必须要用readlink系统调用。
8.4stat系统调用
(1)inode
关于inode的相关学习内容转载自原文链接:https://blog.csdn.net/Nick_Di/article/details/118068557
在 Linux 中 inode 号(即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻
找正确的文件数据块。
文件存储在硬盘上,硬盘的最小存储单位叫做“扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)
操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。**这种由多个扇
区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成一个block**。
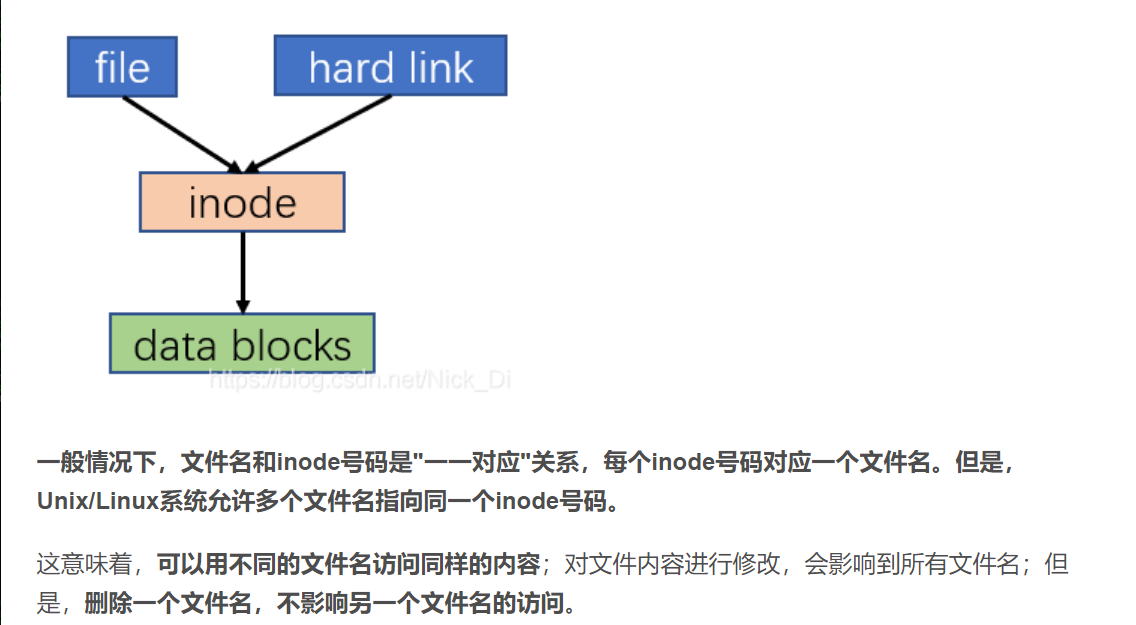
文件数据都储存在“块”中,那么很显然,我们还必须找到一个地方**储存文件的“元信息”,比如文件的创建者、文件的创建日期、文件的大小等等。这种
储存文件元信息的区域就叫做inode,中文译名为"索引节点"**。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息,如文件数据block的位置、blocks块数、文件内容上一次变更时间等等。可以
说,除了文件名以外的所有文件信息,都存在inode之中。
操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
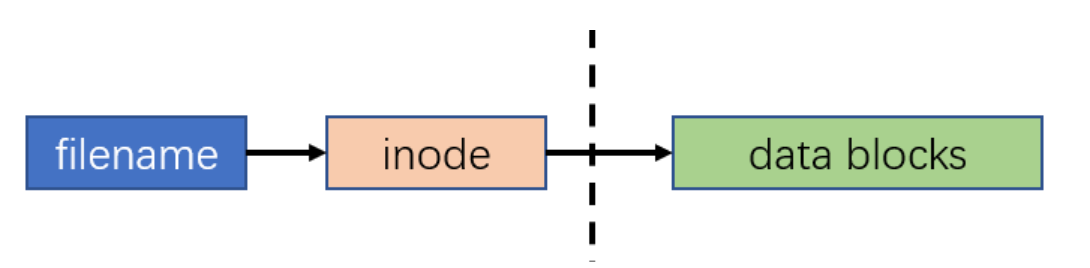
每个inode节点的大小,一般是128字节或256字节。Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是
inode号码便于识别的别称或者绰号。
文件名、inode、block三者关系如下图所示:
用stat xx.txt查看文档的状态,如下图所示:
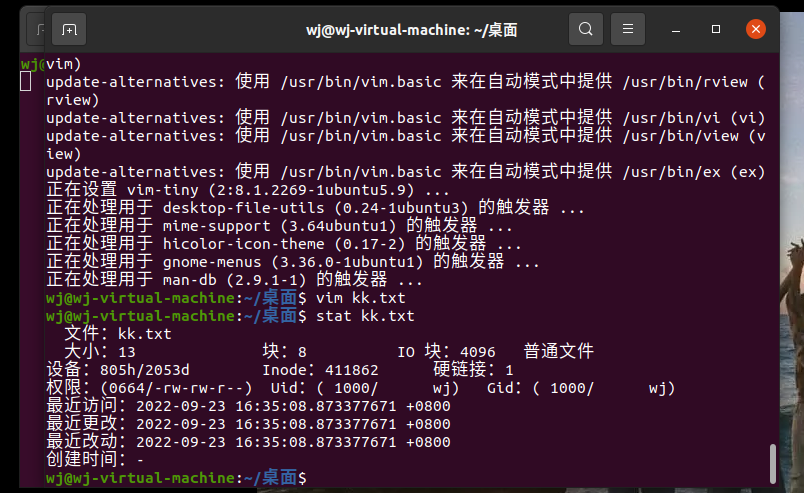
stat的结构体:
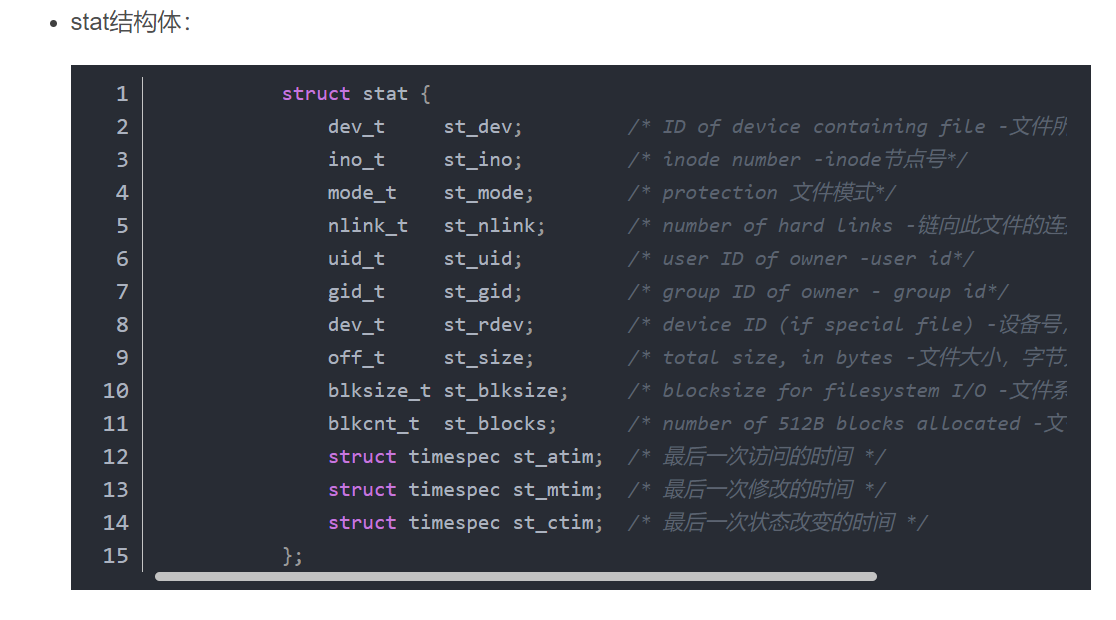

原文链接为:https://blog.csdn.net/Nick_Di/article/details/118068557,大家有兴趣的可以直接跳转查看,我觉得讲的很清楚。
8.5opendir-readdir函数
Linux下opendir()、readdir()和closedir()这三个函数主要用来遍历目录。在使用这三个函数前必须先包括以下两个头文件:
#include <sys/types.h>
#include <dirent.h>
opendir函数的原型为:
DIR *opendir(const char name);它返回一个DIR类型(类似于fp指针),是一个句柄,句柄要传给readdir()函数的参数即可。(传入name路径,成功则返回非空DIR
指针,否则返回NULL。)
readdir函数的原型为:
struct dirent readdir(DIR dir);看它的参数就知道该参数是opendir函数返回的句柄,而该函数的返回值是struct dirent 类型:
struct
dirent {
ino_t d_ino; / inode number /
off_t d_off; / offset to the next dirent /
unsigned short d_reclen; / length of this record /
unsigned char d_type; / type of file /
char d_name[256]; / filename */
};
closedir函数的原型为:
int closedir(DIR *dir);
8.6 ls程序
课本上216页的代码可以让我们更加清楚地明白ls系统调用的过程
8.7 open-close-lseek系统调用
- open:打开一个文件进行读、写、追加:
int open(char *file,int flags,int mode);
会返回一个进程最小的文件描述符,用于后续的open();
write(),lseek(),close()等的系统调用。
file:文件的路径;
flags:打开的方式;有下列几种打开方式:

此外还有搭配使用的几种方式:
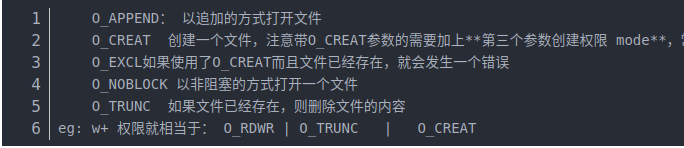
mode:创建权限, eg:0664;
- close:关闭打开的文件描述符:
int close(int fd);
- read:读取打开的文件描述符:
int read(int fd,char buf[],int count);
fd:文件描述符,标识要读取的文件。如果为0,则从标准输入读数据。类
似于scanf()的功能;
文件描述符:系统调用IO接口的操作句柄,为一个整数,在系统中唯一标
识文件。程序启动默认会打开的三个文件描述符:
0:标准输入
1:标准输出
2:标准错误
*buf:缓冲区,用来存储读来的数据
count:要读取文件的长度
返回值int:成功则返回实际读到的数据长度,失败-1
- write:写入打开的文件描述符:
int write(int fd,char buf[],int count);
- lseek:将文件描述符的字节偏移量重新定义为偏移量:
int lseek(int fd,int offset,int whence);
fd:打开的打开文件描述符
offset:偏移量
whence:相对起始位置

返回值:成功返回跳转后相对于文件起始处的偏移量。若跳转到文件末尾可获得文件长度。
- umask:设置文件创建掩码:文件权限为(mask&~umask)
编写简单的程序实现文件简单的打开、写入、关闭
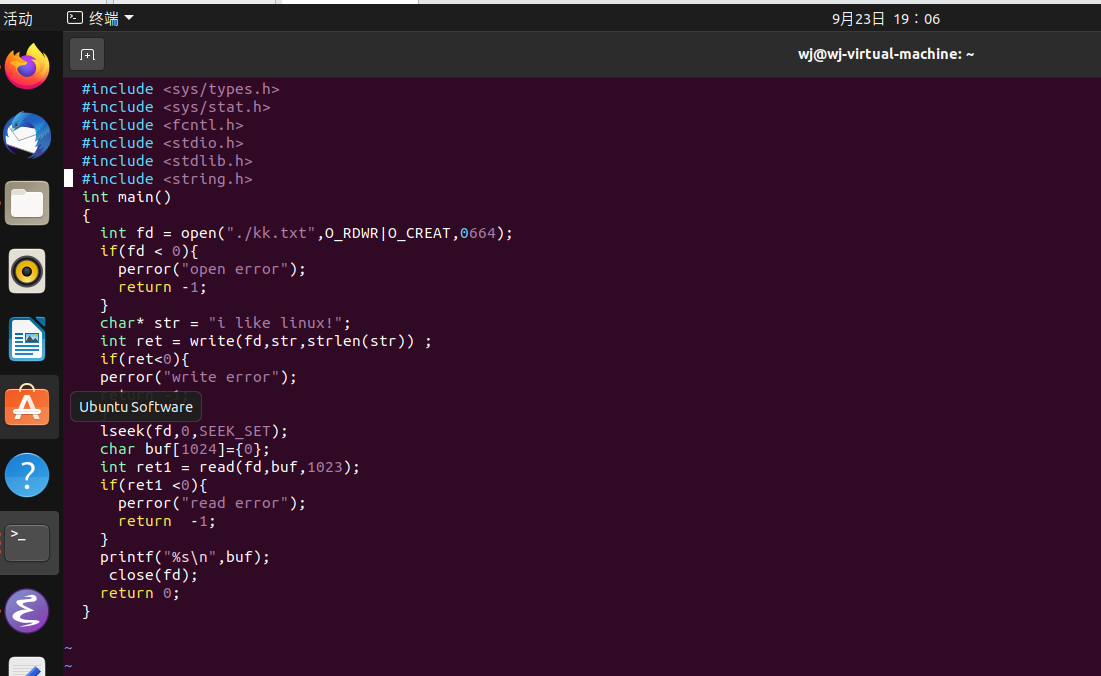
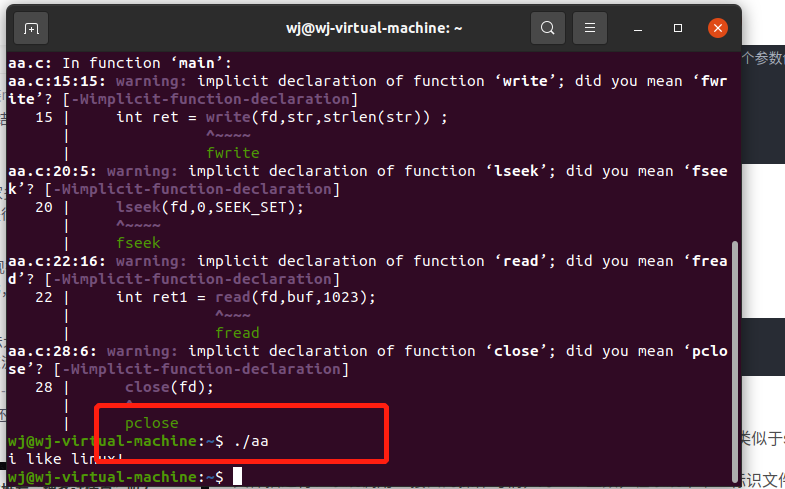
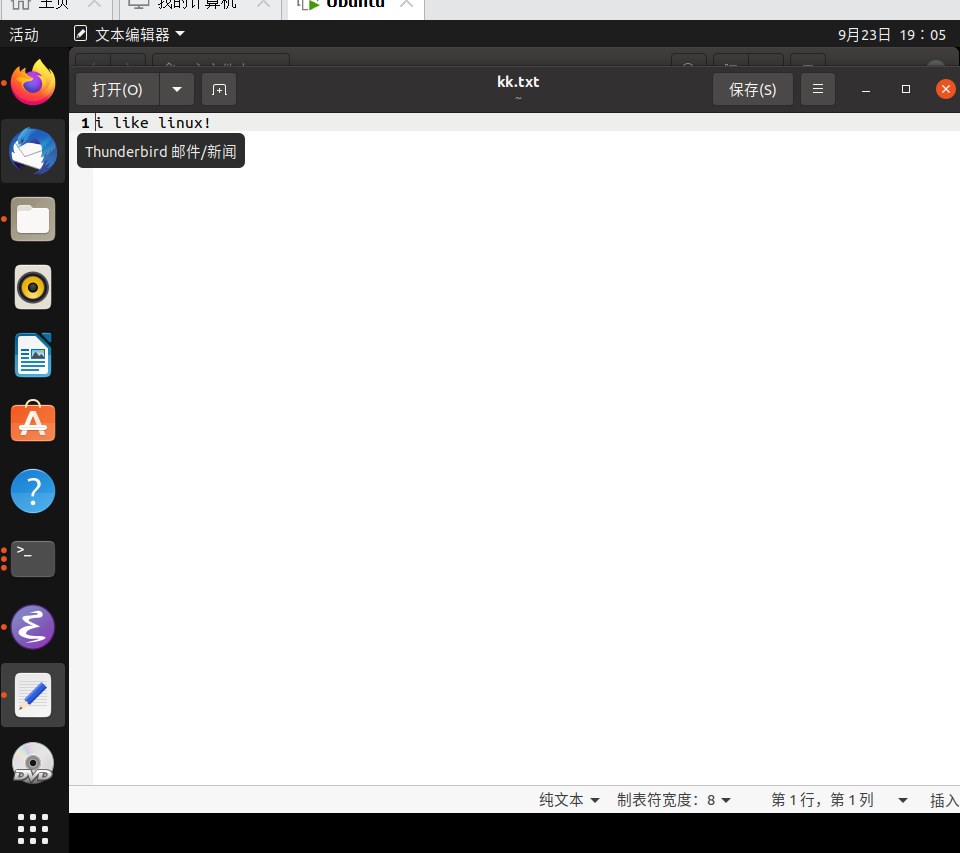
可见显示出了i like linux!的字样
附:
关于在ubuntu里增加一个sdb盘的操作,可以在sdb盘进行一系列linux操作实验:
添加sbd盘后如下图所示:
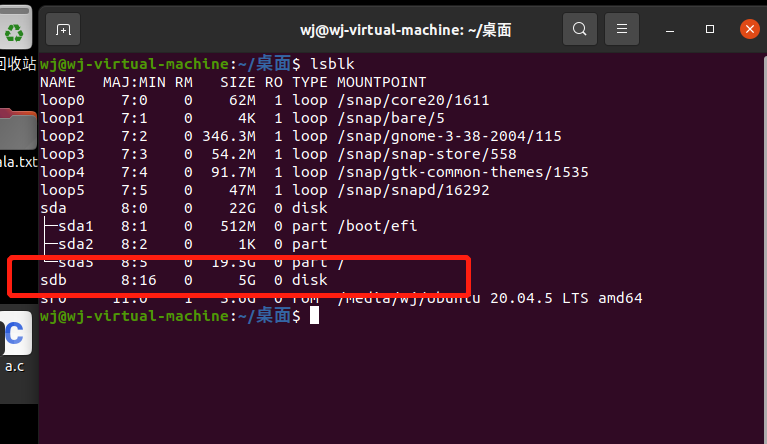
详细操作方法见:https://blog.csdn.net/yueni_zhao/article/details/126240181
挂载分区