一、组员职责分工
算法:庄锡荣,林鑫灿
前端:许煌标,蔡峰,吴珂雨
信息整理:林晓锋,陈珊珊,侯雅倩
博客:陈珊珊,王钟贤
二、github提交日志

三、程序运行截图
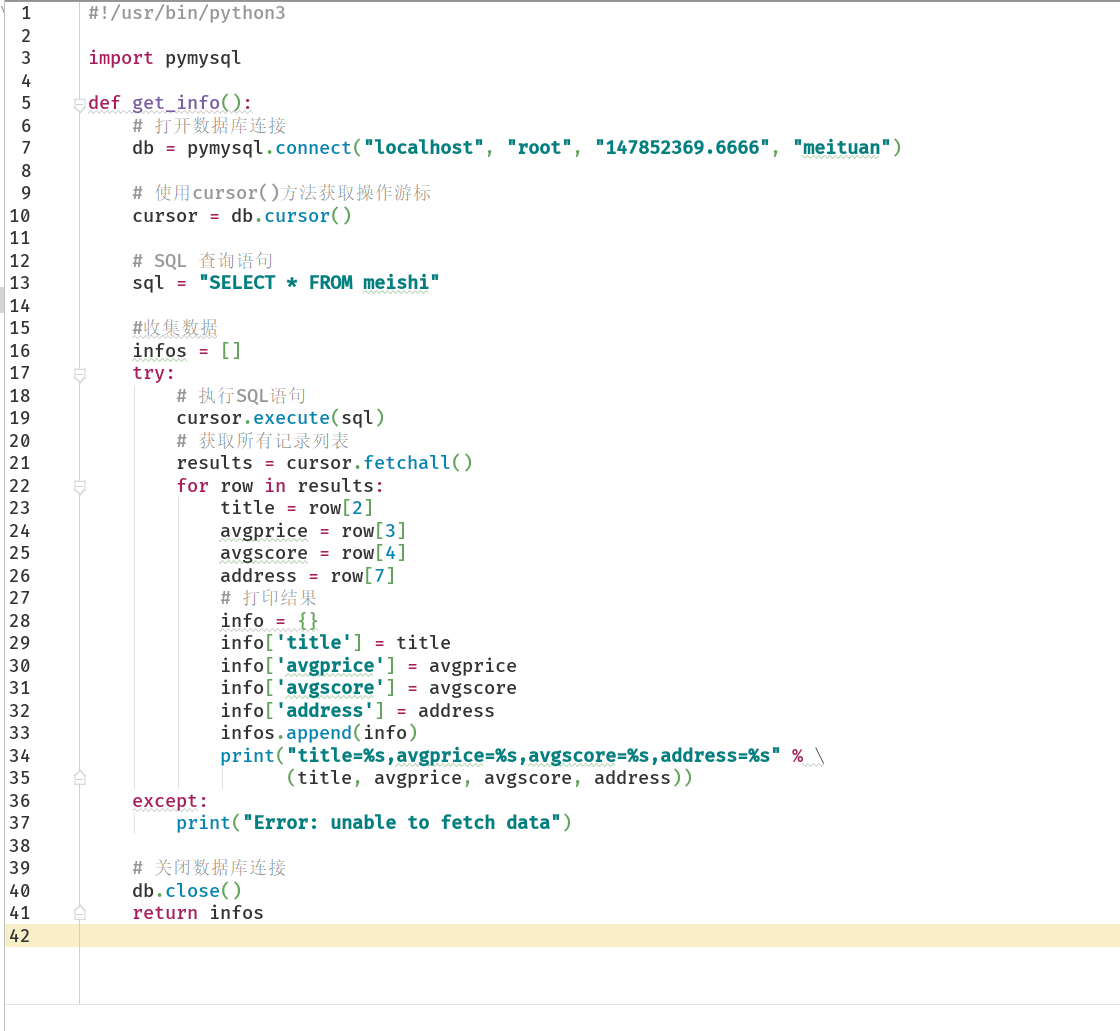
运行中爬取到的部分信息

数据库中的部分信息

程序部分代码
配置模块
主要模块

接口模块
四、程序运行环境
python3
五、GUI界面
主界面

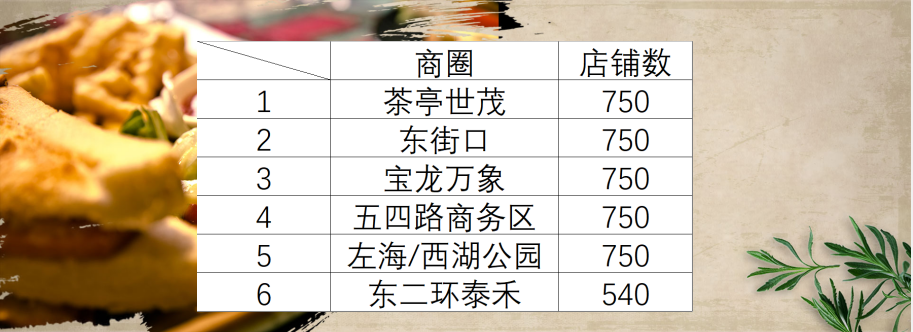
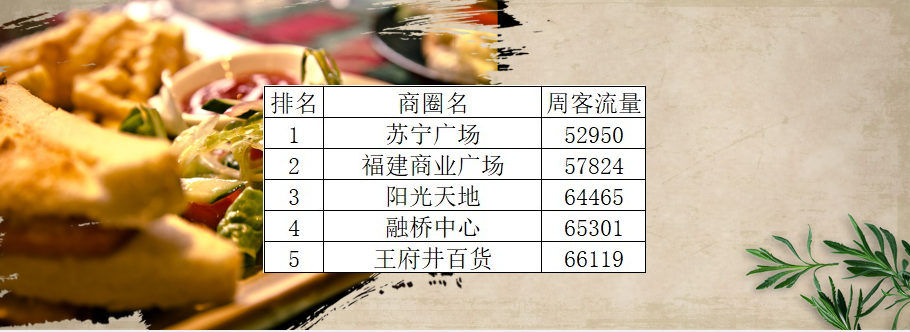
最火商圈功能

最佳美食聚集地
潮流衣室
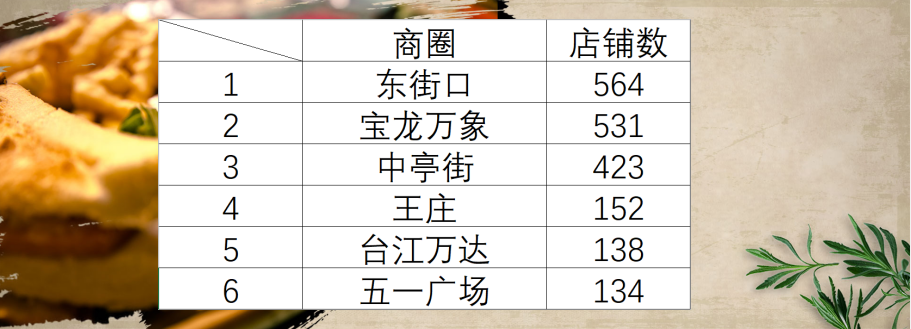
性价比优选餐厅
50以下价位

50-100价位

100-200价位

200以上价位

附加题1:最有潜力商圈

附加题3:冷清商圈排行榜
附加题3:踩坑店铺

六、基础功能实现
首页为菜单页面,上面有4个按纽分别对应4个基础评测目标
- 按钮1:福州最受欢迎的商圈,根据人气排行,显示排行第一的商圈
- 按钮2:福州最佳美食餐厅,根据人均消费分类,分别列举出人均消费50以下,50-100,100-200,200以上的性价比前5的餐厅
- 按钮3:福州最佳美食聚集地,根据评价,显示好评最多的商圈
- 按钮4:福州服饰类综合评分最高的商圈,根据服饰类综合评分,显示综合评分最高的商圈
附加测评页面
- 页面1:最有潜力商圈分析
- 页面2:冷清商圈排行榜
- 页面3:踩坑店铺分析
七、鼓励有想法且有用的功能
- 增设踩雷排行榜,告诉顾客哪些店性价比不是那么的高,需慎重考虑
- 就目前的形势来看,网红店的人气还是很高,因此可以出个功能根据评价汇总分析列举出不值得去的网红店
- 可以增设值得玩的地方或商圈,并列出TOP排行
- 根据用户平时点击查询,做出个性分析,自动推荐感兴趣的商家
- 向用户推荐附近的人/爱好相似的人浏览最多的信息
八、遇到的困难及解决办法
组长庄锡荣:
遇到的困难:
遇到挺多困难的,第一点就是对组员工作的不好分配,因为安排的问题很多人没有发挥出特长:第二点就是关于爬虫的知识了解的不多,由于早上多人同时用校园网使得大众点评爬虫对本ip失效,使工作停滞了很长一段时间。
解决方法:
解决方法就是多听听组员想法,多讨论发表意见;由于爬虫没有使用代理池,最后转向反爬措施没那么强的美团爬取另一部分数据。
组员林鑫灿:
遇到的困难:
对爬虫不够熟悉,准备工作做的不充分,api学的太慢,花了大把时间在熟悉学习各种爬虫工具上,在实际编程过程中遇到了问题,最致命的就是有个关键模块一直接不上api,于是自己就在那里尬住了
解决办法:
经过一番(无用的)尝试,迫不得已转了其他api,效果虽然不如预期,但还算看得过去,勉强解决了当务之急。
组员蔡峰:
遇到的困难:
小组:
①队内分工的协调问题有点大,没有成功地发挥每个人的能力特点,不只是发挥不出来,甚至忙的人特别忙,闲的人特别闲。
②总体战略部署存在失误,实战前一天晚上的调api过程没能重现,存在着没有预想到的麻烦
③由于队伍内核心代码成员的比赛,缺席了这次的编程实战,给我们带来了很多困扰
④整个团队呈现出工作效率低的状态,最具体就是表现在性价比的计算都存在着偏差,导致很多导出的餐厅并不是性价比高的餐厅。
个人:
①和分队队友没有沟通好,个人的技术优势没有得到很好的发挥。
②发现问题后提出解决问题的时间过迟,没有很好地串联起团队。
解决办法:
综上的所有困难,实际上都是我们团队和我本身事后总结出来的,问题实际上在当时并没有很好解决。团队的话,我认为应该在实战题目出来之前做好准备,设想出可能会遇到地困难,在出题之后的十分钟之内有效地讨论出分工再去付出实际工作。个人的话,问题还是比较大的,做好沟通工作和能力提高。
有趣的分析:
因为我是比较喜欢外出的人,在今天的编程实战中,我发现大众点评的一些数据不太符合我的认知。首先是在最受欢迎商圈这里我看到了茶亭世贸的人气值是高于宝龙万象的,实际上根据我一周几乎五六次外出的经验来看,宝龙万象的人气值在观测中是要高于茶亭世贸的,可能是因为茶亭世贸的消费水平比较符合大众的平均水平,并且在店铺数上是领先于其他商圈的,所以人气值在评测中会更高一些。
雷区频出。其次我在低端消费排行榜中看到了“赛百味”和“骨之味”,这里的出现让我很吃惊,因为这是快餐级别的餐饮,所以一定要做得棒才能够赢得好的口碑,我认为这两个餐厅是雷区,不建议大家根据这个排行榜去拔草。再举一个高端餐厅的例子,“埖绛日式花园餐厅”地理位置比较偏,是因为长期推出霸王餐的活动提高分数,再加上其独特的环境优势才赢得了榜单前列,但在我看来并不算是一个性价比高的餐厅。
实际上在榜单里看到许多优质餐厅,也看到许多人为“优质餐厅”,举个例子,宝龙的“肉祭”和“鸟匠”的确是优质餐厅,已经连续两年入选大众点评的必吃榜。然而像“韩一品”这样点评数少的五星餐厅很明显就是人为刷的,再加上美团的推荐费用是一年一万二,所以这样的店铺在缴纳费用后很容易就能够上分了,但是实际上只能够短期高分,因为时间还是能够证明它的优劣。
最后想说的是,实际上每个城市几乎都有必吃榜,这个榜单的风评还是十分不错的,至少在福州这两三年的必吃榜中的餐厅都具有很大的影响力。但是这个必吃榜也包括很大一部分的网红餐厅,因为其独特的风格赢得了必吃榜的排名。所以在一些地方必吃榜中的餐厅并不是当地人会常去的地方,如果你想吃到地道的当地风味,还是要根据自己的需求找当地人推荐,大众点评或许能给你很好的辅助参考价值,但是并不是你选择的绝对依据。
组员侯雅倩:
遇到的困难:
抓包过程一直出错
解决办法:
原来是没下载mysql,一直傻傻的以为有microsoftsql就好了,手动打数据了解一下...
组员王钟贤:
遇到的困难:
由于早上暂无成果而博客很多需要已经做好的页面截图,因而没事嘛可写的。
解决办法:
写能先写的,并学习新技术。
组员许煌标:
遇到的困难:
主要还是时间问题,我们团队两个大佬去比赛了,本身少了核心点之后力不从心,在效率上也出现了问题
解决办法:
最后还是选择了多做点时间,交个好歹能看的上去。
组员陈珊珊:
遇到的困难:
对爬虫这项技术不是很了解,都不会用它
解决办法:
在网站上查找一些资料,然后尝试着运行,试图弄懂...
组员吴珂雨:
遇到的困难:
没有困难,甚至在一段时间内无所事事,完成分内的事情以后看了看前端那边有没有需要帮忙的,但是能做的很少,帮忙做了几个按钮以后又不知道自己能做些什么了,他们也处于迷茫状态。
解决办法:
实际上问题并没有得到解决,反而是到最后为了完成任务无视了质量。
组员林晓锋:
遇到的困难:
这次现场编程只是负责搜一些资料,写一些数据,没有遇到太多的困难。
解决办法:
找不到合适的资料时会大家一起讨论,选出最符合题目要求的数据。
马后炮
庄锡荣:(小组任务完成的不太好,组长要要首先检讨。从后往前看,我们或许有更好的解决方案。可以采用更多人掌握的、更简易的html开发前端而不是使用pyqt然后把前端多个页面的任务堆到一两个人身上,导致工作量严重不均衡,很多人无事可做,最后由一两个人完成出来的效果也并不是很好。)如果再给我一次重开的机会,我会把“重担”提前多天明确地压到每一个人身上,而不是到最后由两三个人承担大部分的coding压力。
林鑫灿:如果自己能够自觉一点,早点接触api,那么我就不必在凌晨四点还在苦苦思索api的正确打开方式,现在就是后悔,十分后悔。
侯雅倩:如果能早点了解一下抓包过程,那么就不会现场学还学不会了。
许煌标:如果我们大哥和杰哥都在,那么我们会让你们知道什么是恐怖!
王钟贤:如果我能学习好python,那么我就能做更有价值的工作了!
陈珊珊:如果我能好好地利用时间早点去学习爬虫,那么我就帮上更多的忙了!
吴珂雨:(其实这次作业没有将大家的作用都发挥得很好,有的工作有些冗余,有的工作又缺人)如果能够更加合理的分工,进行足够的沟通,那么团队效率会增加许多。
蔡峰:如果今天早上大哥金杰都在的话,那么这次作业不过是一盘供他们开胃的餐前菜!
林晓锋:如果能学会更多的知识,有更好的技术水平,那么可以帮助队友更快地实现。
九、贡献比例
| 姓名 | 比例 | 完成工作 |
|---|---|---|
| 许煌标 | 15% | 前端编写 |
| 林鑫灿 | 15% | 算法编写 |
| 庄锡荣 | 15% | 算法编写 |
| 陈珊珊 | 10% | 信息整理和博客撰写 |
| 吴珂雨 | 9% | 素材整理和前端设计 |
| 蔡峰 | 9% | 前端设计 |
| 林晓锋 | 8% | 素材整理 |
| 侯雅倩 | 8% | 素材整理 |
| 王钟贤 | 7% | 博客撰写 |
| 曾世缘 | 2% | 精神支持 |
| 陈金杰 | 2% | 精神支持 |
十、PSP表格
| PSP2.1 | Personal Software Process Stages |
预估耗时 (分钟) |
实际耗时 (分钟) |
|---|---|---|---|
| Planning | 计划 | 360 | 340 |
| · Estimate | · 估计这个任务 需要多少时间 |
360 | 340 |
| Development | 开发 | 325 | 490 |
| · Analysis | · 需求分析 (包括学习新技术) |
180 | 300 |
| · Design Spec | · 生成设计文档 | 10 | 20 |
| · Design Review | · 设计复审 | 10 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发 制定合适的规范) |
15 | 20 |
| · Design | · 具体设计 | 10 | 15 |
| · Coding | · 具体编码 | 60 | 70 |
| · Code Review | · 代码复审 | 10 | 15 |
| · Test | · 测试(自我测试, 修改代码,提交修改) |
30 | 35 |
| Reporting | 报告 | 15 | 25 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 | 15 |
| · 合计 | 340 | 415 |
十一、学习进度表
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 14 | 14 | 学习了相关的一些语言 |
| 2 | 800 | 800 | 30 | 44 | 学会了异常处理、Json格式等以前没有遇到过的问题 |
| 3 | 0 | 800 | 18 | 62 | 学会了使用Axure设计界面 |
| 4 | 0 | 800 | 53 | 115 | 学习html、css、js的使用 |
| 5 | 2000+ | 2800+ | 81 | 196 | 真正进行前端的制作 |
| 6 | 1000+ | 3800+ | 20 | 216 | 对初步做好的前端界面进行修改,并且学会了一些有关github的操作 |
| 7 | 0 | 3800+ | 10 | 226 | 对团队选题有了更深入的了解 |
| 8 | 100+ | 3900+ | 10 | 236 | 尝试地学习爬虫,但还是很迷 |
| … | … | … | … | … | … |