1. XPath (XML Path Language) XML路径语言
2. XPath 常用规则:
nodename 选取此节点的所有子节点
/ 从当前结点选取直接子节点
// 从当前结点选取子孙节点
. 选取当前结点
.. 选取当前结点的父节点
@ 选取属性
3. 实例
1 from lxml import etree 2 3 text = ''' 4 <div> 5 <ul> 6 <li class="item-0"><a href="link1.html">first item</a></li> 7 <li class="item-1"><a href="link2.html">second item</a></li> 8 <li class="item-inactive"><a href="link3.html">third item</a></li> 9 <li class="item-1"><a href="link4.html">fourth item</a></li> 10 <li class="item-0"><a href="link5.html">fifth item</a> 11 </ul> 12 </div> 13 ''' 14 html = etree.HTML(text) # 初始化,构造XPath对象 15 # 自动修正html代码,最后一个<li>没有闭合,tostring()方法补全html代码,返回结果是bytes类型 16 result = etree.tostring(html) 17 print(result.decode('utf-8'))
也可以读取文件来进行解析
1 from lxml import etree 2 3 html = etree.parse(r'C:UsersAdministratorDesktop est.txt', etree.HTMLParser()) 4 result = etree.tostring(html) 5 print(result.decode('utf-8'))
4. 使用//开头的XPath规则来选取符合要求的节点
from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">爱我中华</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> ''' '''匹配节点''' html = etree.HTML(text) result1 = html.xpath('//*') # 使用*匹配所有节点 print(result1) result2 = html.xpath('//li') # 获取所有的li节点 print(result2) print(result2[0]) result3 = html.xpath('//li/a') # 获取所有li节点的直接a子节点 print(result3) # 首先选中href属性为link3.html的a节点,然后再获取其父亲节点,在获取其class属性的值 # result4 为['item-inactive'],这是个只有一个元素的列表 result4 = html.xpath('//a[@href="link3.html"]/../@class') print(result4[0]) # 同时, 也可以通过parent::来获取父亲节点 如: result5 = html.xpath('//a[@href="link3.html"]/parent::*/@class') '''属性匹配 (选取节点时,可以用@符号进行属性过滤)''' # 匹配属性class="item-inactive"的li节点 result6 = html.xpath('//li[@class="item-inactive"]') print(result6) '''文本获取 (使用XPath中的text()方法获取节点中的文本)''' result7 = html.xpath('//li[@class="item-inactive"]/a[@href="link3.html"]/text()') print(result7) # 打印出 ['爱我中华'] 列表 '''属性获取 使用@来获取属性''' # 匹配属性href="link3.html"的a节点的父亲节点的class属性 result8 = html.xpath('//a[@href="link3.html"]/../@class') print(result8) # 打印['item-inactive'] '''属性多值匹配''' html_test = '''<li class="li item-inactive"><a href="link3.html">爱我中华</a></li>''' # 这里li标签class属性有两个值, 如果按照上边的属性匹配 是匹配不到的,就要用到contains()函数 html_test = etree.HTML(html_test) # 通过contains方法,第一个参数穿属性名,第二个传属性值中的任意一个,都可以匹配到 result9 = html_test.xpath('//li[contains(@class, "li")]/a/text()') print(result9) '''多属性匹配 (根据多个属性来确定一个节点)''' html_test2 = '''<li class="li item-inactive" name="item"><a href="link3.html">Hello World</a></li>''' # 这里li标签class属性有两个值, 如果按照上边的属性匹配 是匹配不到的,就要用到contains()函数 html_test = etree.HTML(html_test2) # 通过contains方法,第一个参数穿属性名,第二个传属性值中的任意一个,都可以匹配到 result10 = html_test.xpath('//li[contains(@class, li) and @name="item"]/a[@href="link3.html"]/text()') print(result10) # 打印['Hello World']
5. XPath 运算符
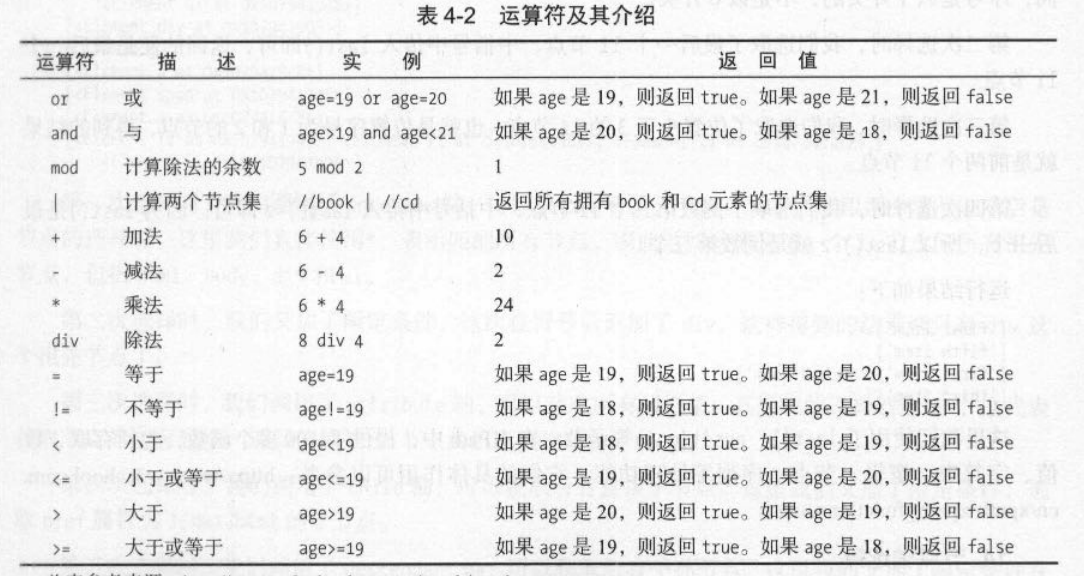
5. 按序选择 (同时匹配了多个节点时但又只想要其中一个节点时)
from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">爱我中华</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> ''' '''匹配节点后按序选择''' html = etree.HTML(text) result1 = html.xpath('//li[1]/a/text()') # 选取匹配到的li节点的第一个 print(result1) result2 = html.xpath('//li[last()]/a/text()') # 选取匹配到的li节点的最后一个 print(result2) result3 = html.xpath('//li[position()<3]/a/text()') # 选取匹配到的所有li节点中位置小于3,也就时第1,2个 print(result3) result4 = html.xpath('//li[last()-2]/a/text()') # 选取匹配到的li节点的倒数第三个 print(result4) '''节点轴选择''' html = etree.HTML(text) result5 = html.xpath('//li[1]/ancestor::*') # 选取匹配到的li节点的第一个的所有祖先节点 print(result5) result6 = html.xpath('//li[1]/attribute::*') # 选取匹配到的li节点的所有属性值 print(result6) result7 = html.xpath('//li[1]/child::a') # 选取匹配到的li节点的所有子节点 print(result7) result8 = html.xpath('//li[1]/descendant::a') # 选取匹配到的li节点的所有子孙节点 print(result8) result9 = html.xpath('//li[1]/following::*') # 选取获取到的当前结点后的所有节点 print(result9) result10 = html.xpath('//li[1]/following-sibling::*') # 选取获取到的当前结点之后的所有同级节点 print(result10)